
Practice Free MuleSoft Integration Architect I Exam Online Questions
Mule application is deployed to Customer Hosted Runtime. Asynchronous logging was implemented to improved throughput of the system. But it was observed over the period of time that few of the important exception log messages which were used to rollback transactions are not working as expected causing huge loss to the Organization. Organization wants to avoid these losses. Application also has constraints due to which they cant compromise on throughput much.
What is the possible option in this case?
- A . Logging needs to be changed from asynchronous to synchronous
- B . External log appender needs to be used in this case
- C . Persistent memory storage should be used in such scenarios
- D . Mixed configuration of asynchronous or synchronous loggers should be used to log exceptions via synchronous way
D
Explanation:
Correct approach is to use Mixed configuration of asynchronous or synchronous loggers shoud be used to log exceptions via synchronous way Asynchronous logging poses a performance-reliability trade-off. You may lose some messages if Mule crashes before the logging buffers flush to the disk. In this case, consider that you can have a mixed configuration of asynchronous or synchronous loggers in your app. Best practice is to use asynchronous logging over synchronous with a minimum logging level of WARN for a production application. In some cases, enable INFO logging level when you need to confirm events such as successful policy installation or to perform troubleshooting. Configure your logging strategy by editing your application’s src/main/resources/log4j2.xml file
A new upstream API Is being designed to offer an SLA of 500 ms median and 800 ms maximum (99th percentile) response time. The corresponding API implementation needs to sequentially invoke 3 downstream APIs of very similar complexity. The first of these downstream APIs offers the following SLA for its response time: median: 100 ms, 80th percentile: 500 ms, 95th percentile: 1000 ms.
If possible, how can a timeout be set in the upstream API for the invocation of the first downstream API to meet the new upstream API’s desired SLA?
- A . Set a timeout of 100 ms; that leaves 400 ms for the other two downstream APIs to complete
- B . Do not set a timeout; the Invocation of this API Is mandatory and so we must wait until it responds
- C . Set a timeout of 50 ms; this times out more invocations of that API but gives additional room for retries
- D . No timeout is possible to meet the upstream API’s desired SLA; a different SLA must be negotiated with the first downstream API or invoke an alternative API
D
Explanation:
Before we answer this question, we need to understand what median (50th percentile) and 80th percentile means. If the 50th percentile (median) of a response time is 500ms that means that 50% of my transactions are either as fast or faster than 500ms.
If the 90th percentile of the same transaction is at 1000ms it means that 90% are as fast or faster and only 10% are slower. Now as per upstream SLA, 99th percentile is 800 ms which means 99% of the incoming requests should have response time less than or equal to 800 ms. But as per one of the backend API, their 95th percentile is 1000 ms which means that backend API will take 1000 ms or less than that for 95% of. requests. As there are three API invocation from upstream API, we can not conclude a timeout that can be set to meet the desired SLA as backend SLA’s do not support it. Let see why other answers are not correct.
1) Do not set a timeout –> This can potentially violate SLA’s of upstream API
2) Set a timeout of 100 ms; —> This will not work as backend API has 100 ms as median meaning only 50% requests will be answered in this time and we will get timeout for 50% of the requests. Important thing to note here is, All APIs need to be executed sequentially, so if you get timeout in first API, there is no use of going to second and third API. As a service provider you wouldn’t want to keep 50% of your consumers dissatisfied. So not the best option to go with.
*To quote an example: Let’s assume you have built an API to update customer contact details.
– First API is fetching customer number based on login credentials
– Second API is fetching Info in 1 table and returning unique key
– Third API, using unique key provided in second API as primary key, updating remaining details
* Now consider, if API times out in first API and can’t fetch customer number, in this case, it’s useless to call API 2 and 3 and that is why question mentions specifically that all APIs need to be executed sequentially.
3) Set a timeout of 50 ms –> Again not possible due to the same reason as above Hence correct answer is No timeout is possible to meet the upstream API’s desired SLA; a different SLA must be
negotiated with the first downstream API or invoke an alternative API
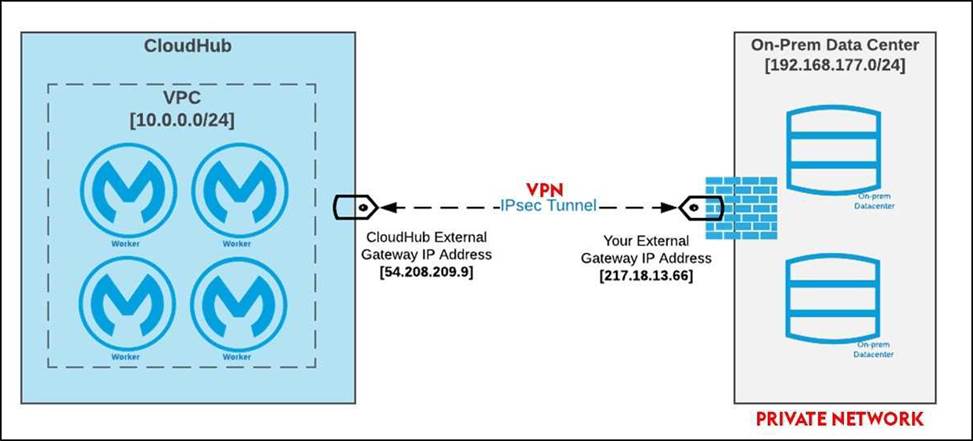
Mule applications need to be deployed to CloudHub so they can access on-premises database systems. These systems store sensitive and hence tightly protected data, so are not accessible over the internet.
What network architecture supports this requirement?
- A . An Anypoint VPC connected to the on-premises network using an IPsec tunnel or AWS DirectConnect, plus matching firewall rules in the VPC and on-premises network
- B . Static IP addresses for the Mule applications deployed to the CloudHub Shared Worker Cloud, plus
matching firewall rules and IP
whitelisting in the on-premises network - C . An Anypoint VPC with one Dedicated Load Balancer fronting each on-premises database system, plus matching IP whitelisting in the load balancer and firewall rules in the VPC and on-premises network
- D . Relocation of the database systems to a DMZ in the on-premises network, with Mule applications deployed to the CloudHub Shared Worker Cloud connecting only to the DMZ
A
Explanation:
* "Relocation of the database systems to a DMZ in the on-premises network, with Mule applications deployed to the CloudHub Shared Worker Cloud connecting only to the DMZ" is not a feasible option
* "Static IP addresses for the Mule applications deployed to the CloudHub Shared Worker Cloud, plus matching firewall rules and IP whitelisting in the on-premises network" – It is risk for sensitive data. – Even if you whitelist the database IP on your app, your app wont be able to connect to the database so this is also not a feasible option
* "An Anypoint VPC with one Dedicated Load Balancer fronting each on-premises database system, plus matching IP whitelisting in the load balancer and firewall rules in the VPC and on-premises network" Adding one VPC with a DLB for each backend system also makes no sense, is way too much work.
Why would you add a LB for one system.
* Correct answer. "An Anypoint VPC connected to the on-premises network using an IPsec tunnel or AWS DirectConnect, plus matching firewall rules in the VPC and on-premises network"
IPsec Tunnel You can use an IPsec tunnel with network-to-network configuration to connect your on-premises data centers to your Anypoint VPC. An IPsec VPN tunnel is generally the recommended solution for VPC to on-premises connectivity, as it provides a standardized, secure way to connect. This method also integrates well with existing IT infrastructure such as routers and appliances.
Reference: https://docs.mulesoft.com/runtime-manager/vpc-connectivity-methods-concept
A global, high-volume shopping Mule application is being built and will be deployed to CloudHub. To improve performance, the Mule application uses a Cache scope that maintains cache state in a CloudHub object store. Web clients will access the Mule application over HTTP from all around the world, with peak volume coinciding with business hours in the web client’s geographic location.
To achieve optimal performance, what Anypoint Platform region should be chosen for the CloudHub object store?
- A . Choose the same region as to where the Mule application is deployed
- B . Choose the US-West region, the only supported region for CloudHub object stores
- C . Choose the geographically closest available region for each web client
- D . Choose a region that is the traffic-weighted geographic center of all web clients
A
Explanation:
CloudHub object store should be in same region where the Mule application is deployed. This will give optimal performance.
Before learning about Cache scope and object store in Mule 4 we understand what is in general
Caching is and other related things.
WHAT DOES “CACHING” MEAN?
Caching is the process of storing frequently used data in memory, file system or database which saves processing time and load if it would have to be accessed from original source location every time.
In computing, a cache is a high-speed data storage layer which stores a subset of data, so that future requests for that data are served up faster than is possible by accessing the data’s primary storage location. Caching allows you to efficiently reuse previously retrieved or computed data.
How does Caching work?
The data in a cache is generally stored in fast access hardware such as RAM (Random-access memory) and may also be used in correlation with a software component. A cache’s primary purpose is to increase data retrieval performance by reducing the need to access the underlying slower storage layer.
Caching in MULE 4
In Mule 4 caching can be achieved in mule using cache scope and/or object-store. Cache scope
internally uses Object Store to store the data.
What is Object Store
Object Store lets applications store data and states across batch processes, Mule components, and applications, from within an application. If used on cloud hub, the object store is shared between applications deployed on Cluster.
Cache Scope is used in below-mentioned cases:
● Need to store the whole response from the outbound processor
● Data returned from the outbound processor does not change very frequently
● As Cache scope internally handle the cache hit and cache miss scenarios it is more readable Object Store is used in below-mentioned cases:
● Need to store custom/intermediary data
● To store watermarks
● Sharing the data/stage across applications, schedulers, batch.
If CloudHub object store is in same region where the Mule application is deployed it will aid in fast access of data and give optimal performance.
According to MuleSoft’s API development best practices, which type of API development approach starts with writing and approving an API contract?
- A . Implement-first
- B . Catalyst
- C . Agile
- D . Design-first
An organization has several APIs that accept JSON data over HTTP POST. The APIs are all publicly available and are associated with several mobile applications and web applications. The organization does NOT want to use any authentication or compliance policies for these APIs, but at the same time, is worried that some bad actor could send payloads that could somehow compromise the applications or servers running the API implementations.
What out-of-the-box Anypoint Platform policy can address exposure to this threat?
- A . Apply a Header injection and removal policy that detects the malicious data before it is used
- B . Apply an IP blacklist policy to all APIs; the blacklist will Include all bad actors
- C . Shut out bad actors by using HTTPS mutual authentication for all API invocations
- D . Apply a JSON threat protection policy to all APIs to detect potential threat vectors
D
Explanation:
We need to note few things about the scenario which will help us in reaching the correct solution. Point 1: The APIs are all publicly available and are associated with several mobile applications and web applications. This means Apply an IP blacklist policy is not viable option. as blacklisting IPs is limited to partial web traffic. It can’t be useful for traffic from mobile application
Point 2: The organization does NOT want to use any authentication or compliance policies for these
APIs. This means we can not apply HTTPS mutual authentication scheme.
Header injection or removal will not help the purpose.
By its nature, JSON is vulnerable to JavaScript injection. When you parse the JSON object, the malicious code inflicts its damages. An inordinate increase in the size and depth of the JSON payload can indicate injection. Applying the JSON threat protection policy can limit the size of your JSON payload and thwart recursive additions to the JSON hierarchy.
Hence correct answer is Apply a JSON threat protection policy to all APIs to detect potential threat vectors
An organization is designing Mule application which connects to a legacy backend. It has been reported that backend services are not highly available and experience downtime quite often.
As an integration architect which of the below approach you would propose to achieve high reliability goals?
- A . Alerts can be configured in Mule runtime so that backend team can be communicated when services are down
- B . Until Successful scope can be implemented while calling backend API’s
- C . On Error Continue scope to be used to call in case of error again
- D . Create a batch job with all requests being sent to backend using that job as per the availability of backend API’s
B
Explanation:
Correct answer is Untill Successful scope can be implemented while calling backend API’s The Until Successful scope repeatedly triggers the scope’s components (including flow references) until they all succeed or until a maximum number of retries is exceeded The scope provides option to control the max number of retries and the interval between retries The scope can execute any sequence of processors that may fail for whatever reason and may succeed upon retry
An organization is designing Mule application which connects to a legacy backend. It has been reported that backend services are not highly available and experience downtime quite often.
As an integration architect which of the below approach you would propose to achieve high reliability goals?
- A . Alerts can be configured in Mule runtime so that backend team can be communicated when services are down
- B . Until Successful scope can be implemented while calling backend API’s
- C . On Error Continue scope to be used to call in case of error again
- D . Create a batch job with all requests being sent to backend using that job as per the availability of backend API’s
B
Explanation:
Correct answer is Untill Successful scope can be implemented while calling backend API’s The Until Successful scope repeatedly triggers the scope’s components (including flow references) until they all succeed or until a maximum number of retries is exceeded The scope provides option to control the max number of retries and the interval between retries The scope can execute any sequence of processors that may fail for whatever reason and may succeed upon retry
A Mule application uses APIkit for SOAP to implement a SOAP web service. The Mule application has been deployed to a CloudHub worker in a testing environment.
The integration testing team wants to use a SOAP client to perform Integration testing. To carry out the integration tests, the integration team must obtain the interface definition for the SOAP web service.
What is the most idiomatic (used for its intended purpose) way for the integration testing team to obtain the interface definition for the deployed SOAP web service in order to perform integration testing with the SOAP client?
- A . Retrieve the OpenAPI Specification file(s) from API Manager
- B . Retrieve the WSDL file(s) from the deployed Mule application
- C . Retrieve the RAML file(s) from the deployed Mule application
- D . Retrieve the XML file(s) from Runtime Manager
D
Explanation:
Reference: https://docs.spring.io/spring-framework/docs/4.2.x/spring-framework-reference/html/integration-testing.html
Refer to the exhibit.
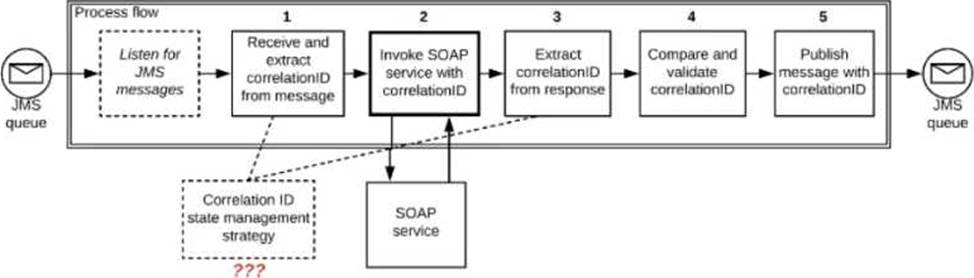
A Mule application is deployed to a multi-node Mule runtime cluster. The Mule application uses the competing consumer pattern among its cluster replicas to receive JMS messages from a JMS queue. To process each received JMS message, the following steps are performed in a flow: Step l: The JMS Correlation ID header is read from the received JMS message.
Step 2: The Mule application invokes an idempotent SOAP webservice over HTTPS, passing the JMS Correlation ID as one parameter in the SOAP request.
Step 3: The response from the SOAP webservice also returns the same JMS Correlation ID.
Step 4: The JMS Correlation ID received from the SOAP webservice is validated to be identical to the JMS Correlation ID received in Step 1.
Step 5: The Mule application creates a response JMS message, setting the JMS Correlation ID message header to the validated JMS Correlation ID and publishes that message to a response JMS queue.
Where should the Mule application store the JMS Correlation ID values received in Step 1 and Step 3 so that the validation in Step 4 can be performed, while also making the overall Mule application highly available, fault-tolerant, performant, and maintainable?
- A . Both Correlation ID values should be stored in a persistent object store
- B . Both Correlation ID values should be stored In a non-persistent object store
- C . The Correlation ID value in Step 1 should be stored in a persistent object store
The Correlation ID value in step 3 should be stored as a Mule event variable/attribute - D . Both Correlation ID values should be stored as Mule event variable/attribute
C
Explanation:
* If we store Correlation id value in step 1 as Mule event variables/attributes, the values will be cleared after server restart and we want system to be fault tolerant.
* The Correlation ID value in Step 1 should be stored in a persistent object store.
* We don’t need to store Correlation ID value in Step 3 to persistent object store. We can store it but
as we also need to make application performant. We can avoid this step of accessing persistent object store.
* Accessing persistent object stores slow down the performance as persistent object stores are by default stored in shared file systems.
* As the SOAP service is idempotent in nature. In case of any failures, using this Correlation ID saved in first step we can make call to SOAP service and validate the Correlation ID.
Top of Form Additional Information:
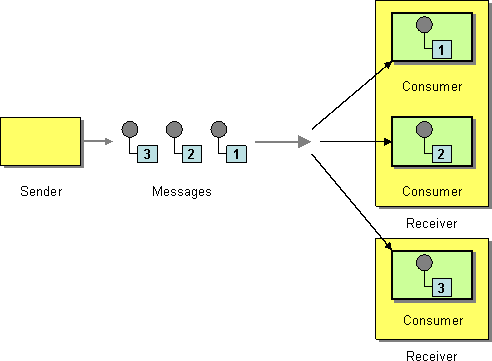
* Competing Consumers are multiple consumers that are all created to receive messages from a single Point-to-Point Channel. When the channel delivers a message, any of the consumers could potentially receive it. The messaging system’s implementation determines which consumer actually receives the message, but in effect the consumers compete with each other to be the receiver. Once a consumer receives a message, it can delegate to the rest of its application to help process the message.
* In case you are unaware about term idempotent re is more info:
Idempotent operations means their result will always same no matter how many times these operations are invoked.

Bottom of Form