
Practice Free MuleSoft Integration Architect I Exam Online Questions
An XA transaction Is being configured that involves a JMS connector listening for Incoming JMS messages.
What is the meaning of the timeout attribute of the XA transaction, and what happens after the timeout expires?
- A . The time that is allowed to pass between committing the transaction and the completion of the Mule flow After the timeout, flow processing triggers an error
- B . The time that Is allowed to pass between receiving JMS messages on the same JMS connection After the timeout, a new JMS connection Is established
- C . The time that Is allowed to pass without the transaction being ended explicitly After the timeout, the transaction Is forcefully rolled-back
- D . The time that Is allowed to pass for state JMS consumer threads to be destroyed After the timeout, a new JMS consumer thread is created
C
Explanation:
* Setting a transaction timeout for the Bitronix transaction manager
● Set the transaction timeout either
C In wrapper.conf
C In CloudHub in the Properties tab of the Mule application deployment
● The default is 60 secs. It is defined as
mule.bitronix.transactiontimeout = 120
* This property defines the timeout for each transaction created for this manager.
If the transaction has not terminated before the timeout expires it will be automatically rolled
back.
———————————————————————————————————————
Additional Info around Transaction Management:
Bitronix is available as the XA transaction manager for Mule applications
● To use Bitronix, declare it as a global configuration element in the Mule application <bti:transaction-manager />
● Each Mule runtime can have only one instance of a Bitronix transaction manager, which is shared by all Mule applications
● For customer-hosted deployments, define the XA transaction manager in a Mule domain
C Then share this global element among all Mule applications in the Mule runtime

An integration team uses Anypoint Platform and follows MuleSoft’s recommended approach to full lifecycle API development.
Which step should the team’s API designer take before the API developers implement the AP! Specification?
- A . Generate test cases using MUnit so the API developers can observe the results of running the API
- B . Use the scaffolding capability of Anypoint Studio to create an API portal based on the API specification
- C . Publish the API specification to Exchange and solicit feedback from the API’s consumers
- D . Use API Manager to version the API specification
49 of A popular retailer is designing a public API for its numerous business partners. Each business partner will invoke the API at the URL 58. https://api.acme.com/partnefs/vl. The API implementation is estimated to require deployment to 5 CloudHub workers.
The retailer has obtained a public X.509 certificate for the name apl.acme.com, signed by a reputable CA, to be used as the server certificate.
Where and how should the X.509 certificate and Mule applications be used to configure load balancing among the 5 CloudHub workers, and what DNS entries should be configured in order for the retailer to support its numerous business partners?
- A . Add the X.509 certificate to the Mule application’s deployable archive, then configure a CloudHub Dedicated Load Balancer (DLB) for each of the Mule application’s CloudHub workers Create a CNAME for api.acme.com pointing to the DLB’s A record
- B . Add the X.509 certificate to the CloudHub Shared Load Balancer (SLB), not to the Mule application Create a CNAME for api.acme.com pointing to the SLB’s A record
- C . Add the X.509 certificate to a CloudHub Dedicated Load Balancer (DLB), not to the Mule application
Create a CNAME for api.acme.com pointing to the DLB’s A record - D . Add the x.509 certificate to the Mule application’s deployable archive, then configure the CloudHub Shared Load Balancer (SLB)
for each of the Mule application’s CloudHub workers
Create a CNAME for api.acme.com pointing to the SLB’s A record
C
Explanation:
* An X.509 certificate is a vital safeguard against malicious network impersonators. Without x.509 server authentication, man-in-the-middle attacks can be initiated by malicious access points, compromised routers, etc.
* X.509 is most used for SSL/TLS connections to ensure that the client (e.g., a web browser) is not fooled by a malicious impersonator pretending to be a known, trustworthy website.
* Coming to the question, we can not use SLB here as SLB does not allow to define vanity domain names. * Hence we need to use DLB and add certificate in there
Hence correct answer is Add the X 509 certificate to the cloudhub Dedicated Load Balancer (DLB), not the Mule application. Create the CNAME for api.acme.com pointing to the DLB’s record
Refer to the exhibit.
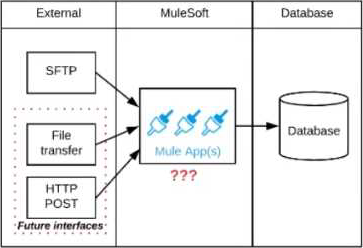
A business process involves the receipt of a file from an external vendor over SFTP. The file needs to be parsed and its content processed, validated, and ultimately persisted to a database. The delivery mechanism is expected to change in the future as more vendors send similar files using other mechanisms such as file transfer or HTTP POST.
What is the most effective way to design for these requirements in order to minimize the impact of future change?
- A . Use a MuleSoft Scatter-Gather and a MuleSoft Batch Job to handle the different files coming from different sources
- B . Create a Process API to receive the file and process it using a MuleSoft Batch Job while delegating the data save process to a System API
- C . Create an API that receives the file and invokes a Process API with the data contained In the file, then have the Process API process the data using a MuleSoft Batch Job and other System APIs as needed
- D . Use a composite data source so files can be retrieved from various sources and delivered to a MuleSoft Batch Job for processing
C
Explanation:
* Scatter-Gather is used for parallel processing, to improve performance. In this scenario, input files are coming from different vendors so mostly at different times. Goal here is to minimize the impact of future change. So scatter Gather is not the correct choice.
* If we use 1 API to receive all files from different Vendors, any new vendor addition will need changes to that 1 API to accommodate new requirements. So Option A and C are also ruled out.
* Correct answer is Create an API that receives the file and invokes a Process API with the data contained in the file, then have the Process API process the data using a MuleSoft Batch Job and other System APIs as needed. Answer to this question lies in the API led connectivity approach.
* API-led connectivity is a methodical way to connect data to applications through a series of reusable and purposeful modern APIs that are each developed to play a specific role C unlock data from systems, compose data into processes, or deliver an experience. System API: System API tier, which provides consistent, managed, and secure access to backend systems. Process APIs: Process APIs take core assets and combines them with some business logic to create a higher level of value. Experience APIs: These are designed specifically for consumption by a specific end-user app or device.
So in case of any future plans, organization can only add experience API on addition of new Vendors, which reuse the already existing process API. It will keep impact minimal.
What Anypoint Connectors support transactions?
- A . Database, JMS, VM
- B . Database, 3MS, HTTP
- C . Database, JMS, VM, SFTP
- D . Database, VM, File
A
Explanation:
Below Anypoint Connectors support transactions ● JMS C Publish C Consume ● VM C Publish C Consume ● Database C All operations
Mule application A receives a request Anypoint MQ message REQU with a payload containing a variable-length list of request objects. Application A uses the For Each scope to split the list into individual objects and sends each object as a message to an Anypoint MQ queue.
Service S listens on that queue, processes each message independently of all other messages, and sends a response message to a response queue.
Application A listens on that response queue and must in turn create and publish a response Anypoint MQ message RESP with a payload containing the list of responses sent by service S in the same order as the request objects originally sent in REQU.
Assume successful response messages are returned by service S for all request messages.
What is required so that application A can ensure that the length and order of the list of objects in RESP and REQU match, while at the same time maximizing message throughput?
- A . Use a Scatter-Gather within the For Each scope to ensure response message order Configure the Scatter-Gather with a persistent object store
- B . Perform all communication involving service S synchronously from within the For Each scope, so objects in RESP are in the exact same order as request objects in REQU
- C . Use an Async scope within the For Each scope and collect response messages in a second For Each scope in the order In which they arrive, then send RESP using this list of responses
- D . Keep track of the list length and all object indices in REQU, both in the For Each scope and in all communication involving service Use persistent storage when creating RESP
D
Explanation:
Correct answer is Perform all communication involving service S synchronously from within the For Each scope, so objects in RESP are in the exact same order as request objects in REQU: Using Anypoint MQ, you can create two types of queues: Standard queue These queues don’t guarantee a specific message order. Standard queues are the best fit for applications in which messages must be delivered quickly. FIFO (first in, first out) queue These queues ensure that your messages arrive in order. FIFO queues are the best fit for applications requiring strict message ordering and exactly-once delivery, but in which message delivery speed is of less importance Use of FIFO queue is no where in the option and also it decreased throughput. Similarly persistent object store is not the preferred solution approach when you maximizing message throughput. This rules out one of the options. Scatter Gather does not support ObjectStore. This rules out one of the options. Standard Anypoint MQ queues don’t guarantee a specific message order hence using another for each block to collect response wont work as requirement here is to ensure the order. Hence considering all the above factors the feasible approach is Perform all communication involving service S synchronously from within the For Each scope, so objects in RESP are in the exact same order as request objects in REQU
An API has been unit tested and is ready for integration testing. The API is governed by a Client ID Enforcement policy in all environments.
What must the testing team do before they can start integration testing the API in the Staging environment?
- A . They must access the API portal and create an API notebook using the Client ID and Client Secret supplied by the API portal in the Staging environment
- B . They must request access to the API instance in the Staging environment and obtain a Client ID and Client Secret to be used for testing the API
- C . They must be assigned as an API version owner of the API in the Staging environment
- D . They must request access to the Staging environment and obtain the Client ID and Client Secret for that environment to be used for testing the API
B
Explanation:
* It’s mentioned that the API is governed by a Client ID Enforcement policy in all environments.
* Client ID Enforcement policy allows only authorized applications to access the deployed API implementation.
* Each authorized application is configured with credentials: client_id and client_secret.
* At runtime, authorized applications provide the credentials with each request to the API implementation.
MuleSoft
Reference: https://docs.mulesoft.com/api-manager/2.x/policy-mule3-client-id-based-
policies
One of the backend systems involved by the API implementation enforces rate limits on the number of request a particle client can make.
Both the back-end system and API implementation are deployed to several non-production environments including the staging environment and to a particular production environment. Rate limiting of the back-end system applies to all non-production environments. The production environment however does not have any rate limiting.
What is the cost-effective approach to conduct performance test of the API implementation in the non-production staging environment?
- A . Including logic within the API implementation that bypasses in locations of the back-end system in the staging environment and invoke a Mocking service that replicates typical back-end system responses
Then conduct performance test using this API implementation - B . Use MUnit to simulate standard responses from the back-end system.
Then conduct performance test to identify other bottlenecks in the system - C . Create a Mocking service that replicates the back-end system’s production performance characteristics
Then configure the API implementation to use the mocking service and conduct the performance test - D . Conduct scaled-down performance tests in the staging environment against rate-limiting back-end system. Then upscale performance results to full production scale
What aspects of a CI/CD pipeline for Mute applications can be automated using MuleSoft-provided Maven plugins?
- A . Compile, package, unit test, deploy, create associated API instances in API Manager
B Import from API designer, compile, package, unit test, deploy, publish to Am/point Exchange - B . Compile, package, unit test, validate unit test coverage, deploy
- C . Compile, package, unit test, deploy, integration test
Which role is primarily responsible for building API implementation as part of a typical MuleSoft integration project?
- A . API Developer
- B . API Designer
- C . Integration Architect
- D . Operations