
Practice Free MLS-C01 Exam Online Questions
A company wants to use automatic speech recognition (ASR) to transcribe messages that are less than 60 seconds long from a voicemail-style application. The company requires the correct identification of 200 unique product names, some of which have unique spellings or pronunciations. The company has 4,000 words of Amazon SageMaker Ground Truth voicemail transcripts it can use to customize the chosen ASR model. The company needs to ensure that everyone can update their customizations multiple times each hour.
Which approach will maximize transcription accuracy during the development phase?
- A . Use a voice-driven Amazon Lex bot to perform the ASR customization. Create customer slots within the bot that specifically identify each of the required product names. Use the Amazon Lex synonym mechanism to provide additional variations of each product name as mis-transcriptions are identified in development.
- B . Use Amazon Transcribe to perform the ASR customization. Analyze the word confidence scores in the transcript, and automatically create or update a custom vocabulary file with any word that has a confidence score below an acceptable threshold value. Use this updated custom vocabulary file in all future transcription tasks.
- C . Create a custom vocabulary file containing each product name with phonetic pronunciations, and use it with Amazon Transcribe to perform the ASR customization. Analyze the transcripts and manually update the custom vocabulary file to include updated or additional entries for those names that are not being correctly identified.
- D . Use the audio transcripts to create a training dataset and build an Amazon Transcribe custom language model. Analyze the transcripts and update the training dataset with a manually corrected version of transcripts where product names are not being transcribed correctly. Create an updated custom language model.
C
Explanation:
The best approach to maximize transcription accuracy during the development phase is to create a custom vocabulary file containing each product name with phonetic pronunciations, and use it with Amazon Transcribe to perform the ASR customization. A custom vocabulary is a list of words and phrases that are likely to appear in your audio input, along with optional information about how to pronounce them. By using a custom vocabulary, you can improve the transcription accuracy of domain-specific terms, such as product names, that may not be recognized by the general vocabulary of Amazon Transcribe. You can also analyze the transcripts and manually update the custom vocabulary file to include updated or additional entries for those names that are not being correctly identified.
The other options are not as effective as option C for the following reasons:
Option A is not suitable because Amazon Lex is a service for building conversational interfaces, not for transcribing voicemail messages. Amazon Lex also has a limit of 100 slots per bot, which is not enough to accommodate the 200 unique product names required by the company.
Option B is not optimal because it relies on the word confidence scores in the transcript, which may not be accurate enough to identify all the mis-transcribed product names. Moreover, automatically creating or updating a custom vocabulary file may introduce errors or inconsistencies in the pronunciation or display of the words.
Option D is not feasible because it requires a large amount of training data to build a custom language model. The company only has 4,000 words of Amazon SageMaker Ground Truth voicemail transcripts, which is not enough to train a robust and reliable custom language model. Additionally, creating and updating a custom language model is a time-consuming and resource-intensive process, which may not be suitable for the development phase where frequent changes are expected.
References:
Amazon Transcribe C Custom Vocabulary
Amazon Transcribe C Custom Language Models
[Amazon Lex C Limits]
A Data Scientist needs to migrate an existing on-premises ETL process to the cloud. The current process runs at regular time intervals and uses PySpark to combine and format multiple large data sources into a single consolidated output for downstream processing
The Data Scientist has been given the following requirements for the cloud solution
* Combine multiple data sources
* Reuse existing PySpark logic
* Run the solution on the existing schedule
* Minimize the number of servers that will need to be managed.
Which architecture should the Data Scientist use to build this solution?
- A . Write the raw data to Amazon S3 Schedule an AWS Lambda function to submit a Spark step to a persistent Amazon EMR cluster based on the existing schedule Use the existing PySpark logic to run the ETL job on the EMR cluster Output the results to a "processed" location m Amazon S3 that is accessible tor downstream use
- B . Write the raw data to Amazon S3 Create an AWS Glue ETL job to perform the ETL processing against the input data Write the ETL job in PySpark to leverage the existing logic Create a new AWS Glue trigger to trigger the ETL job based on the existing schedule Configure the output target of the ETL job to write to a "processed" location in Amazon S3 that is accessible for downstream use.
- C . Write the raw data to Amazon S3 Schedule an AWS Lambda function to run on the existing schedule and process the input data from Amazon S3 Write the Lambda logic in Python and implement the existing PySpartc logic to perform the ETL process Have the Lambda function output the results to a "processed" location in Amazon S3 that is accessible for downstream use
- D . Use Amazon Kinesis Data Analytics to stream the input data and perform realtime SQL queries against the stream to carry out the required transformations within the stream Deliver the output results to a "processed" location in Amazon S3 that is accessible for downstream use
B
Explanation:
The Data Scientist needs to migrate an existing on-premises ETL process to the cloud, using a solution that can combine multiple data sources, reuse existing PySpark logic, run on the existing schedule, and minimize the number of servers that need to be managed. The best architecture for this scenario is to use AWS Glue, which is a serverless data integration service that can create and run ETL jobs on AWS.
AWS Glue can perform the following tasks to meet the requirements:
Combine multiple data sources: AWS Glue can access data from various sources, such as Amazon S3, Amazon RDS, Amazon Redshift, Amazon DynamoDB, and more. AWS Glue can also crawl the data sources and discover their schemas, formats, and partitions, and store them in the AWS Glue Data Catalog, which is a centralized metadata repository for all the data assets.
Reuse existing PySpark logic: AWS Glue supports writing ETL scripts in Python or Scala, using Apache Spark as the underlying execution engine. AWS Glue provides a library of built-in transformations and connectors that can simplify the ETL code. The Data Scientist can write the ETL job in PySpark and leverage the existing logic to perform the data processing.
Run the solution on the existing schedule: AWS Glue can create triggers that can start ETL jobs based on a schedule, an event, or a condition. The Data Scientist can create a new AWS Glue trigger to run the ETL job based on the existing schedule, using a cron expression or a relative time interval.
Minimize the number of servers that need to be managed: AWS Glue is a serverless service, which means that it automatically provisions, configures, scales, and manages the compute resources required to run the ETL jobs. The Data Scientist does not need to worry about setting up, maintaining, or monitoring any servers or clusters for the ETL process.
Therefore, the Data Scientist should use the following architecture to build the cloud solution: Write the raw data to Amazon S3: The Data Scientist can use any method to upload the raw data from the on-premises sources to Amazon S3, such as AWS DataSync, AWS Storage Gateway, AWS Snowball, or AWS Direct Connect. Amazon S3 is a durable, scalable, and secure object storage service that can store any amount and type of data.
Create an AWS Glue ETL job to perform the ETL processing against the input data: The Data Scientist can use the AWS Glue console, AWS Glue API, AWS SDK, or AWS CLI to create and configure an AWS Glue ETL job. The Data Scientist can specify the input and output data sources, the IAM role, the security configuration, the job parameters, and the PySpark script location. The Data Scientist can also use the AWS Glue Studio, which is a graphical interface that can help design, run, and monitor ETL jobs visually.
Write the ETL job in PySpark to leverage the existing logic: The Data Scientist can use a code editor of their choice to write the ETL script in PySpark, using the existing logic to transform the data. The Data Scientist can also use the AWS Glue script editor, which is an integrated development environment (IDE) that can help write, debug, and test the ETL code. The Data Scientist can store the ETL script in Amazon S3 or GitHub, and reference it in the AWS Glue ETL job configuration.
Create a new AWS Glue trigger to trigger the ETL job based on the existing schedule: The Data Scientist can use the AWS Glue console, AWS Glue API, AWS SDK, or AWS CLI to create and configure an AWS Glue trigger. The Data Scientist can specify the name, type, and schedule of the trigger, and associate it with the AWS Glue ETL job. The trigger will start the ETL job according to the defined schedule.
Configure the output target of the ETL job to write to a “processed” location in Amazon S3 that is accessible for downstream use: The Data Scientist can specify the output location of the ETL job in the PySpark script, using the AWS Glue DynamicFrame or Spark DataFrame APIs. The Data Scientist can write the output data to a “processed” location in Amazon S3, using a format such as Parquet, ORC, JSON, or CSV, that is suitable for downstream processing.
References:
What Is AWS Glue?
AWS Glue Components
AWS Glue Studio
AWS Glue Triggers
A Machine Learning Specialist is creating a new natural language processing application that processes a dataset comprised of 1 million sentences. The aim is to then run Word2Vec to generate embeddings of the sentences and enable different types of predictions
Here is an example from the dataset
"The quck BROWN FOX jumps over the lazy dog "
Which of the following are the operations the Specialist needs to perform to correctly sanitize and prepare the data in a repeatable manner? (Select THREE)
- A . Perform part-of-speech tagging and keep the action verb and the nouns only
- B . Normalize all words by making the sentence lowercase
- C . Remove stop words using an English stopword dictionary.
- D . Correct the typography on "quck" to "quick."
- E . One-hot encode all words in the sentence
- F . Tokenize the sentence into words.
B, C, F
Explanation:
To prepare the data for Word2Vec, the Specialist needs to perform some preprocessing steps that can help reduce the noise and complexity of the data, as well as improve the quality of the embeddings.
Some of the common preprocessing steps for Word2Vec are:
Normalizing all words by making the sentence lowercase: This can help reduce the vocabulary size and treat words with different capitalizations as the same word. For example, “Fox” and “fox” should be considered as the same word, not two different words.
Removing stop words using an English stopword dictionary: Stop words are words that are very common and do not carry much semantic meaning, such as “the”, “a”, “and”, etc. Removing them can help focus on the words that are more relevant and informative for the task.
Tokenizing the sentence into words: Tokenization is the process of splitting a sentence into smaller units, such as words or subwords. This is necessary for Word2Vec, as it operates on the word level and requires a list of words as input.
The other options are not necessary or appropriate for Word2Vec:
Performing part-of-speech tagging and keeping the action verb and the nouns only: Part-of-speech tagging is the process of assigning a grammatical category to each word, such as noun, verb, adjective, etc. This can be useful for some natural language processing tasks, but not for Word2Vec, as it can lose some important information and context by discarding other words.
Correcting the typography on “quck” to “quick”: Typo correction can be helpful for some tasks, but not for Word2Vec, as it can introduce errors and inconsistencies in the data. For example, if the typo is intentional or part of a dialect, correcting it can change the meaning or style of the sentence. Moreover, Word2Vec can learn to handle typos and variations in spelling by learning similar embeddings for them.
One-hot encoding all words in the sentence: One-hot encoding is a way of representing words as vectors of 0s and 1s, where only one element is 1 and the rest are 0. The index of the 1 element corresponds to the word’s position in the vocabulary. For example, if the vocabulary is [“cat”, “dog”, “fox”], then “cat” can be encoded as [1, 0, 0], “dog” as [0, 1, 0], and “fox” as [0, 0, 1]. This can be useful for some machine learning models, but not for Word2Vec, as it does not capture the semantic similarity and relationship between words. Word2Vec aims to learn dense and low-dimensional embeddings for words, where similar words have similar vectors.
A Machine Learning Specialist is developing recommendation engine for a photography blog Given a picture, the recommendation engine should show a picture that captures similar objects. The Specialist would like to create a numerical representation feature to perform nearest-neighbor searches
What actions would allow the Specialist to get relevant numerical representations?
- A . Reduce image resolution and use reduced resolution pixel values as features
- B . Use Amazon Mechanical Turk to label image content and create a one-hot representation indicating the presence of specific labels
- C . Run images through a neural network pie-trained on ImageNet, and collect the feature vectors from the penultimate layer
- D . Average colors by channel to obtain three-dimensional representations of images.
C
Explanation:
A neural network pre-trained on ImageNet is a deep learning model that has been trained on a large dataset of images containing 1000 classes of objects. The model can learn to extract high-level features from the images that capture the semantic and visual information of the objects. The penultimate layer of the model is the layer before the final output layer, and it contains a feature vector that represents the input image in a lower-dimensional space. By running images through a pre-trained neural network and collecting the feature vectors from the penultimate layer, the Specialist can obtain relevant numerical representations that can be used for nearest-neighbor searches. The feature vectors can capture the similarity between images based on the presence and appearance of similar objects, and they can be compared using distance metrics such as Euclidean distance or cosine similarity. This approach can enable the recommendation engine to show a picture that captures similar objects to a given picture.
Reference: ImageNet – Wikipedia
How to use a pre-trained neural network to extract features from images | by Rishabh Anand | Analytics Vidhya | Medium
Image Similarity using Deep Ranking | by Aditya Oke | Towards Data Science
A retail company stores 100 GB of daily transactional data in Amazon S3 at periodic intervals. The company wants to identify the schema of the transactional data. The company also wants to perform transformations on the transactional data that is in Amazon S3.
The company wants to use a machine learning (ML) approach to detect fraud in the transformed data.
Which combination of solutions will meet these requirements with the LEAST operational overhead? {Select THREE.)
- A . Use Amazon Athena to scan the data and identify the schema.
- B . Use AWS Glue crawlers to scan the data and identify the schema.
- C . Use Amazon Redshift to store procedures to perform data transformations
- D . Use AWS Glue workflows and AWS Glue jobs to perform data transformations.
- E . Use Amazon Redshift ML to train a model to detect fraud.
- F . Use Amazon Fraud Detector to train a model to detect fraud.
BDF
Explanation:
To meet the requirements with the least operational overhead, the company should use AWS Glue crawlers, AWS Glue workflows and jobs, and Amazon Fraud Detector. AWS Glue crawlers can scan the data in Amazon S3 and identify the schema, which is then stored in the AWS Glue Data Catalog. AWS Glue workflows and jobs can perform data transformations on the data in Amazon S3 using serverless Spark or Python scripts. Amazon Fraud Detector can train a model to detect fraud using the transformed data and the company’s historical fraud labels, and then generate fraud predictions using a simple API call.
Option A is incorrect because Amazon Athena is a serverless query service that can analyze data in Amazon S3 using standard SQL, but it does not perform data transformations or fraud detection. Option C is incorrect because Amazon Redshift is a cloud data warehouse that can store and query data using SQL, but it requires provisioning and managing clusters, which adds operational overhead. Moreover, Amazon Redshift does not provide a built-in fraud detection capability.
Option E is incorrect because Amazon Redshift ML is a feature that allows users to create, train, and deploy machine learning models using SQL commands in Amazon Redshift. However, using Amazon Redshift ML would require loading the data from Amazon S3 to Amazon Redshift, which adds complexity and cost. Also, Amazon Redshift ML does not support fraud detection as a use case.
References:
AWS Glue Crawlers
AWS Glue Workflows and Jobs
Amazon Fraud Detector
A data engineer is preparing a dataset that a retail company will use to predict the number of visitors to stores. The data engineer created an Amazon S3 bucket. The engineer subscribed the S3 bucket to an AWS Data Exchange data product for general economic indicators. The data engineer wants to join the economic indicator data to an existing table in Amazon Athena to merge with the business data. All these transformations must finish running in 30-60 minutes.
Which solution will meet these requirements MOST cost-effectively?
- A . Configure the AWS Data Exchange product as a producer for an Amazon Kinesis data stream. Use an Amazon Kinesis Data Firehose delivery stream to transfer the data to Amazon S3 Run an AWS Glue job that will merge the existing business data with the Athena table. Write the result set back to Amazon S3.
- B . Use an S3 event on the AWS Data Exchange S3 bucket to invoke an AWS Lambda function. Program the Lambda function to use Amazon SageMaker Data Wrangler to merge the existing business data
with the Athena table. Write the result set back to Amazon S3. - C . Use an S3 event on the AWS Data Exchange S3 bucket to invoke an AWS Lambda Function Program the Lambda function to run an AWS Glue job that will merge the existing business data with the Athena table Write the results back to Amazon S3.
- D . Provision an Amazon Redshift cluster. Subscribe to the AWS Data Exchange product and use the product to create an Amazon Redshift Table Merge the data in Amazon Redshift. Write the results back to Amazon S3.
B
Explanation:
The most cost-effective solution is to use an S3 event to trigger a Lambda function that uses SageMaker Data Wrangler to merge the data. This solution avoids the need to provision and manage any additional resources, such as Kinesis streams, Firehose delivery streams, Glue jobs, or Redshift clusters. SageMaker Data Wrangler provides a visual interface to import, prepare, transform, and analyze data from various sources, including AWS Data Exchange products. It can also export the data preparation workflow to a Python script that can be executed by a Lambda function. This solution can meet the time requirement of 30-60 minutes, depending on the size and complexity of the data.
References:
Using Amazon S3 Event Notifications
Prepare ML Data with Amazon SageMaker Data Wrangler AWS Lambda Function
A Machine Learning Specialist is packaging a custom ResNet model into a Docker container so the company can leverage Amazon SageMaker for training. The Specialist is using Amazon EC2 P3 instances to train the model and needs to properly configure the Docker container to leverage the NVIDIA GPUs.
What does the Specialist need to do?
- A . Bundle the NVIDIA drivers with the Docker image.
- B . Build the Docker container to be NVIDIA-Docker compatible.
- C . Organize the Docker container’s file structure to execute on GPU instances.
- D . Set the GPU flag in the Amazon SageMaker CreateTrainingJob request body
B
Explanation:
To leverage the NVIDIA GPUs on Amazon EC2 P3 instances for training a custom ResNet model using Amazon SageMaker, the Machine Learning Specialist needs to build the Docker container to be NVIDIA-Docker compatible. NVIDIA-Docker is a tool that enables GPU-accelerated containers to run on Docker. NVIDIA-Docker can automatically configure the Docker container with the necessary drivers, libraries, and environment variables to access the NVIDIA GPUs. NVIDIA-Docker can also isolate the GPU resources and ensure that each container has exclusive access to a GPU.
To build a Docker container that is NVIDIA-Docker compatible, the Machine Learning Specialist needs to follow these steps:
Install the NVIDIA Container Toolkit on the host machine that runs Docker. This toolkit includes the NVIDIA Container Runtime, which is a modified version of the Docker runtime that supports GPU hardware.
Use the base image provided by NVIDIA as the first line of the Dockerfile. The base image contains the NVIDIA drivers and CUDA toolkit that are required for GPU-accelerated applications. The base image can be specified as FROM nvcr.io/nvidia/cuda:tag, where tag is the version of CUDA and the operating system.
Install the required dependencies and frameworks for the ResNet model, such as PyTorch, torchvision, etc., in the Dockerfile.
Copy the ResNet model code and any other necessary files to the Docker container in the Dockerfile.
Build the Docker image using the docker build command.
Push the Docker image to a repository, such as Amazon Elastic Container Registry (Amazon ECR), using the docker push command.
Specify the Docker image URI and the instance type (ml.p3.xlarge) in the Amazon SageMaker CreateTrainingJob request body.
The other options are not valid or sufficient for building a Docker container that can leverage the NVIDIA GPUs on Amazon EC2 P3 instances. Bundling the NVIDIA drivers with the Docker image is not a good option, as it can cause driver conflicts and compatibility issues with the host machine and the NVIDIA GPUs. Organizing the Docker container’s file structure to execute on GPU instances is not a good option, as it does not ensure that the Docker container can access the NVIDIA GPUs and the CUDA toolkit. Setting the GPU flag in the Amazon SageMaker CreateTrainingJob request body is not a good option, as it does not apply to custom Docker containers, but only to built-in algorithms and frameworks that support GPU instances.
A Data Scientist is building a linear regression model and will use resulting p-values to evaluate the statistical significance of each coefficient. Upon inspection of the dataset, the Data Scientist discovers that most of the features are normally distributed.
The plot of one feature in the dataset is shown in the graphic.
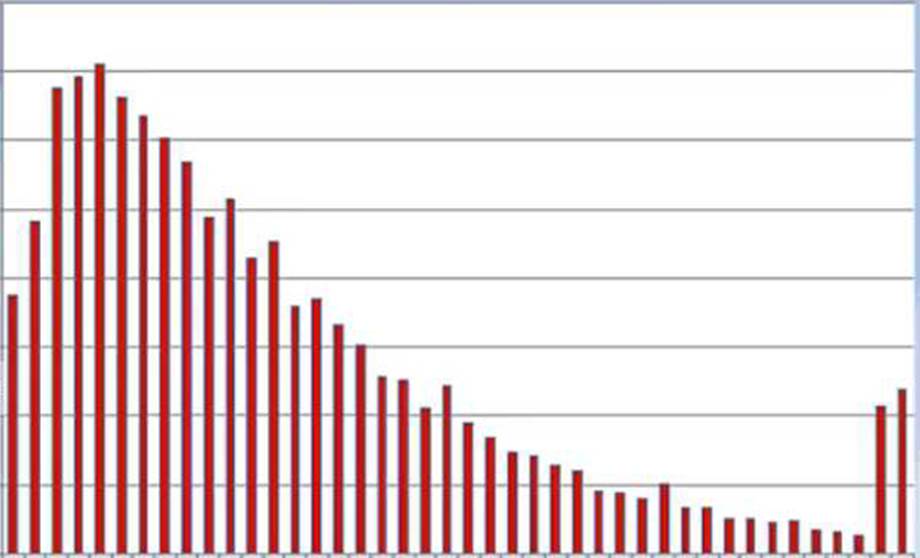
What transformation should the Data Scientist apply to satisfy the statistical assumptions of the linear regression model?
- A . Exponential transformation
- B . Logarithmic transformation
- C . Polynomial transformation
- D . Sinusoidal transformation
B
Explanation:
The plot in the graphic shows a right-skewed distribution, which violates the assumption of normality for linear regression. To correct this, the Data Scientist should apply a logarithmic transformation to the feature. This will help to make the distribution more symmetric and closer to a normal distribution, which is a key assumption for linear regression.
References:
Linear Regression
Linear Regression with Amazon Machine Learning
Machine Learning on AWS
A company needs to quickly make sense of a large amount of data and gain insight from it. The data is in different formats, the schemas change frequently, and new data sources are added regularly. The company wants to use AWS services to explore multiple data sources, suggest schemas, and enrich and transform the data. The solution should require the least possible coding effort for the data flows and the least possible infrastructure management.
Which combination of AWS services will meet these requirements?
- A . Amazon EMR for data discovery, enrichment, and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL Amazon QuickSight for reporting and getting insights - B . Amazon Kinesis Data Analytics for data ingestion
Amazon EMR for data discovery, enrichment, and transformation Amazon Redshift for querying and analyzing the results in Amazon S3 - C . AWS Glue for data discovery, enrichment, and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL Amazon QuickSight for reporting and getting insights - D . AWS Data Pipeline for data transfer
AWS Step Functions for orchestrating AWS Lambda jobs for data discovery, enrichment, and transformation
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL Amazon QuickSight for reporting and getting insights
C
Explanation:
The best combination of AWS services to meet the requirements of data discovery, enrichment, transformation, querying, analysis, and reporting with the least coding and infrastructure management is AWS Glue, Amazon Athena, and Amazon QuickSight.
These services are:
AWS Glue for data discovery, enrichment, and transformation. AWS Glue is a serverless data integration service that automatically crawls, catalogs, and prepares data from various sources and formats. It also provides a visual interface called AWS Glue DataBrew that allows users to apply over 250 transformations to clean, normalize, and enrich data without writing code1
Amazon Athena for querying and analyzing the results in Amazon S3 using standard SQL. Amazon Athena is a serverless interactive query service that allows users to analyze data in Amazon S3 using standard SQL. It supports a variety of data formats, such as CSV, JSON, ORC, Parquet, and Avro. It also integrates with AWS Glue Data Catalog to provide a unified view of the data sources and schemas2 Amazon QuickSight for reporting and getting insights. Amazon QuickSight is a serverless business intelligence service that allows users to create and share interactive dashboards and reports. It also provides ML-powered features, such as anomaly detection, forecasting, and natural language queries, to help users discover hidden insights from their data3
The other options are not suitable because they either require more coding effort, more infrastructure management, or do not support the desired use cases. For example:
Option A uses Amazon EMR for data discovery, enrichment, and transformation. Amazon EMR is a managed cluster platform that runs Apache Spark, Apache Hive, and other open-source frameworks for big data processing. It requires users to write code in languages such as Python, Scala, or SQL to perform data integration tasks. It also requires users to provision, configure, and scale the clusters according to their needs4
Option B uses Amazon Kinesis Data Analytics for data ingestion. Amazon Kinesis Data Analytics is a service that allows users to process streaming data in real time using SQL or Apache Flink. It is not suitable for data discovery, enrichment, and transformation, which are typically batch-oriented tasks. It also requires users to write code to define the data processing logic and the output destination5
Option D uses AWS Data Pipeline for data transfer and AWS Step Functions for orchestrating AWS Lambda jobs for data discovery, enrichment, and transformation. AWS Data Pipeline is a service that helps users move data between AWS services and on-premises data sources. AWS Step Functions is a service that helps users coordinate multiple AWS services into workflows. AWS Lambda is a service that lets users run code without provisioning or managing servers. These services require users to write code to define the data sources, destinations, transformations, and workflows. They also require users to manage the scalability, performance, and reliability of the data pipelines.
Reference:
1: AWS Glue – Data Integration Service – Amazon Web Services
2: Amazon Athena C Interactive SQL Query Service – AWS
3: Amazon QuickSight – Business Intelligence Service – AWS
4: Amazon EMR – Amazon Web Services
5: Amazon Kinesis Data Analytics – Amazon Web Services
: AWS Data Pipeline – Amazon Web Services
: AWS Step Functions – Amazon Web Services
: AWS Lambda – Amazon Web Services
A Machine Learning Specialist is working with a large cybersecurily company that manages security events in real time for companies around the world. The cybersecurity company wants to design a solution that will allow it to use machine learning to score malicious events as anomalies on the data as it is being ingested. The company also wants be able to save the results in its data lake for later processing and analysis
What is the MOST efficient way to accomplish these tasks?
- A . Ingest the data using Amazon Kinesis Data Firehose, and use Amazon Kinesis Data Analytics Random Cut Forest (RCF) for anomaly detection Then use Kinesis Data Firehose to stream the results to Amazon S3
- B . Ingest the data into Apache Spark Streaming using Amazon EMR. and use Spark MLlib with k-means to perform anomaly detection Then store the results in an Apache Hadoop Distributed File System (HDFS) using Amazon EMR with a replication factor of three as the data lake
- C . Ingest the data and store it in Amazon S3 Use AWS Batch along with the AWS Deep Learning AMIs to train a k-means model using TensorFlow on the data in Amazon S3.
- D . Ingest the data and store it in Amazon S3. Have an AWS Glue job that is triggered on demand transform the new data Then use the built-in Random Cut Forest (RCF) model within Amazon SageMaker to detect anomalies in the data
A
Explanation:
Amazon Kinesis Data Firehose is a fully managed service that can capture, transform, and load streaming data into AWS data stores, such as Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk. It can also invoke AWS Lambda functions to perform custom transformations on the data. Amazon Kinesis Data Analytics is a service that can analyze streaming data in real time using SQL or Apache Flink applications. It can also use machine learning algorithms, such as Random Cut Forest (RCF), to perform anomaly detection on streaming data. RCF is an unsupervised learning algorithm that assigns an anomaly score to each data point based on how different it is from the rest of the data. By using Kinesis Data Firehose and Kinesis Data Analytics, the cybersecurity company can ingest the data in real time, score the malicious events as anomalies, and stream the results to Amazon S3, which can serve as a data lake for later processing and analysis. This is the most efficient way to accomplish these tasks, as it does not require any additional infrastructure, coding, or training.
References:
Amazon Kinesis Data Firehose – Amazon Web Services
Amazon Kinesis Data Analytics – Amazon Web Services
Anomaly Detection with Amazon Kinesis Data Analytics – Amazon Web Services [AWS Certified Machine Learning – Specialty Sample Questions]