
Practice Free MLS-C01 Exam Online Questions
A company ingests machine learning (ML) data from web advertising clicks into an Amazon S3 data lake. Click data is added to an Amazon Kinesis data stream by using the Kinesis Producer Library (KPL). The data is loaded into the S3 data lake from the data stream by using an Amazon Kinesis Data Firehose delivery stream. As the data volume increases, an ML specialist notices that the rate of data ingested into Amazon S3 is relatively constant. There also is an increasing backlog of data for Kinesis Data Streams and Kinesis Data Firehose to ingest.
Which next step is MOST likely to improve the data ingestion rate into Amazon S3?
- A . Increase the number of S3 prefixes for the delivery stream to write to.
- B . Decrease the retention period for the data stream.
- C . Increase the number of shards for the data stream.
- D . Add more consumers using the Kinesis Client Library (KCL).
C
Explanation:
The solution C is the most likely to improve the data ingestion rate into Amazon S3 because it increases the number of shards for the data stream. The number of shards determines the throughput capacity of the data stream, which affects the rate of data ingestion. Each shard can support up to 1 MB per second of data input and 2 MB per second of data output. By increasing the number of shards, the company can increase the data ingestion rate proportionally. The company can use the UpdateShardCount API operation to modify the number of shards in the data stream1.
The other options are not likely to improve the data ingestion rate into Amazon S3 because:
Option A: Increasing the number of S3 prefixes for the delivery stream to write to will not affect the data ingestion rate, as it only changes the way the data is organized in the S3 bucket. The number of S3 prefixes can help to optimize the performance of downstream applications that read the data from S3, but it does not impact the performance of Kinesis Data Firehose2.
Option B: Decreasing the retention period for the data stream will not affect the data ingestion rate, as it only changes the amount of time the data is stored in the data stream. The retention period can help to manage the data availability and durability, but it does not impact the throughput capacity of the data stream3.
Option D: Adding more consumers using the Kinesis Client Library (KCL) will not affect the data ingestion rate, as it only changes the way the data is processed by downstream applications. The consumers can help to scale the data processing and handle failures, but they do not impact the data ingestion into S3 by Kinesis Data Firehose4.
References:
1: Resharding – Amazon Kinesis Data Streams
2: Amazon S3 Prefixes – Amazon Kinesis Data Firehose
3: Data Retention – Amazon Kinesis Data Streams
4: Developing Consumers Using the Kinesis Client Library – Amazon Kinesis Data Streams
A data scientist wants to use Amazon Forecast to build a forecasting model for inventory demand for a retail company. The company has provided a dataset of historic inventory demand for its products as a .csv file stored in an Amazon S3 bucket.
The table below shows a sample of the dataset.

How should the data scientist transform the data?
- A . Use ETL jobs in AWS Glue to separate the dataset into a target time series dataset and an item metadata dataset. Upload both datasets as .csv files to Amazon S3.
- B . Use a Jupyter notebook in Amazon SageMaker to separate the dataset into a related time series dataset and an item metadata dataset. Upload both datasets as tables in Amazon Aurora.
- C . Use AWS Batch jobs to separate the dataset into a target time series dataset, a related time series dataset, and an item metadata dataset. Upload them directly to Forecast from a local machine.
- D . Use a Jupyter notebook in Amazon SageMaker to transform the data into the optimized protobuf recordIO format. Upload the dataset in this format to Amazon S3.
A
Explanation:
Amazon Forecast requires the input data to be in a specific format. The data scientist should use ETL jobs in AWS Glue to separate the dataset into a target time series dataset and an item metadata dataset. The target time series dataset should contain the timestamp, item_id, and demand columns, while the item metadata dataset should contain the item_id, category, and lead_time columns. Both datasets should be uploaded as .csv files to Amazon S3.
References:
How Amazon Forecast Works – Amazon Forecast
Choosing Datasets – Amazon Forecast
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning Specialist would like to build a binary classifier based on two features: age of account and transaction month.
The class distribution for these features is illustrated in the figure provided.
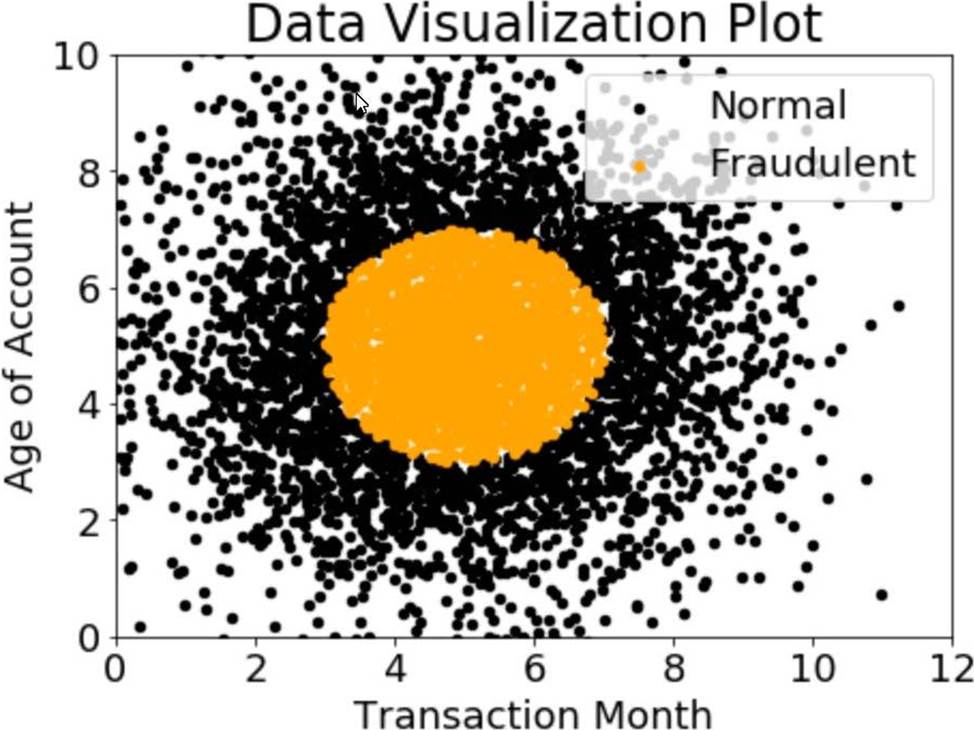
Based on this information which model would have the HIGHEST accuracy?
- A . Long short-term memory (LSTM) model with scaled exponential linear unit (SELL))
- B . Logistic regression
- C . Support vector machine (SVM) with non-linear kernel
- D . Single perceptron with tanh activation function
C
Explanation:
Based on the figure provided, the data is not linearly separable. Therefore, a non-linear model such as SVM with a non-linear kernel would be the best choice. SVMs are particularly effective in high-dimensional spaces and are versatile in that they can be used for both linear and non-linear data. Additionally, SVMs have a high level of accuracy and are less prone to overfitting1
References: 1: https://docs.aws.amazon.com/sagemaker/latest/dg/svm.html
An online reseller has a large, multi-column dataset with one column missing 30% of its data A Machine Learning Specialist believes that certain columns in the dataset could be used to reconstruct the missing data.
Which reconstruction approach should the Specialist use to preserve the integrity of the dataset?
- A . Listwise deletion
- B . Last observation carried forward
- C . Multiple imputation
- D . Mean substitution
C
Explanation:
Multiple imputation is a technique that uses machine learning to generate multiple plausible values for each missing value in a dataset, based on the observed data and the relationships among the variables. Multiple imputation preserves the integrity of the dataset by accounting for the uncertainty and variability of the missing data, and avoids the bias and loss of information that may result from other methods, such as listwise deletion, last observation carried forward, or mean substitution. Multiple imputation can improve the accuracy and validity of statistical analysis and machine learning models that use the imputed dataset.
References:
Managing missing values in your target and related datasets with automated imputation support in Amazon Forecast
Imputation by feature importance (IBFI): A methodology to impute missing data in large datasets Multiple Imputation by Chained Equations (MICE) Explained
A web-based company wants to improve its conversion rate on its landing page Using a large historical dataset of customer visits, the company has repeatedly trained a multi-class deep learning network algorithm on Amazon SageMaker However there is an overfitting problem training data shows 90% accuracy in predictions, while test data shows 70% accuracy only.
The company needs to boost the generalization of its model before deploying it into production to maximize conversions of visits to purchases
Which action is recommended to provide the HIGHEST accuracy model for the company’s test and validation data?
- A . Increase the randomization of training data in the mini-batches used in training.
- B . Allocate a higher proportion of the overall data to the training dataset
- C . Apply L1 or L2 regularization and dropouts to the training.
- D . Reduce the number of layers and units (or neurons) from the deep learning network.
C
Explanation:
Regularization and dropouts are techniques that can help reduce overfitting in deep learning models. Overfitting occurs when the model learns too much from the training data and fails to generalize well to new data. Regularization adds a penalty term to the loss function that penalizes the model for having large or complex weights. This prevents the model from memorizing the noise or irrelevant features in the training data. L1 and L2 are two types of regularization that differ in how they calculate the penalty term. L1 regularization uses the absolute value of the weights, while L2 regularization uses the square of the weights. Dropouts are another technique that randomly drops out some units or neurons from the network during training. This creates a thinner network that is less prone to overfitting. Dropouts also act as a form of ensemble learning, where multiple sub-models are combined to produce a better prediction. By applying regularization and dropouts to the training, the web-based company can improve the generalization and accuracy of its deep learning model on the test and validation data.
References:
Regularization: A video that explains the concept and benefits of regularization in deep learning.
Dropout: A video that demonstrates how dropout works and why it helps reduce overfitting.
A Machine Learning Specialist is required to build a supervised image-recognition model to identify a cat. The ML Specialist performs some tests and records the following results for a neural network-based image classifier:
Total number of images available = 1,000 Test set images = 100 (constant test set)
The ML Specialist notices that, in over 75% of the misclassified images, the cats were held upside down by their owners.
Which techniques can be used by the ML Specialist to improve this specific test error?
- A . Increase the training data by adding variation in rotation for training images.
- B . Increase the number of epochs for model training.
- C . Increase the number of layers for the neural network.
- D . Increase the dropout rate for the second-to-last layer.
A
Explanation:
To improve the test error for the image classifier, the Machine Learning Specialist should use the technique of increasing the training data by adding variation in rotation for training images. This technique is called data augmentation, which is a way of artificially expanding the size and diversity of the training dataset by applying various transformations to the original images, such as rotation, flipping, cropping, scaling, etc. Data augmentation can help the model learn more robust features that are invariant to the orientation, position, and size of the objects in the images. This can improve the generalization ability of the model and reduce the test error, especially for cases where the images are not well-aligned or have different perspectives1.
References: 1: Image Augmentation – Amazon SageMaker
A large mobile network operating company is building a machine learning model to predict customers who are likely to unsubscribe from the service. The company plans to offer an incentive for these customers as the cost of churn is far greater than the cost of the incentive.
The model produces the following confusion matrix after evaluating on a test dataset of 100 customers:
Based on the model evaluation results, why is this a viable model for production?

- A . The model is 86% accurate and the cost incurred by the company as a result of false negatives is less than the false positives.
- B . The precision of the model is 86%, which is less than the accuracy of the model.
- C . The model is 86% accurate and the cost incurred by the company as a result of false positives is less than the false negatives.
- D . The precision of the model is 86%, which is greater than the accuracy of the model.
C
Explanation:
Based on the model evaluation results, this is a viable model for production because the model is 86% accurate and the cost incurred by the company as a result of false positives is less than the false negatives. The accuracy of the model is the proportion of correct predictions out of the total predictions, which can be calculated by adding the true positives and true negatives and dividing by the total number of observations. In this case, the accuracy of the model is (10 + 76) / 100 = 0.86, which means that the model correctly predicted 86% of the customers’ churn status. The cost incurred by the company as a result of false positives and false negatives is the loss or damage that the company suffers when the model makes incorrect predictions. A false positive is when the model predicts that a customer will churn, but the customer actually does not churn. A false negative is when the model predicts that a customer will not churn, but the customer actually churns. In this case, the cost of a false positive is the incentive that the company offers to the customer who is predicted to churn, which is a relatively low cost. The cost of a false negative is the revenue that the company loses when the customer churns, which is a relatively high cost. Therefore, the cost of a false positive is less than the cost of a false negative, and the company would prefer to have more false positives than false negatives. The model has 10 false positives and 4 false negatives, which means that the company’s cost is lower than if the model had more false negatives and fewer false positives.
An ecommerce company has used Amazon SageMaker to deploy a factorization machines (FM) model to suggest products for customers. The company’s data science team has developed two new models by using the TensorFlow and PyTorch deep learning frameworks.
The company needs to use A/B testing to evaluate the new models against the deployed model. …required A/B testing setup is as follows:
• Send 70% of traffic to the FM model, 15% of traffic to the TensorFlow model, and 15% of traffic to the Py Torch model.
• For customers who are from Europe, send all traffic to the TensorFlow model
..sh architecture can the company use to implement the required A/B testing setup?
- A . Create two new SageMaker endpoints for the TensorFlow and PyTorch models in addition to the existing SageMaker endpoint. Create an Application Load Balancer Create a target group for each endpoint. Configure listener rules and add weight to the target groups. To send traffic to the TensorFlow model for customers who are from Europe, create an additional listener rule to forward traffic to the TensorFlow target group.
- B . Create two production variants for the TensorFlow and PyTorch models. Create an auto scaling policy and configure the desired A/B weights to direct traffic to each production variant Update the existing SageMaker endpoint with the auto scaling policy. To send traffic to the TensorFlow model for customers who are from Europe, set the TargetVariant header in the request to point to the variant name of the TensorFlow model.
- C . Create two new SageMaker endpoints for the TensorFlow and PyTorch models in addition to the existing SageMaker endpoint. Create a Network Load Balancer. Create a target group for each endpoint. Configure listener rules and add weight to the target groups. To send traffic to the TensorFlow model for customers who are from Europe, create an additional listener rule to forward traffic to the TensorFlow target group.
- D . Create two production variants for the TensorFlow and PyTorch models. Specify the weight for each production variant in the SageMaker endpoint configuration. Update the existing SageMaker endpoint with the new configuration. To send traffic to the TensorFlow model for customers who are from Europe, set the TargetVariant header in the request to point to the variant name of the TensorFlow model.
D
Explanation:
The correct answer is D because it allows the company to use the existing SageMaker endpoint and leverage the built-in functionality of production variants for A/B testing. Production variants can be used to test ML models that have been trained using different training datasets, algorithms, and ML frameworks; test how they perform on different instance types; or a combination of all of the above1. By specifying the weight for each production variant in the endpoint configuration, the company can control how much traffic to send to each variant. By setting the TargetVariant header in the request, the company can invoke a specific variant directly for each request2. This enables the company to implement the required A/B testing setup without creating additional endpoints or load balancers.
References:
1: Production variants – Amazon SageMaker
2: A/B Testing ML models in production using Amazon SageMaker | AWS Machine Learning Blog
A machine learning specialist needs to analyze comments on a news website with users across the globe. The specialist must find the most discussed topics in the comments that are in either English or Spanish.
What steps could be used to accomplish this task? (Choose two.)
- A . Use an Amazon SageMaker BlazingText algorithm to find the topics independently from language.
Proceed with the analysis. - B . Use an Amazon SageMaker seq2seq algorithm to translate from Spanish to English, if necessary.
Use a SageMaker Latent Dirichlet Allocation (LDA) algorithm to find the topics. - C . Use Amazon Translate to translate from Spanish to English, if necessary. Use Amazon Comprehend topic modeling to find the topics.
- D . Use Amazon Translate to translate from Spanish to English, if necessary. Use Amazon Lex to extract topics form the content.
- E . Use Amazon Translate to translate from Spanish to English, if necessary. Use Amazon SageMaker Neural Topic Model (NTM) to find the topics.
C, E
Explanation:
To find the most discussed topics in the comments that are in either English or Spanish, the machine learning specialist needs to perform two steps: first, translate the comments from Spanish to English if necessary, and second, apply a topic modeling algorithm to the comments. The following options are valid ways to accomplish these steps using AWS services:
Option C: Use Amazon Translate to translate from Spanish to English, if necessary. Use Amazon Comprehend topic modeling to find the topics. Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation. Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text. Amazon Comprehend topic modeling is a feature that automatically organizes a collection of text documents into topics that contain commonly used words and phrases.
Option E: Use Amazon Translate to translate from Spanish to English, if necessary. Use Amazon SageMaker Neural Topic Model (NTM) to find the topics. Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly. Amazon SageMaker Neural Topic Model (NTM) is an unsupervised learning algorithm that is used to organize a corpus of documents into topics that contain word groupings based on their statistical distribution. The other options are not valid because:
Option A: Amazon SageMaker BlazingText algorithm is not a topic modeling algorithm, but a text classification and word embedding algorithm. It cannot find the topics independently from language, as different languages have different word distributions and semantics.
Option B: Amazon SageMaker seq2seq algorithm is not a translation algorithm, but a sequence-to-sequence learning algorithm that can be used for tasks such as summarization, chatbot, and question answering. Amazon SageMaker Latent Dirichlet Allocation (LDA) algorithm is a topic modeling algorithm, but it requires the input documents to be in the same language and preprocessed into a
bag-of-words format.
Option D: Amazon Lex is not a topic modeling algorithm, but a service for building conversational interfaces into any application using voice and text. It cannot extract topics from the content, but only intents and slots based on a predefined bot configuration.
Reference: Amazon Translate
Amazon Comprehend
Amazon SageMaker
Amazon SageMaker Neural Topic Model (NTM) Algorithm Amazon SageMaker BlazingText Amazon SageMaker Seq2Seq
Amazon SageMaker Latent Dirichlet Allocation (LDA) Algorithm Amazon Lex
A global bank requires a solution to predict whether customers will leave the bank and choose another bank. The bank is using a dataset to train a model to predict customer loss. The training dataset has 1,000 rows. The training dataset includes 100 instances of customers who left the bank.
A machine learning (ML) specialist is using Amazon SageMaker Data Wrangler to train a churn prediction model by using a SageMaker training job. After training, the ML specialist notices that the model returns only false results. The ML specialist must correct the model so that it returns more accurate predictions.
Which solution will meet these requirements?
- A . Apply anomaly detection to remove outliers from the training dataset before training.
- B . Apply Synthetic Minority Oversampling Technique (SMOTE) to the training dataset before training.
- C . Apply normalization to the features of the training dataset before training.
- D . Apply undersampling to the training dataset before training.
B
Explanation:
The best solution to meet the requirements is to apply Synthetic Minority Oversampling Technique (SMOTE) to the training dataset before training. SMOTE is a technique that generates synthetic samples for the minority class by interpolating between existing samples. This can help balance the class distribution and provide more information to the model. SMOTE can improve the performance of the model on the minority class, which is the class of interest in churn prediction. SMOTE can be applied using the SageMaker Data Wrangler, which provides a built-in analysis for oversampling the minority class1.
The other options are not effective solutions for the problem. Applying anomaly detection to remove outliers from the training dataset before training may not improve the model’s accuracy, as outliers may not be the main cause of the false results. Moreover, removing outliers may reduce the diversity of the data and make the model less robust. Applying normalization to the features of the training dataset before training may improve the model’s convergence and stability, but it does not address the class imbalance issue. Normalization can also be applied using the SageMaker Data Wrangler, which provides a built-in transformation for scaling the features2. Applying undersampling to the training dataset before training may reduce the class imbalance, but it also discards potentially useful information from the majority class. Undersampling can also result in underfitting and high bias for the model.
References:
• Analyze and Visualize
• Transform and Export
• SMOTE for Imbalanced Classification with Python
• Churn prediction using Amazon SageMaker built-in tabular algorithms LightGBM, CatBoost, TabTransformer, and AutoGluon-Tabular