
Practice Free MuleSoft Integration Architect I Exam Online Questions
Refer to the exhibit.
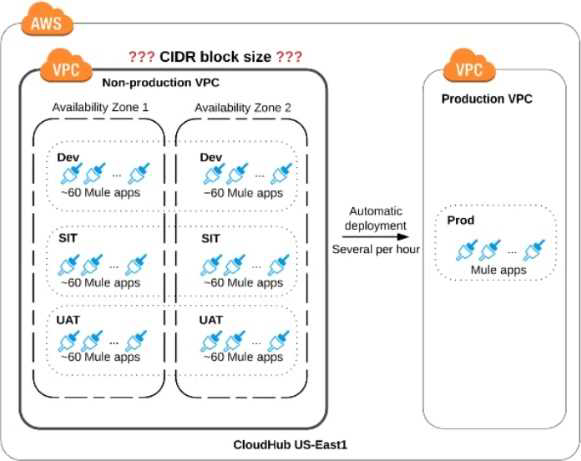
An organization is sizing an Anypoint VPC for the non-production deployments of those Mule applications that connect to the organization’s on-premises systems. This applies to approx. 60 Mule applications. Each application is deployed to two CloudHub i workers. The organization currently has three non-production environments (DEV, SIT and UAT) that share this VPC. The AWS region of the VPC has two AZs.
The organization has a very mature DevOps approach which automatically progresses each application through all non-production environments before automatically deploying to production.
This process results in several Mule application deployments per hour, using CloudHub’s normal zero-downtime deployment feature.
What is a CIDR block for this VPC that results in the smallest usable private IP address range?
- A . 10.0.0.0/26 (64 IPS)
- B . 10.0.0.0/25 (128 IPs)
- C . 10.0.0.0/24 (256 IPs)
- D . 10.0.0.0/22 (1024 IPs)
D
Explanation:
Mule applications are deployed in CloudHub workers and each worker is assigned with a dedicated IP
• For zero downtime deployment, each worker in CloudHub needs additional IP addresses
• A few IPs in a VPC are reserved for infrastructure (generally 2 IPs)
• The IP addresses are usually in a private range with a subnet block specifier, such as 10.0.0.1/24
• The smallest CIDR network subnet block you can assign for your VPC is /24 (256 IP addresses) (60*3 env * 2 worker per application) + 50% of (total) for zero downtime = 540 In this case correct answer is 10.0.0.0/22 as this provided 1024 IP’s. Other IP’s are insufficient.
An IT integration delivery team begins a project by gathering all of the requirements, and proceeds to execute the remaining project activities as sequential, non-repeating phases.
Which IT project delivery methodology is this team following?
- A . Kanban
- B . Scrum
- C . Waterfall
- D . Agile
Refer to the exhibit.
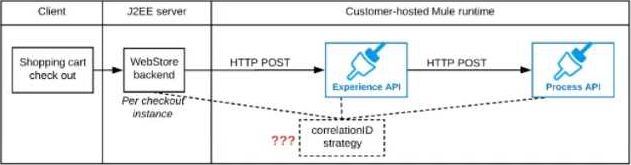
A shopping cart checkout process consists of a web store backend sending a sequence of API invocations to an Experience API, which in turn invokes a Process API. All API invocations are over HTTPS POST. The Java web store backend executes in a Java EE application server, while all API implementations are Mule applications executing in a customer -hosted Mule runtime. End-to-end correlation of all HTTP requests and responses belonging to each individual checkout Instance is required. This is to be done through a common correlation ID, so that all log entries written by the web store backend, Experience API implementation, and Process API implementation include the same correlation ID for all requests and responses belonging to the same checkout instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the web store backend and the implementations of the Experience API and Process API to participate in end-to-end correlation of the API invocations for each checkout instance?
A) The web store backend, being a Java EE application, automatically makes use of the thread-local correlation ID generated by the Java EE application server and automatically transmits that to the Experience API using HTTP-standard headers
No special code or configuration is included in the web store backend, Experience API, and Process API implementations to generate and manage the correlation ID
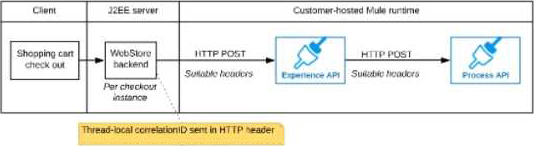
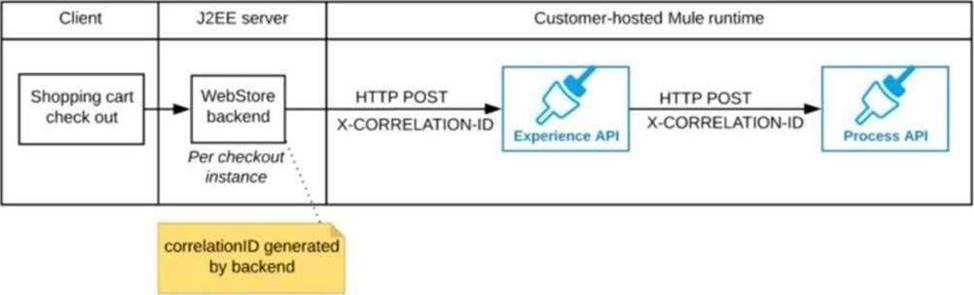
B) The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout
No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID
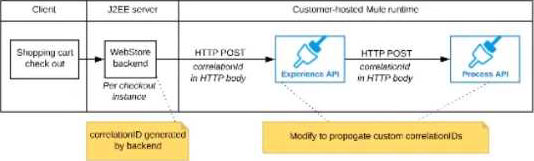
C) The Experience API implementation generates a correlation ID for each incoming HTTP request and passes it to the web store backend in the HTTP response, which includes it in all subsequent API invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the Process API in a suitable HTTP request header
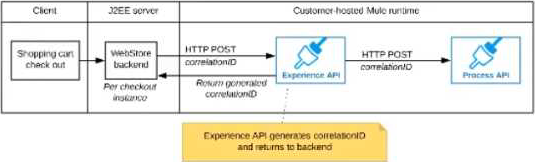
D) The web store backend sends a correlation ID value in the HTTP request body In the way required by the Experience API
The Experience API and Process API implementations must be coded to receive the custom correlation ID In the HTTP requests and propagate It in suitable HTTP request headers
- A . Option A
- B . Option B
- C . Option C
- D . Option D
B
Explanation:
Correct answer is "The web store backend generates a new correlation ID value at the start of checkout and sets it on the X¬CORRELATION-ID HTTP request header in each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID": By design, Correlation Ids cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part of the Event Context and is generated as soon as the message is received by the application. When a HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id" header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-Id" header or set "Send Correlation Id" to NEVER.
Mulesoft
Reference: https://help.mulesoft.com/s/article/How-to-Set-Custom-Correlation-Id-for-Flows-with-HTTP-Endpoint-in-Mule-4
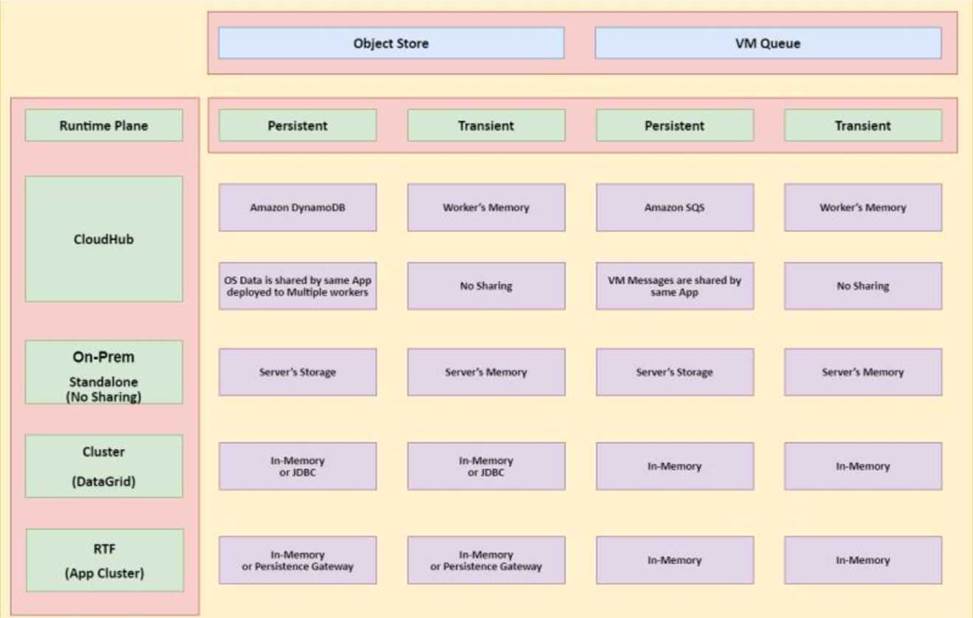
A Mule application name Pub uses a persistence object store. The Pub Mule application is deployed to Cloudhub and it configured to use Object Store v2.
Another Mule application name sub is being developed to retrieve values from the Pub Mule application persistence object Store and will also be deployed to cloudhub.
What is the most direct way for the Sub Mule application to retrieve values from the Pub Mule application persistence object store with the least latency?
- A . Use an object store connector configured to access the Pub Mule application persistence object store
- B . Use a VM connector configured to directly access the persistence queue of the Pub Mule application persistence object store.
- C . Use an Anypoint MQ connector configured to directly access the Pub Mule application persistence object store
- D . Use the Object store v2 REST API configured to access the Pub Mule application persistence object store.
D
Explanation:
* The Object Store V2 API enables API access to Anypoint Platform Object Store v2.
* You can configure a Mule app to use the Object Store REST API to store and retrieve values from an object store in another Mule app. However, Object Store v2 is not designed for app-to-app communication. To share data between two Mule4 apps, use a queue in Anypoint MQ.
* The Object Store v2 APIs enable you to use REST to perform the following:
– Retrieve a list of object stores and keys associated with an application.
– Store and retrieve key-value pairs in an object store.
– Delete key-value pairs from an object store.
– Retrieve Object Store usage statistics for your organization.
– Object Store provides these APIs:
Object Store API
Object Store Stats API
Reference: https://docs.mulesoft.com/object-store/osv2-apis
Additional Info:
When to use Object Store and when to use VM
An organization is choosing between API-led connectivity and other integration approaches.
According to MuleSoft, which business benefits is associated with an API-led connectivity approach using Anypoint Platform?
- A . improved security through adoption of monolithic architectures
- B . Increased developer productivity through sell-service of API assets
- C . Greater project predictability through tight coupling of systems
- D . Higher outcome repeatability through centralized development
An application load balancer routes requests to a RESTful web API secured by Anypoint Flex Gateway.
Which protocol is involved in the communication between the load balancer and the Gateway?
- A . SFTP
- B . HTTPS
- C . LDAP
- D . SMTP
A company is using Mulesoft to develop API’s and deploy them to Cloudhub and on premises targets. Recently it has decided to enable Runtime Fabric deployment option as well and infrastructure is set up for this option.
What can be used to deploy Runtime Fabric?
- A . AnypointCLI
- B . Anypoint platform REST API’s
- C . Directly uploading ajar file from the Runtime manager
- D . Mule maven plug-in
Following MuleSoft best practices, what MuleSoft runtime deployment option best meets the company’s goals to begin its digital transformation journey?
- A . Runtime Fabric on VMs/bare metal
- B . CloudHub runtimes
- C . Customer-hosted runtimes provisioned by a MuleSoft services partner
- D . Customer-hosted self-provisioned runtimes
An organization’s IT team follows an API-led connectivity approach and must use Anypoint Platform to implement a System AP that securely accesses customer data. The organization uses Salesforce as the system of record for all customer data, and its most important objective is to reduce the overall development time to release the System API.
The team’s integration architect has identified four different approaches to access the customer data from within the implementation of the System API by using different Anypoint Connectors that all meet the technical requirements of the project.
- A . Use the Anypoint Connector for Database to connect to a MySQL database to access a copy of the customer data
- B . Use the Anypoint Connector for HTTP to connect to the Salesforce APIs to directly access the customer data
- C . Use the Anypoint Connector for Salesforce to connect to the Salesforce APIs to directly access the customer data
- D . Use the Anypoint Connector tor FTP to download a file containing a recent near-real time extract of the customer data
Refer to the exhibit.

What is the type data format shown in the exhibit?
- A . JSON
- B . XML
- C . YAML
- D . CSV