Practice Free MuleSoft Integration Architect I Exam Online Questions
A mule application must periodically process a large dataset which varies from 6 GB lo 8 GB from a back-end database and write transform data lo an FTPS server using a properly configured bad job scope.
The performance requirements of an application are approved to run in the cloud hub 0.2 vCore with 8 GB storage capacity and currency requirements are met.
How can the high rate of records be effectively managed in this application?
- A . Use streaming with a file storage repeatable strategy for reading records from the database and batch aggregator with streaming to write to FTPS
- B . Use streaming with an in-memory reputable store strategy for reading records from the database and batch aggregator with streaming to write to FTPS
- C . Use streaming with a file store repeatable strategy for reading records from the database and batch aggregator with an optimal size
- D . Use streaming with a file store repeatable strategy reading records from the database and batch aggregator without any required configuration
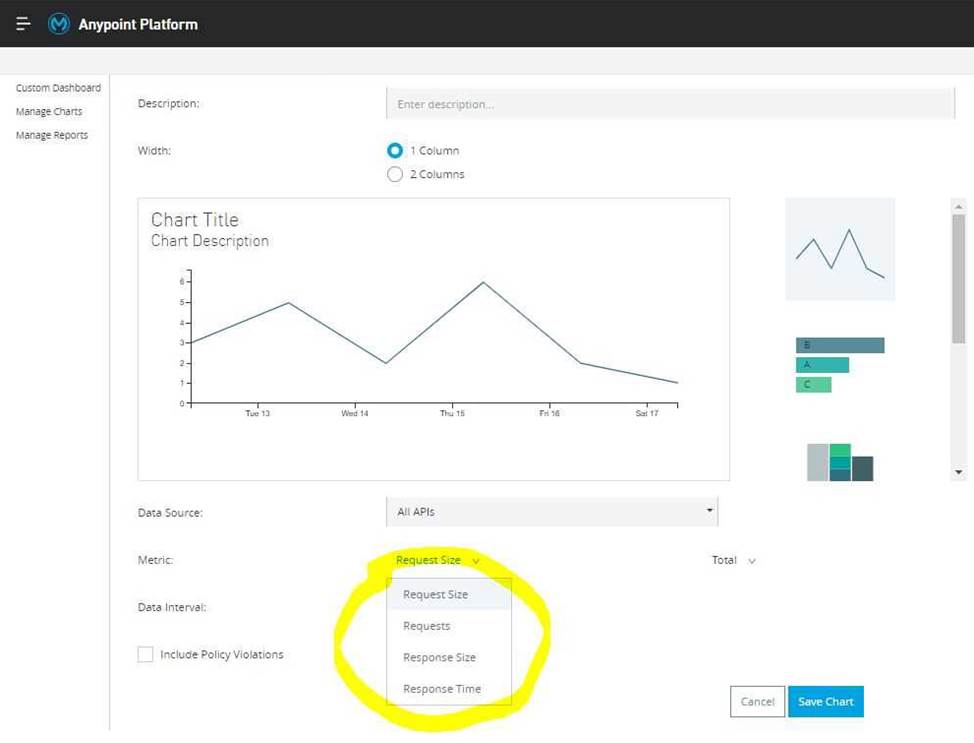
What metrics about API invocations are available for visualization in custom charts using Anypoint Analytics?
- A . Request size, request HTTP verbs, response time
- B . Request size, number of requests, JDBC Select operation result set size
- C . Request size, number of requests, response size, response time
- D . Request size, number of requests, JDBC Select operation response time
C
Explanation:
Correct answer is Request size, number of requests, response size, response time Analytics API Analytics can provide insight into how your APIs are being used and how they are performing. From API Manager, you can access the Analytics dashboard, create a custom dashboard, create and manage charts, and create reports. From API Manager, you can get following types of analytics: – API viewing analytics – API events analytics – Charted metrics in API Manager It can be accessed using: http://anypoint.mulesoft.com/analytics
API Analytics provides a summary in chart form of requests, top apps, and latency for a particular duration.
The custom dashboard in Anypoint Analytics contains a set of charts for a single API or for all APIs Each chart displays various API characteristics
C Requests size: Line chart representing size of requests in KBs
C Requests: Line chart representing number of requests over a period
C Response size: Line chart representing size of response in KBs
C Response time: Line chart representing response time in ms
* To check this, You can go to API Manager > Analytics > Custom Dashboard > Edit Dashboard > Create Chart > Metric
Reference: https://docs.mulesoft.com/monitoring/api-analytics-dashboard
Additional Information:
The default dashboard contains a set of charts
C Requests by date: Line chart representing number of requests
C Requests by location: Map chart showing the number of requests for each country of origin
C Requests by application: Bar chart showing the number of requests from each of the top five registered applications
C Requests by platform: Ring chart showing the number of requests broken down by platform
A payment processing company has implemented a Payment Processing API Mule application to process credit card and debit card transactions, Because the Payment Processing API handles highly sensitive information, the payment processing company requires that data must be encrypted both In-transit and at-rest.
To meet these security requirements, consumers of the Payment Processing API must create request message payloads in a JSON format specified by the API, and the message payload values must be encrypted.
How can the Payment Processing API validate requests received from API consumers?
- A . A Transport Layer Security (TLS) – Inbound policy can be applied in API Manager to decrypt the message payload and the Mule application implementation can then use the JSON Validation module to validate the JSON data
- B . The Mule application implementation can use the APIkit module to decrypt and then validate the JSON data
- C . The Mule application implementation can use the Validation module to decrypt and then validate the JSON data
- D . The Mule application implementation can use DataWeave to decrypt the message payload and then use the JSON Scheme Validation module to validate the JSON data
What comparison is true about a CloudHub Dedicated Load Balancer (DLB) vs. the CloudHub Shared Load Balancer (SLB)?
- A . Only a DLB allows the configuration of a custom TLS server certificate
- B . Only the SLB can forward HTTP traffic to the VPC-internal ports of the CloudHub workers
- C . Both a DLB and the SLB allow the configuration of access control via IP whitelists
- D . Both a DLB and the SLB implement load balancing by sending HTTP requests to workers with the lowest workloads
A
Explanation:
* Shared load balancers don’t allow you to configure custom SSL certificates or proxy rules
* Dedicated Load Balancer are optional but you need to purchase them additionally if needed.
* TLS is a cryptographic protocol that provides communications security for your Mule app. TLS offers many different ways of exchanging keys for authentication, encrypting data, and guaranteeing message integrity.
* The CloudHub Shared Load Balancer terminates TLS connections and uses its own server-side certificate.
* Only a DLB allows the configuration of a custom TLS server certificate
* DLB enables you to define SSL configurations to provide custom certificates and optionally enforce two-way SSL client authentication.
* To use a DLB in your environment, you must first create an Anypoint VPC. Because you can associate multiple environments with the same Anypoint VPC, you can use the same dedicated load balancer for your different environments.
* MuleSoft
Reference: https://docs.mulesoft.com/runtime-manager/dedicated-load-balancer-tutorial
Additional Info on SLB Vs DLB:

An API client is implemented as a Mule application that includes an HTTP Request operation using a default configuration. The HTTP Request operation invokes an external API that follows standard HTTP status code conventions, which causes the HTTP Request operation to return a 4xx status code.
What is a possible cause of this status code response?
- A . An error occurred inside the external API implementation when processing the HTTP request that was received from the outbound HTTP Request operation of the Mule application
- B . The external API reported that the API implementation has moved to a different external endpoint
- C . The HTTP response cannot be interpreted by the HTTP Request operation of the Mule application after it was received from the external API
- D . The external API reported an error with the HTTP request that was received from the outbound HTTP Request operation of the Mule application
D
Explanation:
Correct choice is: "The external API reported an error with the HTTP request that was received from the outbound HTTP Request operation of the Mule application"
Understanding HTTP 4XX Client Error Response Codes: A 4XX Error is an error that arises in cases where there is a problem with the user’s request, and not with the server.
Such cases usually arise when a user’s access to a webpage is restricted, the user misspells the URL, or when a webpage is nonexistent or removed from the public’s view.
In short, it is an error that occurs because of a mismatch between what a user is trying to access, and its availability to the user ― either because the user does not have the right to access it, or because what the user is trying to access simply does not exist. Some of the examples of 4XX errors are 400 Bad Request The server could not understand the request due to invalid syntax. 401
Unauthorized Although the HTTP standard specifies "unauthorized", semantically this response means "unauthenticated". That is, the client must authenticate itself to get the requested response. 403 Forbidden The client does not have access rights to the content; that is, it is unauthorized, so the server is refusing to give the requested resource. Unlike 401, the client’s identity is known to the server. 404 Not Found The server can not find the requested resource. In the browser, this means the URL is not recognized. In an API, this can also mean that the endpoint is valid but the resource itself does not exist. Servers may also send this response instead of 403 to hide the existence of a resource from an unauthorized client. This response code is probably the most famous one due to its frequent occurrence on the web. 405 Method Not Allowed The request method is known by the server but has been disabled and cannot be used. For example, an API may forbid DELETE-ing a resource. The two mandatory methods, GET and HEAD, must never be disabled and should not return this error code. 406 Not Acceptable This response is sent when the web server, after performing server-driven content negotiation, doesn’t find any content that conforms to the criteria given by the user agent. The external API reported that the API implementation has moved to a different external endpoint cannot be the correct answer as in this situation 301 Moved Permanently The URL of the requested resource has been changed permanently. The new URL is given in the response.
In Lay man’s
term the scenario would be: API CLIENT ―> MuleSoft API – HTTP request “Hey, API.. process this” ―> External API API CLIENT <C MuleSoft API – http response "I’m sorry Client.. something is wrong with that request" <C (4XX) External API
A banking company is developing a new set of APIs for its online business. One of the critical API’s is a master lookup API which is a system API. This master lookup API uses persistent object store. This API will be used by all other APIs to provide master lookup data.
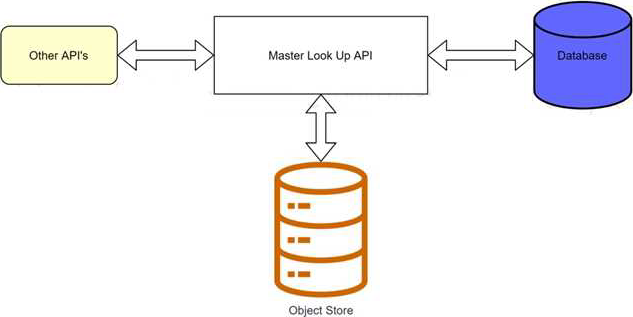
Master lookup API is deployed on two cloudhub workers of 0.1 vCore each because there is a lot of master data to be cached. Master lookup data is stored as a key value pair. The cache gets refreshed if they key is not found in the cache.
Doing performance testing it was observed that the Master lookup API has a higher response time due to database queries execution to fetch the master lookup data.
Due to this performance issue, go-live of the online business is on hold which could cause potential financial loss to Bank.
As an integration architect, which of the below option you would suggest to resolve performance issue?
- A . Implement HTTP caching policy for all GET endpoints for the master lookup API and implement locking to synchronize access to object store
- B . Upgrade vCore size from 0.1 vCore to 0,2 vCore
- C . Implement HTTP caching policy for all GET endpoints for master lookup API
- D . Add an additional Cloudhub worker to provide additional capacity
A REST API is being designed to implement a Mule application.
What standard interface definition language can be used to define REST APIs?
- A . Web Service Definition Language (WSDL)
- B . OpenAPI Specification (OAS)
- C . YAML
- D . AsyncAPI Specification
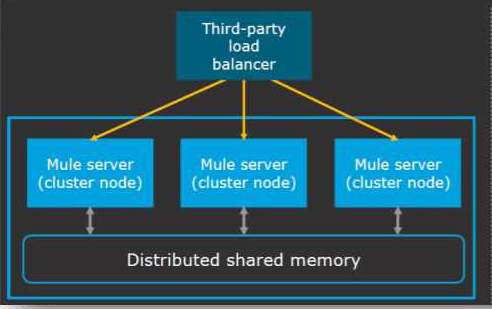
Additional nodes are being added to an existing customer-hosted Mule runtime cluster to improve performance. Mule applications deployed to this cluster are invoked by API clients through a load balancer.
What is also required to carry out this change?
- A . A new load balancer must be provisioned to allow traffic to the new nodes in a round-robin fashion
- B . External monitoring tools or log aggregators must be configured to recognize the new nodes
- C . API implementations using an object store must be adjusted to recognize the new nodes and persist to them
- D . New firewall rules must be configured to accommodate communication between API clients and the new nodes
B
Explanation:
* Clustering is a group of servers or mule runtime which acts as a single unit.
* Mulesoft Enterprise Edition supports scalable clustering to provide high availability for the Mulesoft application.
* In simple terms, virtual servers composed of multiple nodes and they communicate and share information through a distributed shared memory grid.
* By default, Mulesoft ensures the High availability of applications if clustering implemented.
* Let’s consider the scenario one of the nodes in cluster crashed or goes down and under maintenance. In such cases, Mulesoft will ensure that requests are processed by other nodes in the cluster. Mulesoft clustering also ensures that the request is load balanced between all the nodes in a cluster.
* Clustering is only supported by on-premise Mule runtime and it is not supported in Cloudhub. Correct answer is External monitoring tools or log aggregators must be configured to recognize the new nodes
* Rest of the options are automatically taken care of when a new node is added in cluster.
Reference: https://docs.mulesoft.com/runtime-manager/cluster-about
An insurance company is using a CIoudHub runtime plane. As a part of requirement, email alert should be sent to internal operations team every time of policy applied to an API instance is deleted.
As an integration architect suggest on how this requirement be met?
- A . Use audit logs in Anypoint platform to detect a policy deletion and configure the Audit logs alert feature to send an email to the operations team
- B . Use Anypoint monitoring to configure an alert that sends an email to the operations team every time a policy is deleted in API manager
- C . Create a custom connector to be triggered every time of policy is deleted in API manager
- D . Implement a new application that uses the Audit log REST API to
detect the policy deletion and send an email to operations team the SMTP connector
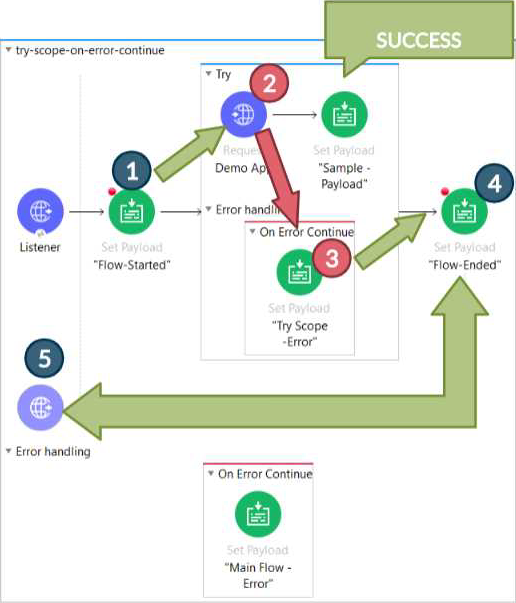
An integration Mute application consumes and processes a list of rows from a CSV file. Each row must be read from the CSV file, validated, and the row data sent to a JMS queue, in the exact order as in the CSV file.
If any processing step for a row falls, then a log entry must be written for that row, but processing of other rows must not be affected.
What combination of Mute components is most idiomatic (used according to their intended purpose) when Implementing the above requirements?
- A . Scatter-Gather component On Error Continue scope
- B . VM connector first Successful scope On Error Propagate scope
- C . For Each scope On Error Continue scope
- D . Async scope On Error Propagate scope
C
Explanation:
* On Error Propagate halts execution and sends error to the client. In this scenario it’s mentioned that "processing of other rows must not be affected" so Option B and C are ruled out.
* Scatter gather is used to club multiple responses together before processing. In this scenario, we need sequential processing. So option A is out of choice.
* Correct answer is For Each scope & On Error Continue scope Below requirement can be fulfilled in the below way
1) Using For Each scope, which will send each row from csv file sequentially. each row needs to be sent sequentially as requirement is to send the message in exactly the same way as it is mentioned in the csv file
2) Also other part of requirement is if any processing step for a row fails then it should log an error but should not affect other record processing . This can be achieved using On error Continue scope on these set of activities. so that error will not halt the processing. Also logger needs to be added in error handling section so that it can be logged.
* Attaching diagram for reference. Here it’s try scope, but similar would be the case with For Each loop.