
Practice Free MLS-C01 Exam Online Questions
A Data Scientist wants to gain real-time insights into a data stream of GZIP files.
Which solution would allow the use of SQL to query the stream with the LEAST latency?
- A . Amazon Kinesis Data Analytics with an AWS Lambda function to transform the data.
- B . AWS Glue with a custom ETL script to transform the data.
- C . An Amazon Kinesis Client Library to transform the data and save it to an Amazon ES cluster.
- D . Amazon Kinesis Data Firehose to transform the data and put it into an Amazon S3 bucket.
A
Explanation:
Amazon Kinesis Data Analytics is a service that enables you to analyze streaming data in real time using SQL or Apache Flink applications. You can use Kinesis Data Analytics to process and gain insights from data streams such as web logs, clickstreams, IoT data, and more.
To use SQL to query a data stream of GZIP files, you need to first transform the data into a format that Kinesis Data Analytics can understand, such as JSON, CSV, or Apache Parquet. You can use an AWS Lambda function to perform this transformation and send the output to a Kinesis data stream that is connected to your Kinesis Data Analytics application. This way, you can use SQL to query the stream with the least latency, as Lambda functions are triggered in near real time by the incoming data and Kinesis Data Analytics can process the data as soon as it arrives.
The other options are not optimal for this scenario, as they introduce more latency or complexity.
AWS Glue is a serverless data integration service that can perform ETL (extract, transform, and load) tasks on data sources, but it is not designed for real-time streaming data analysis. An Amazon Kinesis Client Library is a Java library that enables you to build custom applications that process data from Kinesis data streams, but it requires more coding and configuration than using a Lambda function.
Amazon Kinesis Data Firehose is a service that can deliver streaming data to destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch Service, and Splunk, but it does not support SQL queries on the data.
References:
What Is Amazon Kinesis Data Analytics for SQL Applications? Using AWS Lambda with Amazon Kinesis Data Streams Using AWS Lambda with Amazon Kinesis Data Firehose
A network security vendor needs to ingest telemetry data from thousands of endpoints that run all over the world. The data is transmitted every 30 seconds in the form of records that contain 50 fields. Each record is up to 1 KB in size. The security vendor uses Amazon Kinesis Data Streams to ingest the data. The vendor requires hourly summaries of the records that Kinesis Data Streams ingests. The vendor will use Amazon Athena to query the records and to generate the summaries. The Athena queries will target 7 to 12 of the available data fields.
Which solution will meet these requirements with the LEAST amount of customization to transform and store the ingested data?
- A . Use AWS Lambda to read and aggregate the data hourly. Transform the data and store it in Amazon S3 by using Amazon Kinesis Data Firehose.
- B . Use Amazon Kinesis Data Firehose to read and aggregate the data hourly. Transform the data and store it in Amazon S3 by using a short-lived Amazon EMR cluster.
- C . Use Amazon Kinesis Data Analytics to read and aggregate the data hourly. Transform the data and store it in Amazon S3 by using Amazon Kinesis Data Firehose.
- D . Use Amazon Kinesis Data Firehose to read and aggregate the data hourly. Transform the data and store it in Amazon S3 by using AWS Lambda.
C
Explanation:
The solution that will meet the requirements with the least amount of customization to transform and store the ingested data is to use Amazon Kinesis Data Analytics to read and aggregate the data hourly, transform the data and store it in Amazon S3 by using Amazon Kinesis Data Firehose. This solution leverages the built-in features of Kinesis Data Analytics to perform SQL queries on streaming data and generate hourly summaries. Kinesis Data Analytics can also output the transformed data to Kinesis Data Firehose, which can then deliver the data to S3 in a specified format and partitioning scheme. This solution does not require any custom code or additional infrastructure to process the data. The other solutions either require more customization (such as using Lambda or EMR) or do not meet the requirement of aggregating the data hourly (such as using Lambda to read the data from Kinesis Data Streams).
References:
1: Boosting Resiliency with an ML-based Telemetry Analytics Architecture | AWS Architecture Blog
2: AWS Cloud Data Ingestion Patterns and Practices
3: IoT ingestion and Machine Learning analytics pipeline with AWS IoT …
4: AWS IoT Data Ingestion Simplified 101: The Complete Guide – Hevo Data
A social media company wants to develop a machine learning (ML) model to detect Inappropriate or offensive content in images. The company has collected a large dataset of labeled images and plans to use the built-in Amazon SageMaker image classification algorithm to train the model. The company also intends to use SageMaker pipe mode to speed up the training.
…company splits the dataset into training, validation, and testing datasets. The company stores the training and validation images in folders that are named Training and Validation, respectively. The folder …ain subfolders that correspond to the names of the dataset classes. The company resizes the images to the same sue and generates two input manifest files named training.1st and validation.1st, for the ..ing dataset and the validation dataset. respectively. Finally, the company creates two separate Amazon S3 buckets for uploads of the training dataset and the validation dataset.
…h additional data preparation steps should the company take before uploading the files to Amazon S3?
- A . Generate two Apache Parquet files, training.parquet and validation.parquet. by reading the images into a Pandas data frame and storing the data frame as a Parquet file. Upload the Parquet files to the training S3 bucket
- B . Compress the training and validation directories by using the Snappy compression library Upload the manifest and compressed files to the training S3 bucket
- C . Compress the training and validation directories by using the gzip compression library. Upload the manifest and compressed files to the training S3 bucket.
- D . Generate two RecordIO files, training rec and validation.rec. from the manifest files by using the im2rec Apache MXNet utility tool. Upload the RecordlO files to the training S3 bucket.
D
Explanation:
The SageMaker image classification algorithm supports both RecordIO and image content types for training in file mode, and supports the RecordIO content type for training in pipe mode1. However, the algorithm also supports training in pipe mode using the image files without creating RecordIO files, by using the augmented manifest format2. In this case, the company should generate
A global financial company is using machine learning to automate its loan approval process. The company has a dataset of customer information. The dataset contains some categorical fields, such as customer location by city and housing status. The dataset also includes financial fields in different units, such as account balances in US dollars and monthly interest in US cents.
The company’s data scientists are using a gradient boosting regression model to infer the credit score for each customer. The model has a training accuracy of 99% and a testing accuracy of 75%. The data scientists want to improve the model’s testing accuracy.
Which process will improve the testing accuracy the MOST?
- A . Use a one-hot encoder for the categorical fields in the dataset. Perform standardization on the financial fields in the dataset. Apply L1 regularization to the data.
- B . Use tokenization of the categorical fields in the dataset. Perform binning on the financial fields in
the dataset. Remove the outliers in the data by using the z-score. - C . Use a label encoder for the categorical fields in the dataset. Perform L1 regularization on the financial fields in the dataset. Apply L2 regularization to the data.
- D . Use a logarithm transformation on the categorical fields in the dataset. Perform binning on the financial fields in the dataset. Use imputation to populate missing values in the dataset.
A
Explanation:
The question is about improving the testing accuracy of a gradient boosting regression model. The testing accuracy is much lower than the training accuracy, which indicates that the model is overfitting the training data. To reduce overfitting, the following steps are recommended:
Use a one-hot encoder for the categorical fields in the dataset. This will create binary features for each category and avoid imposing an ordinal relationship among them. This can help the model learn the patterns better and generalize to unseen data.
Perform standardization on the financial fields in the dataset. This will scale the features to have zero mean and unit variance, which can improve the convergence and performance of the model. This can also help the model handle features with different units and ranges.
Apply L1 regularization to the data. This will add a penalty term to the loss function that is proportional to the absolute value of the coefficients. This can help the model reduce the complexity and select the most relevant features by shrinking the coefficients of less important features to zero.
References:
1: AWS Machine Learning Specialty Exam Guide
2: AWS Machine Learning Specialty Course
3: AWS Machine Learning Blog
A wildlife research company has a set of images of lions and cheetahs. The company created a dataset of the images. The company labeled each image with a binary label that indicates whether an image contains a lion or cheetah. The company wants to train a model to identify whether new images contain a lion or cheetah.
…. Dh Amazon SageMaker algorithm will meet this requirement?
- A . XGBoost
- B . Image Classification – TensorFlow
- C . Object Detection – TensorFlow
- D . Semantic segmentation – MXNet
B
Explanation:
The best Amazon SageMaker algorithm for this task is Image Classification – TensorFlow. This algorithm is a supervised learning algorithm that supports transfer learning with many pretrained models from the TensorFlow Hub. Transfer learning allows the company to fine-tune one of the available pretrained models on their own dataset, even if a large amount of image data is not available. The image classification algorithm takes an image as input and outputs a probability for each provided class label. The company can choose from a variety of models, such as MobileNet, ResNet, or Inception, depending on their accuracy and speed requirements. The algorithm also supports distributed training, data augmentation, and hyperparameter tuning.
References:
Image Classification – TensorFlow – Amazon SageMaker
Amazon SageMaker Provides New Built-in TensorFlow Image Classification Algorithm Image Classification with ResNet :: Amazon SageMaker Workshop Image classification on Amazon SageMaker | by Julien Simon – Medium
An online store is predicting future book sales by using a linear regression model that is based on past sales data. The data includes duration, a numerical feature that represents the number of days that a book has been listed in the online store. A data scientist performs an exploratory data analysis and discovers that the relationship between book sales and duration is skewed and non-linear.
Which data transformation step should the data scientist take to improve the predictions of the model?
- A . One-hot encoding
- B . Cartesian product transformation
- C . Quantile binning
- D . Normalization
C
Explanation:
Quantile binning is a data transformation technique that can be used to handle skewed and non-linear numerical features. It divides the range of a feature into equal-sized bins based on the percentiles of the data. Each bin is assigned a numerical value that represents the midpoint of the bin. This way, the feature values are transformed into a more uniform distribution that can improve the performance of linear models. Quantile binning can also reduce the impact of outliers and noise in the data.
One-hot encoding, Cartesian product transformation, and normalization are not suitable for this scenario. One-hot encoding is used to transform categorical features into binary features. Cartesian product transformation is used to create new features by combining existing features. Normalization is used to scale numerical features to a standard range, but it does not change the shape of the distribution.
References:
Data Transformations for Machine Learning
Quantile Binning Transformation
A company has an ecommerce website with a product recommendation engine built in TensorFlow. The recommendation engine endpoint is hosted by Amazon SageMaker. Three compute-optimized instances support the expected peak load of the website.
Response times on the product recommendation page are increasing at the beginning of each month. Some users are encountering errors. The website receives the majority of its traffic between 8 AM and 6 PM on weekdays in a single time zone.
Which of the following options are the MOST effective in solving the issue while keeping costs to a minimum? (Choose two.)
- A . Configure the endpoint to use Amazon Elastic Inference (EI) accelerators.
- B . Create a new endpoint configuration with two production variants.
- C . Configure the endpoint to automatically scale with the Invocations Per Instance metric.
- D . Deploy a second instance pool to support a blue/green deployment of models.
- E . Reconfigure the endpoint to use burstable instances.
A, C
Explanation:
The solution A and C are the most effective in solving the issue while keeping costs to a minimum.
The solution A and C involve the following steps:
Configure the endpoint to use Amazon Elastic Inference (EI) accelerators. This will enable the company to reduce the cost and latency of running TensorFlow inference on SageMaker. Amazon EI provides GPU-powered acceleration for deep learning models without requiring the use of GPU instances. Amazon EI can attach to any SageMaker instance type and provide the right amount of acceleration based on the workload1.
Configure the endpoint to automatically scale with the Invocations Per Instance metric. This will enable the company to adjust the number of instances based on the demand and traffic patterns of the website. The Invocations Per Instance metric measures the average number of requests that each instance processes over a period of time. By using this metric, the company can scale out the endpoint when the load increases and scale in when the load decreases. This can improve the response time and availability of the product recommendation engine2. The other options are not suitable because:
Option B: Creating a new endpoint configuration with two production variants will not solve the issue of increasing response time and errors. Production variants are used to split the traffic between different models or versions of the same model. They can be useful for testing, updating, or A/B testing models. However, they do not provide any scaling or acceleration benefits for the inference workload3.
Option D: Deploying a second instance pool to support a blue/green deployment of models will not solve the issue of increasing response time and errors. Blue/green deployment is a technique for updating models without downtime or disruption. It involves creating a new endpoint configuration with a different instance pool and model version, and then shifting the traffic from the old endpoint to the new endpoint gradually. However, this technique does not provide any scaling or acceleration benefits for the inference workload4.
Option E: Reconfiguring the endpoint to use burstable instances will not solve the issue of increasing response time and errors. Burstable instances are instances that provide a baseline level of CPU performance with the ability to burst above the baseline when needed. They can be useful for workloads that have moderate CPU utilization and occasional spikes. However, they are not suitable for workloads that have high and consistent CPU utilization, such as the product recommendation engine. Moreover, burstable instances may incur additional charges when they exceed their CPU credits5.
References:
1: Amazon Elastic Inference
2: How to Scale Amazon SageMaker Endpoints
3: Deploying Models to Amazon SageMaker Hosting Services
4: Updating Models in Amazon SageMaker Hosting Services
5: Burstable Performance Instances
A manufacturing company uses machine learning (ML) models to detect quality issues. The models use images that are taken of the company’s product at the end of each production step. The company has thousands of machines at the production site that generate one image per second on average. The company ran a successful pilot with a single manufacturing machine. For the pilot, ML specialists used an industrial PC that ran AWS IoT Greengrass with a long-running AWS Lambda function that uploaded the images to Amazon S3. The uploaded images invoked a Lambda function that was written in Python to perform inference by using an Amazon SageMaker endpoint that ran a custom model. The inference results were forwarded back to a web service that was hosted at the production site to prevent faulty products from being shipped.
The company scaled the solution out to all manufacturing machines by installing similarly configured industrial PCs on each production machine. However, latency for predictions increased beyond acceptable limits. Analysis shows that the internet connection is at its capacity limit.
How can the company resolve this issue MOST cost-effectively?
- A . Set up a 10 Gbps AWS Direct Connect connection between the production site and the nearest AWS Region. Use the Direct Connect connection to upload the images. Increase the size of the instances and the number of instances that are used by the SageMaker endpoint.
- B . Extend the long-running Lambda function that runs on AWS IoT Greengrass to compress the images and upload the compressed files to Amazon S3. Decompress the files by using a separate Lambda function that invokes the existing Lambda function to run the inference pipeline.
- C . Use auto scaling for SageMaker. Set up an AWS Direct Connect connection between the production site and the nearest AWS Region. Use the Direct Connect connection to upload the images.
- D . Deploy the Lambda function and the ML models onto the AWS IoT Greengrass core that is running on the industrial PCs that are installed on each machine. Extend the long-running Lambda function that runs on AWS IoT Greengrass to invoke the Lambda function with the captured images and run the inference on the edge component that forwards the results directly to the web service.
D
Explanation:
The best option is to deploy the Lambda function and the ML models onto the AWS IoT Greengrass core that is running on the industrial PCs that are installed on each machine. This way, the inference can be performed locally on the edge devices, without the need to upload the images to Amazon S3 and invoke the SageMaker endpoint. This will reduce the latency and the network bandwidth consumption. The long-running Lambda function can be extended to invoke the Lambda function with the captured images and run the inference on the edge component that forwards the results directly to the web service. This will also simplify the architecture and eliminate the dependency on the internet connection.
Option A is not cost-effective, as it requires setting up a 10 Gbps AWS Direct Connect connection and increasing the size and number of instances for the SageMaker endpoint. This will increase the operational costs and complexity.
Option B is not optimal, as it still requires uploading the images to Amazon S3 and invoking the SageMaker endpoint. Compressing and decompressing the images will add additional processing overhead and latency.
Option C is not sufficient, as it still requires uploading the images to Amazon S3 and invoking the SageMaker endpoint. Auto scaling for SageMaker will help to handle the increased workload, but it will not reduce the latency or the network bandwidth consumption. Setting up an AWS Direct Connect connection will improve the network performance, but it will also increase the operational costs and complexity.
References:
AWS IoT Greengrass
Deploying Machine Learning Models to Edge Devices
AWS Certified Machine Learning – Specialty Exam Guide
A credit card company wants to build a credit scoring model to help predict whether a new credit card applicant will default on a credit card payment. The company has collected data from a large number of sources with thousands of raw attributes. Early experiments to train a classification model revealed that many attributes are highly correlated, the large number of features slows down the training speed significantly, and that there are some overfitting issues.
The Data Scientist on this project would like to speed up the model training time without losing a lot of
information from the original dataset.
Which feature engineering technique should the Data Scientist use to meet the objectives?
- A . Run self-correlation on all features and remove highly correlated features
- B . Normalize all numerical values to be between 0 and 1
- C . Use an autoencoder or principal component analysis (PCA) to replace original features with new features
- D . Cluster raw data using k-means and use sample data from each cluster to build a new dataset
C
Explanation:
The best feature engineering technique to speed up the model training time without losing a lot of information from the original dataset is to use an autoencoder or principal component analysis (PCA) to replace original features with new features. An autoencoder is a type of neural network that learns a compressed representation of the input data, called the latent space, by minimizing the reconstruction error between the input and the output. PCA is a statistical technique that reduces the dimensionality of the data by finding a set of orthogonal axes, called the principal components, that capture the maximum variance of the data. Both techniques can help reduce the number of features and remove the noise and redundancy in the data, which can improve the model performance and speed up the training process.
References:
AWS Machine Learning Specialty Exam Guide
AWS Machine Learning Training – Dimensionality Reduction for Machine Learning AWS Machine Learning Training – Deep Learning with Amazon SageMaker
The displayed graph is from a foresting model for testing a time series.
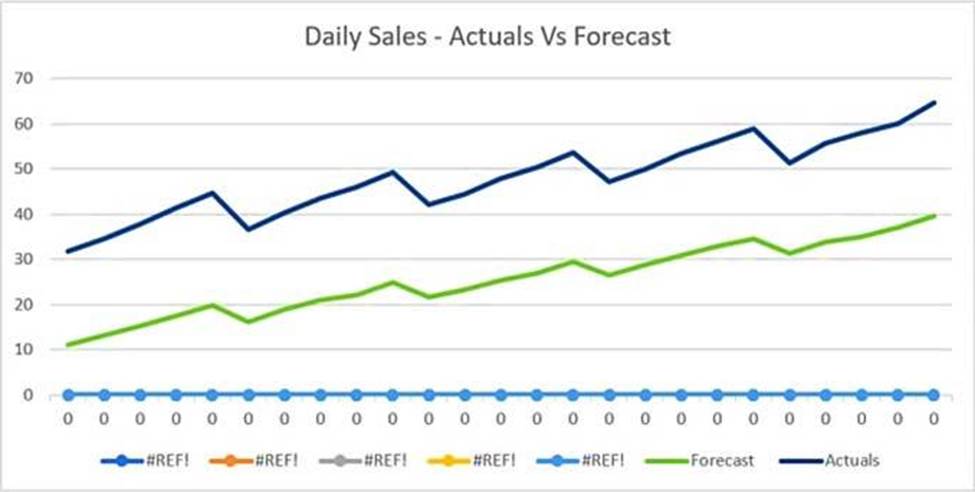
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
- A . The model predicts both the trend and the seasonality well.
- B . The model predicts the trend well, but not the seasonality.
- C . The model predicts the seasonality well, but not the trend.
- D . The model does not predict the trend or the seasonality well.