
Practice Free UIPATH-ADPV1 Exam Online Questions
In an RPA Testing project, you created the mock "MySequencemock" for the file "MySequence". You have to update "MySequence" and add a Log Message activity and a Verify Expression activity.
What will happen to "MySequencemock" file when you save the project, assuming that the file is closed?
- A . Only the Verify Expression activity will be added to the mock file.
- B . The changes made in "MySequence" workflow file are applied to the mock file.
- C . Only the Log Message activity will be added to the mock file.
- D . The changes made in "MySequence" workflow file are not applied to the mock file.
B
Explanation:
A mock file is a copy of a workflow file that is used for testing purposes, where some activities are replaced by mock activities that simulate the expected behavior1. A mock file can be created by selecting Mock workflow under test in the Create Test Case window2. The mock file is stored in the Project > Mocks folder, and it has the same name as the original workflow file, with the suffix “_mock” added2.
For example, if the original workflow file is named “MySequence.xaml”, the mock file will be named “MySequence_mock.xaml”.
When a mock file is created, the changes made in the original workflow file are automatically applied to the mock file when the project is saved2. This means that any new activities or modifications in the original workflow file are reflected in the mock file, except for the activities that are surrounded by mock activities2. The mock activities are not affected by the changes in the original workflow file, and they can only be edited within the mock file2.
Therefore, if you update “MySequence” and add a Log Message activity and a Verify Expression activity, and then save the project, the changes will be applied to the mock file, assuming that the file is closed. This means that the mock file will also have the Log Message activity and the Verify Expression activity added, unless they are inside a mock activity
"Process A" is scheduled to run at 2:00 PM using a time trigger with the Schedule ending of Job execution feature configured to stop the job after 20 minutes.
Assuming that the robots are busy and "Process A" is queued until 2:05 PM. at what time will "Process A* be stopped?
- A . 2:20 PM
- B . 2:25 PM
- C . 2:05 PM
- D . 2:28 PM
B
Explanation:
"Process A":
The process is scheduled to run at 2:00 PM, but due to busy robots, it starts at 2:05 PM.
The Schedule ending of Job execution feature is configured to stop the job after 20 minutes.
Therefore, "Process A" will be stopped 20 minutes after it started, which is at 2:25 PM.
When configuring the Max # of retries for the queue in Orchestrator to "1" for your process, and the queue has 5 transaction items. At runtime, the first transaction item throws a Business Rule Exception.
How does the process proceed?
- A . Transaction is retried multiple times until processed successfully.
- B . Transaction is not retried but remaining transactions continue processing.
- C . Transaction is retried only one time.
- D . Transaction is not retried and the process stops.
B
Explanation:
A Business Rule Exception is a type of exception that indicates that the data or the input required for the automation process is incomplete or invalid1.
For example, a Business Rule Exception can occur when a phone number is missing a digit, or when a mandatory field is left blank1. A Business Rule Exception is usually thrown by the developer using the Throw activity, and it is handled by the Set Transaction Status activity, which sets the status of the transaction item to Failed and adds the exception details to the queue item2. By default, Orchestrator does not retry transactions that are failed due to Business Rule Exceptions, regardless of the Max # of retries setting for the queue3. This is because retrying the transaction does not solve the issue, and there are other better courses of action, such as notifying the human user of the error1. Therefore, if the first transaction item throws a Business Rule Exception, the transaction is not retried, but the remaining transactions continue processing, as long as they do not encounter any other exceptions.
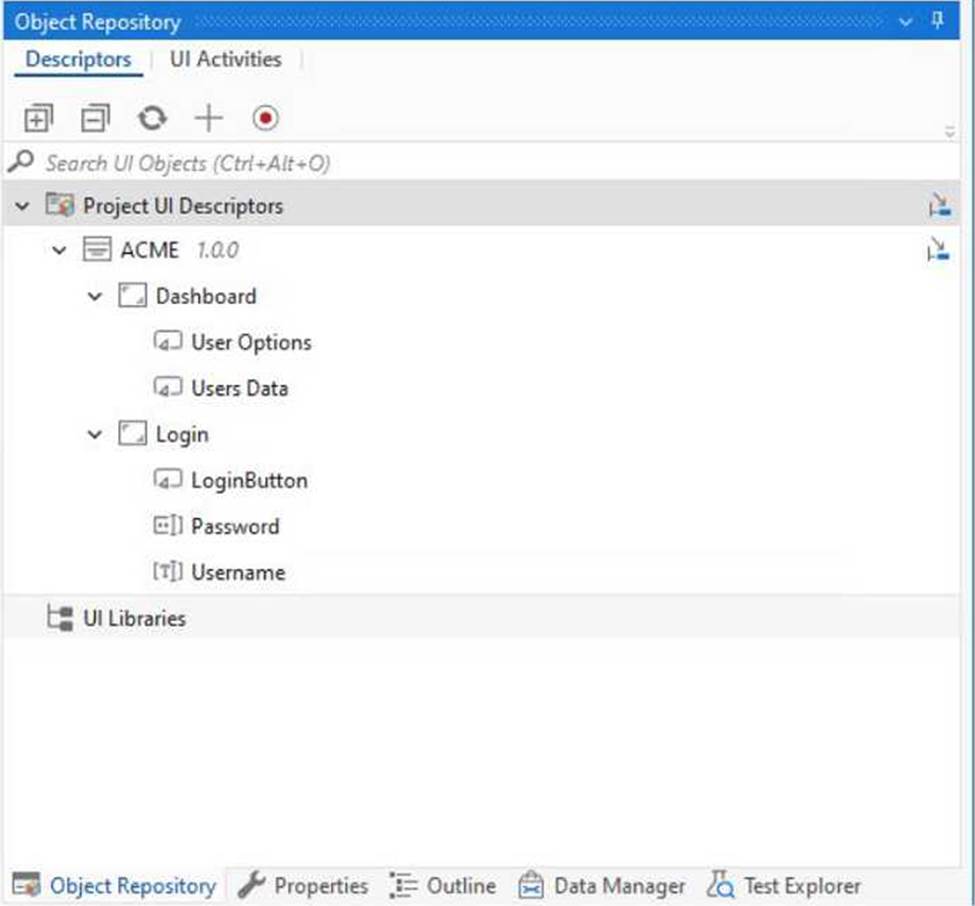
Which of the following options is correct regarding the below Object Repository tree structure?
- A . One Screen
Two Applications
Two UI Elements - B . One Screen
Two Applications
Five UI Elements - C . One Application
Two Screens
Five UI Elements - D . One Application
Two UI Elements
Five Screens
C
Explanation:
Based on the provided screenshot of the Object Repository tree structure in UiPath, the correct hierarchy and count of elements are as follows:
There is one Application, which is "ACME 1.0.0".
Within this application, there are two Screens: "Dashboard" and "Login".
Under the "Dashboard" screen, there are three UI Elements: "User Options", "Users Data".
Under the "Login" screen, there are two UI Elements: "LoginButton", "Password", "Username".
Therefore, the correct option regarding the tree structure displayed would be:
C. One Application Two Screens Five UI Elements
This option correctly identifies one application (ACME 1.0.0), two screens (Dashboard, Login), and five UI elements (User Options, Users Data, LoginButton, Password, Username).
What functionality does the Step Out action offer when a developer Is reviewing a process during debugging, as shown in the exhibit?

- A . Re-executes the activity which threw an exception.
- B . Executes only one activity at a time and then pauses the execution
- C . Steps out and stops current execution.
- D . Executes activities in the current container and then pauses the execution
D
Explanation:
The "Step Out" action in UiPath Studio’s debugging tools allows the developer to finish executing the current container (such as a sequence, loop, or workflow) and returns to the next higher level in the call stack. Essentially, it continues the execution of activities within the current container without stepping into any invoked workflows or activities.
The correct functionality provided by the "Step Out" action is: D. Executes activities in the current container and then pauses the execution after stepping out to the next higher level in the call stack.
A developer examines a workflow in which filenames are stored within a collection. The collection is initialized with a single filename.
When adding a new filename to the collection, which collection variable type will cause an error?
- A . System.Collections.Generic.Dictionary
- B . System.Collections.Generic.List
- C . System.Array
- D . System.Data.DataTable
C
Explanation:
The collection variable type that will cause an error when adding a new filename to the collection is System.Array. This is because System.Array is a fixed-size collection that cannot be resized or modified once it is initialized. Therefore, if the collection is initialized with a single filename, it cannot accommodate any more filenames. To add a new filename to the collection, the developer should use a dynamic collection type, such as System.Collections.Generic.List or System.Data.DataTable, that can grow or shrink as needed. Alternatively, the developer can use System.Collections.Generic.Dictionary if the filenames need to be associated with some keys or values.
Reference: [Array Class], [Collection Classes]
Which features does the Connector Builder for Integration Service support?
- A . REST and SOAP APIs with JSON payload, various authentication types including OAuth 2.0 and Personal Access Token, building a connector from a Swagger definition only.
- B . REST APIs with JSON payload. OAuth 2.0 and Basic authentication types, building a connector from a Postman collection only.
- C . REST APIs with JSON payload, various authentication types including OAuth 2.0 and API Key, building a connector from an API definition or from scratch.
- D . REST and SOAP APIs with JSON and XML payloads. OAuth 2.0 authentication only, building a connector from an API definition only.
C
Explanation:
The Connector Builder for Integration Service is a feature that enables the user to quickly add custom connectors to the tenant catalog in a no-code environment. The custom connectors can wrap any RESTful API and provide rich and scalable functionality on top of the original API1.
The Connector Builder supports the following features:
REST APIs with JSON payload: The Connector Builder can connect to external systems that expose their API documentation as REST-compliant and both accept and return JSON2.
Various authentication types including OAuth 2.0 and API Key: The Connector Builder supports different types of authentication methods for the API calls, such as OAuth 2.0, Basic, Personal Access Token (PAT), API Key, etc3.
Building a connector from an API definition or from scratch: The Connector Builder allows the user to start building a connector from an existing API definition, such as a Swagger file, a Postman collection, or a URL, or from scratch by manually adding the API resources and methods4.
Option C is the correct answer, as it lists the features that the Connector Builder supports as defined in the documentation1. Option A is incorrect, because the Connector Builder does not support SOAP APIs or XML payloads, and it can build a connector from other sources besides a Swagger definition. Option B is incorrect, because the Connector Builder supports other authentication types besides OAuth 2.0 and Basic, and it can build a connector from other sources besides a Postman collection. Option D is incorrect, because the Connector Builder does not support SOAP APIs or XML payloads, and it supports other authentication types besides OAuth 2.0.
Reference: 1: Integration Service – About Connector Builder 2: Integration Service – Building your first
connector 3: Integration Service – Authentication types 4: Integration Service – Create a connector
from an API definition: [Integration Service – Create a connector from scratch]
What is the purpose of credential stores in UiPath Orchestrator?
- A . To store non-sensitive data and configuration settings for UiPath Studio projects.
- B . To store Orchestrator event loos and related data for auditing purposes.
- C . To securely store sensitive data such as Robot credentials and Credential Assets for use in automation processes.
- D . To serve as a centralized location for storing pre-built automation workflows and processes.
C
Explanation:
The purpose of credential stores in UiPath Orchestrator is to securely store sensitive data such as Robot credentials and Credential Assets for use in automation processes. Credential stores are external services that provide encryption and protection for sensitive data. Orchestrator can integrate with various credential stores, such as CyberArk, Azure Key Vault, and HashiCorp Vault, and use them to store and retrieve the credentials for the Robots and the Credential Assets. Credential Assets are global variables that can store passwords, usernames, API keys, and other confidential information. By using credential stores, the developer can ensure that the sensitive data is not exposed or compromised, and that the automation processes can access the data securely and efficiently.
Reference: [Credential Stores], [Credential Assets]
Arguments and Variables Information log entry – show values of the variables and arguments that are used.
- A . Verbose
- B . Trace
- C . Critical
- D . Information
A
Explanation:
The Verbose logging level includes the following information by default:
Execution Started log entry – generated every time a process is started.
Execution Ended log entry – generated every time a process is finalized.
Transaction Started log entry – generated every time a transaction item is obtained by the robot from Orchestrator.
Transaction Ended log entry – generated every time the robot sets the transaction status to either Success or Failed.
Activity Information log entry – generated every time an activity is started, faulted or finished inside a workflow.
Arguments and Variables Information log entry – show values of the variables and arguments that are used.
The Verbose logging level is the most detailed one and it is useful for debugging purposes, as it provides a lot of information about the execution flow and the data used by the robot. However, it also generates a lot of log entries, which can affect the performance and the storage space of the robot and Orchestrator.
Reference: [Logging Levels]
Arguments and Variables Information log entry – show values of the variables and arguments that are used.
- A . Verbose
- B . Trace
- C . Critical
- D . Information
A
Explanation:
The Verbose logging level includes the following information by default:
Execution Started log entry – generated every time a process is started.
Execution Ended log entry – generated every time a process is finalized.
Transaction Started log entry – generated every time a transaction item is obtained by the robot from Orchestrator.
Transaction Ended log entry – generated every time the robot sets the transaction status to either Success or Failed.
Activity Information log entry – generated every time an activity is started, faulted or finished inside a workflow.
Arguments and Variables Information log entry – show values of the variables and arguments that are used.
The Verbose logging level is the most detailed one and it is useful for debugging purposes, as it provides a lot of information about the execution flow and the data used by the robot. However, it also generates a lot of log entries, which can affect the performance and the storage space of the robot and Orchestrator.
Reference: [Logging Levels]