
Practice Free MLS-C01 Exam Online Questions
A Machine Learning Specialist works for a credit card processing company and needs to predict which transactions may be fraudulent in near-real time. Specifically, the Specialist must train a model that returns the probability that a given transaction may fraudulent.
How should the Specialist frame this business problem?
- A . Streaming classification
- B . Binary classification
- C . Multi-category classification
- D . Regression classification
B
Explanation:
The business problem of predicting whether a new credit card applicant will default on a credit card payment can be framed as a binary classification problem. Binary classification is the task of predicting a discrete class label output for an example, where the class label can only take one of two possible values. In this case, the class label can be either “default” or “no default”, indicating whether the applicant will or will not default on a credit card payment. A binary classification model can return the probability that a given applicant belongs to each class, and then assign the applicant to the class with the highest probability. For example, if the model predicts that an applicant has a 0.8 probability of defaulting and a 0.2 probability of not defaulting, then the model will classify the applicant as “default”. Binary classification is suitable for this problem because the outcome of interest is categorical and binary, and the model needs to return the probability of each outcome.
References:
AWS Machine Learning Specialty Exam Guide
AWS Machine Learning Training – Classification vs Regression in Machine Learning
A Data Scientist is developing a machine learning model to predict future patient outcomes based on information collected about each patient and their treatment plans. The model should output a continuous value as its prediction. The data available includes labeled outcomes for a set of 4,000 patients. The study was conducted on a group of individuals over the age of 65 who have a particular disease that is known to worsen with age.
Initial models have performed poorly. While reviewing the underlying data, the Data Scientist notices
that, out of 4,000 patient observations, there are 450 where the patient age has been input as 0. The other features for these observations appear normal compared to the rest of the sample population.
How should the Data Scientist correct this issue?
- A . Drop all records from the dataset where age has been set to 0.
- B . Replace the age field value for records with a value of 0 with the mean or median value from the dataset.
- C . Drop the age feature from the dataset and train the model using the rest of the features.
- D . Use k-means clustering to handle missing features.
B
Explanation:
The best way to handle the missing values in the patient age feature is to replace them with the mean or median value from the dataset. This is a common technique for imputing missing values that preserves the overall distribution of the data and avoids introducing bias or reducing the sample size. Dropping the records or the feature would result in losing valuable information and reducing the accuracy of the model. Using k-means clustering would not be appropriate for handling missing values in a single feature, as it is a method for grouping similar data points based on multiple features.
References:
Effective Strategies to Handle Missing Values in Data Analysis
How To Handle Missing Values In Machine Learning Data With Weka.
How to handle missing values in Python – Machine Learning Plus
A company sells thousands of products on a public website and wants to automatically identify products with potential durability problems. The company has 1.000 reviews with date, star rating, review text, review summary, and customer email fields, but many reviews are incomplete and have empty fields. Each review has already been labeled with the correct durability result.
A machine learning specialist must train a model to identify reviews expressing concerns over product durability. The first model needs to be trained and ready to review in 2 days.
What is the MOST direct approach to solve this problem within 2 days?
- A . Train a custom classifier by using Amazon Comprehend.
- B . Build a recurrent neural network (RNN) in Amazon SageMaker by using Gluon and Apache MXNet.
- C . Train a built-in BlazingText model using Word2Vec mode in Amazon SageMaker.
- D . Use a built-in seq2seq model in Amazon SageMaker.
A
Explanation:
The most direct approach to solve this problem within 2 days is to train a custom classifier by using Amazon Comprehend. Amazon Comprehend is a natural language processing (NLP) service that can analyze text and extract insights such as sentiment, entities, topics, and syntax. Amazon Comprehend
also provides a custom classification feature that allows users to create and train a custom text classifier using their own labeled data. The custom classifier can then be used to categorize any text document into one or more custom classes. For this use case, the custom classifier can be trained to identify reviews that express concerns over product durability as a class, and use the star rating, review text, and review summary fields as input features. The custom classifier can be created and trained using the Amazon Comprehend console or API, and does not require any coding or machine learning expertise. The training process is fully managed and scalable, and can handle large and complex datasets. The custom classifier can be trained and ready to review in 2 days or less, depending on the size and quality of the dataset.
The other options are not the most direct approaches because:
Option B: Building a recurrent neural network (RNN) in Amazon SageMaker by using Gluon and Apache MXNet is a more complex and time-consuming approach that requires coding and machine learning skills. RNNs are a type of deep learning models that can process sequential data, such as text, and learn long-term dependencies between tokens. Gluon is a high-level API for MXNet that simplifies the development of deep learning models. Amazon SageMaker is a fully managed service that provides tools and frameworks for building, training, and deploying machine learning models. However, to use this approach, the machine learning specialist would have to write custom code to preprocess the data, define the RNN architecture, train the model, and evaluate the results. This would likely take more than 2 days and involve more administrative overhead.
Option C: Training a built-in BlazingText model using Word2Vec mode in Amazon SageMaker is not a suitable approach for text classification. BlazingText is a built-in algorithm in Amazon SageMaker that provides highly optimized implementations of the Word2Vec and text classification algorithms. The Word2Vec algorithm is useful for generating word embeddings, which are dense vector representations of words that capture their semantic and syntactic similarities. However, word embeddings alone are not sufficient for text classification, as they do not account for the context and structure of the text documents. To use this approach, the machine learning specialist would have to combine the word embeddings with another classifier model, such as a logistic regression or a neural network, which would add more complexity and time to the solution.
Option D: Using a built-in seq2seq model in Amazon SageMaker is not a relevant approach for text classification. Seq2seq is a built-in algorithm in Amazon SageMaker that provides a sequence-to- sequence framework for neural machine translation based on MXNet. Seq2seq is a supervised learning algorithm that can generate an output sequence of tokens given an input sequence of tokens, such as translating a sentence from one language to another. However, seq2seq is not designed for text classification, which requires assigning a label or a category to a text document, not generating another text sequence. To use this approach, the machine learning specialist would have to modify the seq2seq algorithm to fit the text classification task, which would be challenging and inefficient.
Reference: Custom Classification – Amazon Comprehend
Build a Text Classification Model with Amazon Comprehend – AWS Machine Learning Blog
Recurrent Neural Networks – Gluon API
BlazingText Algorithm – Amazon SageMaker
Sequence-to-Sequence Algorithm – Amazon SageMaker
A Data Scientist is training a multilayer perception (MLP) on a dataset with multiple classes. The target class of interest is unique compared to the other classes within the dataset, but it does not achieve and acceptable ecall metric. The Data Scientist has already tried varying the number and size of the MLP’s hidden layers, which has not significantly improved the results. A solution to improve recall must be implemented as quickly as possible.
Which techniques should be used to meet these requirements?
- A . Gather more data using Amazon Mechanical Turk and then retrain
- B . Train an anomaly detection model instead of an MLP
- C . Train an XGBoost model instead of an MLP
- D . Add class weights to the MLP’s loss function and then retrain
D
Explanation:
The best technique to improve the recall of the MLP for the target class of interest is to add class weights to the MLP’s loss function and then retrain. Class weights are a way of assigning different importance to each class in the dataset, such that the model will pay more attention to the classes with higher weights. This can help mitigate the class imbalance problem, where the model tends to favor the majority class and ignore the minority class. By increasing the weight of the target class of interest, the model will try to reduce the false negatives and increase the true positives, which will improve the recall metric. Adding class weights to the loss function is also a quick and easy solution, as it does not require gathering more data, changing the model architecture, or switching to a different algorithm.
Reference: AWS Machine Learning Specialty Exam Guide
AWS Machine Learning Training – Deep Learning with Amazon SageMaker AWS Machine Learning Training – Class Imbalance and Weighted Loss Functions
A Machine Learning Specialist is developing a daily ETL workflow containing multiple ETL jobs.
The workflow consists of the following processes
* Start the workflow as soon as data is uploaded to Amazon S3
* When all the datasets are available in Amazon S3, start an ETL job to join the uploaded datasets with multiple terabyte-sized datasets already stored in Amazon S3
* Store the results of joining datasets in Amazon S3
* If one of the jobs fails, send a notification to the Administrator
Which configuration will meet these requirements?
- A . Use AWS Lambda to trigger an AWS Step Functions workflow to wait for dataset uploads to complete in Amazon S3. Use AWS Glue to join the datasets Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure
- B . Develop the ETL workflow using AWS Lambda to start an Amazon SageMaker notebook instance Use a lifecycle configuration script to join the datasets and persist the results in Amazon S3 Use an
Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure - C . Develop the ETL workflow using AWS Batch to trigger the start of ETL jobs when data is uploaded to Amazon S3 Use AWS Glue to join the datasets in Amazon S3 Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure
- D . Use AWS Lambda to chain other Lambda functions to read and join the datasets in Amazon S3 as soon as the data is uploaded to Amazon S3 Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure
A
Explanation:
To develop a daily ETL workflow containing multiple ETL jobs that can start as soon as data is uploaded to Amazon S3, the best configuration is to use AWS Lambda to trigger an AWS Step Functions workflow to wait for dataset uploads to complete in Amazon S3. Use AWS Glue to join the datasets. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers. You can use Lambda to create functions that respond to events such as data uploads to Amazon S3. You can also use Lambda to invoke other AWS services such as AWS Step Functions and AWS Glue.
AWS Step Functions is a service that lets you coordinate multiple AWS services into serverless workflows. You can use Step Functions to create a state machine that defines the sequence and logic of your ETL workflow. You can also use Step Functions to handle errors and retries, and to monitor the execution status of your workflow.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics. You can use Glue to create and run ETL jobs that can join data from multiple sources in Amazon S3. You can also use Glue to catalog your data and make it searchable and queryable.
Amazon CloudWatch is a service that monitors your AWS resources and applications. You can use CloudWatch to create alarms that trigger actions when a metric or a log event meets a specified threshold. You can also use CloudWatch to send notifications to Amazon Simple Notification Service (SNS) topics, which can then deliver the notifications to subscribers such as email addresses or phone numbers.
Therefore, by using these services together, you can achieve the following benefits:
You can start the ETL workflow as soon as data is uploaded to Amazon S3 by using Lambda functions to trigger Step Functions workflows.
You can wait for all the datasets to be available in Amazon S3 by using Step Functions to poll the S3 buckets and check the data completeness.
You can join the datasets with terabyte-sized datasets in Amazon S3 by using Glue ETL jobs that can scale and parallelize the data processing.
You can store the results of joining datasets in Amazon S3 by using Glue ETL jobs to write the output to S3 buckets.
You can send a notification to the Administrator if one of the jobs fails by using CloudWatch alarms to monitor the Step Functions or Glue metrics and send SNS notifications in case of a failure.
A data engineer at a bank is evaluating a new tabular dataset that includes customer data. The data engineer will use the customer data to create a new model to predict customer behavior. After creating a correlation matrix for the variables, the data engineer notices that many of the 100 features are highly correlated with each other.
Which steps should the data engineer take to address this issue? (Choose two.)
- A . Use a linear-based algorithm to train the model.
- B . Apply principal component analysis (PCA).
- C . Remove a portion of highly correlated features from the dataset.
- D . Apply min-max feature scaling to the dataset.
- E . Apply one-hot encoding category-based variables.
B, C
Explanation:
B) Apply principal component analysis (PCA): PCA is a technique that reduces the dimensionality of a dataset by transforming the original features into a smaller set of new features that capture most of the variance in the data. PCA can help address the issue of multicollinearity, which occurs when some features are highly correlated with each other and can cause problems for some machine learning algorithms. By applying PCA, the data engineer can reduce the number of features and remove the redundancy in the data.
C) Remove a portion of highly correlated features from the dataset: Another way to deal with multicollinearity is to manually remove some of the features that are highly correlated with each other. This can help simplify the model and avoid overfitting. The data engineer can use the correlation matrix to identify the features that have a high correlation coefficient (e.g., above 0.8 or below -0.8) and remove one of them from the dataset.
References: =
Principal Component Analysis: This is a document from AWS that explains what PCA is, how it works, and how to use it with Amazon SageMaker.
Multicollinearity: This is a document from AWS that describes what multicollinearity is, how to detect it, and how to deal with it.
A machine learning (ML) specialist is administering a production Amazon SageMaker endpoint with model monitoring configured. Amazon SageMaker Model Monitor detects violations on the SageMaker endpoint, so the ML specialist retrains the model with the latest dataset. This dataset is statistically representative of the current production traffic. The ML specialist notices that even after deploying the new SageMaker model and running the first monitoring job, the SageMaker endpoint still has violations.
What should the ML specialist do to resolve the violations?
- A . Manually trigger the monitoring job to re-evaluate the SageMaker endpoint traffic sample.
- B . Run the Model Monitor baseline job again on the new training set. Configure Model Monitor to use the new baseline.
- C . Delete the endpoint and recreate it with the original configuration.
- D . Retrain the model again by using a combination of the original training set and the new training set.
B
Explanation:
The ML specialist should run the Model Monitor baseline job again on the new training set and configure Model Monitor to use the new baseline. This is because the baseline job computes the statistics and constraints for the data quality and model quality metrics, which are used to detect violations. If the training set changes, the baseline job should be updated accordingly to reflect the new distribution of the data and the model performance. Otherwise, the old baseline may not be representative of the current production traffic and may cause false alarms or miss violations.
References:
Monitor data and model quality – Amazon SageMaker
Detecting and analyzing incorrect model predictions with Amazon SageMaker Model Monitor and Debugger | AWS Machine Learning Blog
A Machine Learning team runs its own training algorithm on Amazon SageMaker. The training algorithm requires external assets. The team needs to submit both its own algorithm code and algorithm-specific parameters to Amazon SageMaker.
What combination of services should the team use to build a custom algorithm in Amazon SageMaker? (Choose two.)
- A . AWS Secrets Manager
- B . AWS CodeStar
- C . Amazon ECR
- D . Amazon ECS
- E . Amazon S3
C, E
Explanation:
The Machine Learning team wants to use its own training algorithm on Amazon SageMaker, and submit both its own algorithm code and algorithm-specific parameters. The best combination of services to build a custom algorithm in Amazon SageMaker are Amazon ECR and Amazon S3.
Amazon ECR is a fully managed container registry service that allows you to store, manage, and deploy Docker container images. You can use Amazon ECR to create a Docker image that contains your training algorithm code and any dependencies or libraries that it requires. You can also use Amazon ECR to push, pull, and manage your Docker images securely and reliably.
Amazon S3 is a durable, scalable, and secure object storage service that can store any amount and type of data. You can use Amazon S3 to store your training data, model artifacts, and algorithm-specific parameters. You can also use Amazon S3 to access your data and parameters from your training algorithm code, and to write your model output to a specified location.
Therefore, the Machine Learning team can use the following steps to build a custom algorithm in
Amazon SageMaker:
Write the training algorithm code in Python, using the Amazon SageMaker Python SDK or the Amazon SageMaker Containers library to interact with the Amazon SageMaker service. The code should be able to read the input data and parameters from Amazon S3, and write the model output to Amazon S3.
Create a Dockerfile that defines the base image, the dependencies, the environment variables, and the commands to run the training algorithm code. The Dockerfile should also expose the ports that Amazon SageMaker uses to communicate with the container.
Build the Docker image using the Dockerfile, and tag it with a meaningful name and version.
Push the Docker image to Amazon ECR, and note the registry path of the image.
Upload the training data, model artifacts, and algorithm-specific parameters to Amazon S3, and note the S3 URIs of the objects.
Create an Amazon SageMaker training job, using the Amazon SageMaker Python SDK or the AWS CLI. Specify the registry path of the Docker image, the S3 URIs of the input and output data, the algorithm-specific parameters, and other configuration options, such as the instance type, the number of instances, the IAM role, and the hyperparameters.
Monitor the status and logs of the training job, and retrieve the model output from Amazon S3.
References:
Use Your Own Training Algorithms
Amazon ECR – Amazon Web Services
Amazon S3 – Amazon Web Services
A data scientist is training a text classification model by using the Amazon SageMaker built-in BlazingText algorithm. There are 5 classes in the dataset, with 300 samples for category A, 292 samples for category B, 240 samples for category C, 258 samples for category D, and 310 samples for category E.
The data scientist shuffles the data and splits off 10% for testing. After training the model, the data scientist generates confusion matrices for the training and test sets.
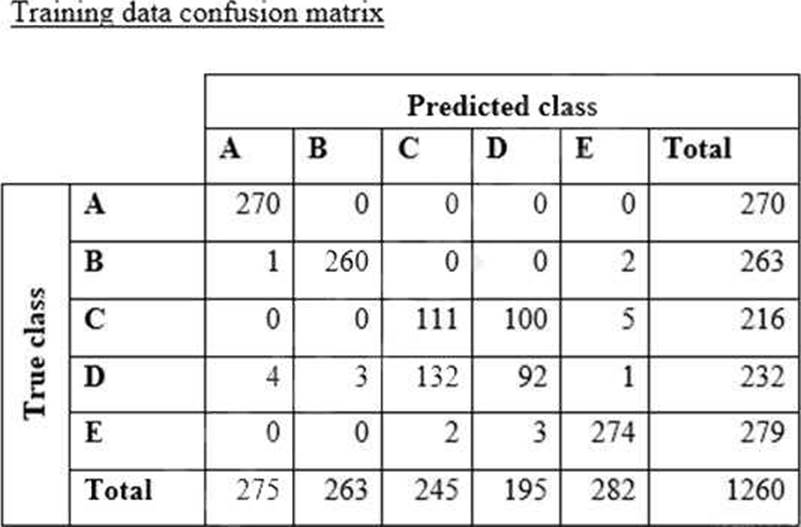
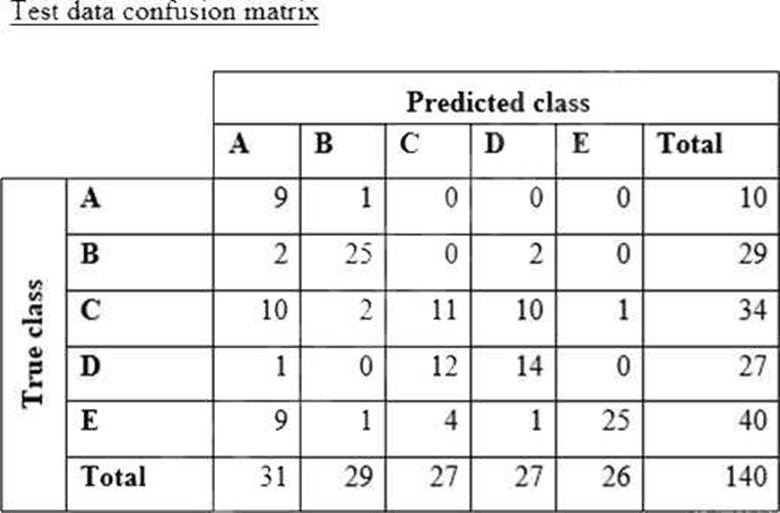
What could the data scientist conclude form these results?
- A . Classes C and D are too similar.
- B . The dataset is too small for holdout cross-validation.
- C . The data distribution is skewed.
- D . The model is overfitting for classes B and E.
D
Explanation:
A confusion matrix is a matrix that summarizes the performance of a machine learning model on a set of test data. It displays the number of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) produced by the model on the test data1. For multi-class classification, the matrix shape will be equal to the number of classes i.e for n classes it will be nXn1. The diagonal values represent the number of correct predictions for each class, and the off-diagonal values represent the number of incorrect predictions for each class1.
The BlazingText algorithm is a proprietary machine learning algorithm for forecasting time series using causal convolutional neural networks (CNNs). BlazingText works best with large datasets containing hundreds of time series. It accepts item metadata, and is the only Forecast algorithm that accepts related time series data without future values2.
From the confusion matrices for the training and test sets, we can observe the following:
The model has a high accuracy on the training set, as most of the diagonal values are high and the off-diagonal values are low. This means that the model is able to learn the patterns and features of the training data well.
However, the model has a lower accuracy on the test set, as some of the diagonal values are lower and some of the off-diagonal values are higher. This means that the model is not able to generalize well to the unseen data and makes more errors.
The model has a particularly high error rate for classes B and E on the test set, as the values of M_22 and M_55 are much lower than the values of M_12, M_21, M_15, M_25, M_51, and M_52. This means that the model is confusing classes B and E with other classes more often than it should.
The model has a relatively low error rate for classes A, C, and D on the test set, as the values of M_11, M_33, and M_44 are high and the values of M_13, M_14, M_23, M_24, M_31, M_32, M_34, M_41, M_42, and M_43 are low. This means that the model is able to distinguish classes A, C, and D from other classes well.
These results indicate that the model is overfitting for classes B and E, meaning that it is memorizing the specific features of these classes in the training data, but failing to capture the general features that are applicable to the test data. Overfitting is a common problem in machine learning, where the model performs well on the training data, but poorly on the test data3. Some possible causes of overfitting are:
The model is too complex or has too many parameters for the given data. This makes the model flexible enough to fit the noise and outliers in the training data, but reduces its ability to generalize to new data.
The data is too small or not representative of the population. This makes the model learn from a limited or biased sample of data, but fails to capture the variability and diversity of the population. The data is imbalanced or skewed. This makes the model learn from a disproportionate or uneven distribution of data, but fails to account for the minority or rare classes. Some possible solutions to prevent or reduce overfitting are:
Simplify the model or use regularization techniques. This reduces the complexity or the number of parameters of the model, and prevents it from fitting the noise and outliers in the data. Regularization techniques, such as L1 or L2 regularization, add a penalty term to the loss function of the model, which shrinks the weights of the model and reduces overfitting3.
Increase the size or diversity of the data. This provides more information and examples for the model to learn from, and increases its ability to generalize to new data. Data augmentation techniques, such as rotation, flipping, cropping, or noise addition, can generate new data from the existing data by applying some transformations3.
Balance or resample the data. This adjusts the distribution or the frequency of the data, and ensures
that the model learns from all classes equally. Resampling techniques, such as oversampling or
undersampling, can create a balanced dataset by increasing or decreasing the number of samples for
each class3.
Reference: Confusion Matrix in Machine Learning – GeeksforGeeks
BlazingText algorithm – Amazon SageMaker
Overfitting and Underfitting in Machine Learning C GeeksforGeeks
A machine learning engineer is building a bird classification model. The engineer randomly separates a dataset into a training dataset and a validation dataset. During the training phase, the model achieves very high accuracy. However, the model did not generalize well during validation of the validation dataset. The engineer realizes that the original dataset was imbalanced.
What should the engineer do to improve the validation accuracy of the model?
- A . Perform stratified sampling on the original dataset.
- B . Acquire additional data about the majority classes in the original dataset.
- C . Use a smaller, randomly sampled version of the training dataset.
- D . Perform systematic sampling on the original dataset.
A
Explanation:
Stratified sampling is a technique that preserves the class distribution of the original dataset when creating a smaller or split dataset. This means that the proportion of examples from each class in the original dataset is maintained in the smaller or split dataset. Stratified sampling can help improve the validation accuracy of the model by ensuring that the validation dataset is representative of the original dataset and not biased towards any class. This can reduce the variance and overfitting of the model and increase its generalization ability. Stratified sampling can be applied to both oversampling and undersampling methods, depending on whether the goal is to increase or decrease the size of the dataset.
The other options are not effective ways to improve the validation accuracy of the model. Acquiring additional data about the majority classes in the original dataset will only increase the imbalance and make the model more biased towards the majority classes. Using a smaller, randomly sampled version of the training dataset will not guarantee that the class distribution is preserved and may result in losing important information from the minority classes. Performing systematic sampling on the original dataset will also not ensure that the class distribution is preserved and may introduce sampling bias if the original dataset is ordered or grouped by class.
References:
• Stratified Sampling for Imbalanced Datasets
• Imbalanced Data
• Tour of Data Sampling Methods for Imbalanced Classification