
Practice Free MLA-C01 Exam Online Questions
You are a data scientist working on a deep learning model to classify medical images for disease detection. The model initially shows high accuracy on the training data but performs poorly on the validation set, indicating signs of overfitting. The dataset is limited in size, and the model is complex, with many parameters. To improve generalization and reduce overfitting, you need to implement appropriate techniques while balancing model complexity and performance.
Given these challenges, which combination of techniques is the MOST LIKELY to help prevent overfitting and improve the model’s performance on unseen data?
- A . Prune the model by removing less important layers and nodes, and use L2 regularization to reduce the magnitude of the model’s weights, preventing overfitting
- B . Use ensembling by combining multiple versions of the same model trained with different random seeds, and apply data augmentation to artificially increase the size of the dataset
- C . Combine data augmentation to increase the diversity of the training data with early stopping to prevent overfitting, and use ensembling to average predictions from multiple models
- D . Apply early stopping to halt training when the validation loss stops improving, and use dropout as a
regularization technique to prevent the model from becoming too reliant on specific neurons
C
Explanation:
Correct option:
Combine data augmentation to increase the diversity of the training data with early stopping to prevent overfitting, and use ensembling to average predictions from multiple models
via – https://aws.amazon.com/what-is/overfitting/
This option combines data augmentation to artificially expand the training dataset, which is crucial when
data is limited, with early stopping to prevent the model from overtraining. Additionally, ensembling helps improve generalization by averaging predictions from multiple models, reducing the likelihood that overfitting in any single model will dominate the final prediction. This combination addresses both data limitations and model overfitting effectively.
Incorrect options:
Apply early stopping to halt training when the validation loss stops improving, and use dropout as a regularization technique to prevent the model from becoming too reliant on specific neurons – Dropout is a form of regularization used in neural networks that reduces overfitting by trimming codependent neurons. Early stopping and dropout are effective techniques for preventing overfitting, particularly in deep learning models. However, while they can help, they may not be sufficient alone, especially when dealing with limited data. Combining these techniques with others, such as data augmentation or ensembling, would provide a more robust solution.
Use ensembling by combining multiple versions of the same model trained with different random seeds, and apply data augmentation to artificially increase the size of the dataset – Ensembling and data augmentation are powerful techniques, but ensembling by combining multiple versions of the same model trained with different random seeds might not provide significant diversity in predictions. A combination of diverse models or more comprehensive techniques might be more effective.
Prune the model by removing less important layers and nodes, and use L2 regularization to reduce the magnitude of the model’s weights, preventing overfitting – Regularization helps prevent linear models from overfitting training data examples by penalizing extreme weight values. L1 regularization reduces the number of features used in the model by pushing the weight of features that would otherwise have very small weights to zero. L1 regularization produces sparse models and reduces the amount of noise in the model. L2 regularization results in smaller overall weight values, which stabilizes the weights when there is high correlation between the features. Pruning and L2 regularization are useful for reducing model complexity and preventing overfitting. However, pruning can sometimes lead to underfitting if not done carefully, and using these techniques alone might not fully address the overfitting issue, especially with limited data.
References:
https://aws.amazon.com/what-is/overfitting/
https://docs.aws.amazon.com/sagemaker/latest/dg/object2vec-hyperparameters.html
https://docs.aws.amazon.com/machine-learning/latest/dg/training-parameters.html
A Machine Learning Specialist is preparing data for training on Amazon SageMaker. The Specialist is using one of the SageMaker built-in algorithms for the training. The dataset is stored in .CSV format and is transformed into a numpy.array, which appears to be negatively affecting the speed of the training.
What should the Specialist do to optimize the data for training on SageMaker?
- A . Use AWS Glue to compress the data into the Apache Parquet format.
- B . Use the SageMaker hyperparameter optimization feature to automatically optimize the data.
- C . Transform the dataset into the RecordIO protobuf format.
- D . Use the SageMaker batch transform feature to transform the training data into a DataFrame.
You are a data scientist working on a machine learning project to predict customer lifetime value (CLV) for an e-commerce company. Before deploying a complex model like a deep neural network, you need to establish a performance baseline to measure the effectiveness of your advanced models. You decide to use Amazon SageMaker to create this baseline efficiently. The goal is to build a simple model that can be easily implemented and provide a reference point for evaluating the performance of more sophisticated models later.
Which of the following approaches is the MOST EFFECTIVE for creating a performance baseline using Amazon SageMaker?
- A . Train a basic linear learner model using Amazon SageMaker, focusing on key features like customer age, purchase frequency, and average order value, to establish a baseline for CLV prediction
- B . Implement SageMaker Autopilot to automatically explore various models and select the best one as the baseline, allowing you to skip manual model selection
- C . Deploy a SageMaker BlazingText model to create word embeddings from customer reviews, which can be used as a baseline for evaluating CLV predictions
- D . Use SageMaker JumpStart to deploy a pre-trained model for customer segmentation, which can serve as a baseline for your CLV prediction model
A
Explanation:
Correct option:
Train a basic linear learner model using Amazon SageMaker, focusing on key features like customer age, purchase frequency, and average order value, to establish a baseline for CLV prediction Using SageMaker’s linear learner algorithm is an effective approach for creating a simple and interpretable baseline. This method allows you to establish a performance benchmark using key features that are directly related to predicting CLV. The linear learner is quick to train and provides a clear point of comparison for more complex models.
Incorrect options:
Use SageMaker JumpStart to deploy a pre-trained model for customer segmentation, which can serve as a baseline for your CLV prediction model – SageMaker JumpStart is great for quickly deploying pre-built models, but a pre-trained customer segmentation model is not directly aligned with predicting CLV. It would not serve as an appropriate baseline for this specific task.
Implement SageMaker Autopilot to automatically explore various models and select the best one as the baseline, allowing you to skip manual model selection – SageMaker Autopilot can automatically explore and select the best models, but it typically aims for optimal performance rather than establishing a simple baseline. While Autopilot is useful, starting with a basic model like linear learner helps you understand the incremental value of more complex models.
Deploy a SageMaker BlazingText model to create word embeddings from customer reviews, which can be used as a baseline for evaluating CLV predictions – BlazingText is designed for natural language processing tasks like text classification and word embedding, which are not directly applicable to creating a CLV prediction baseline. It’s not the right tool for this use case.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/linear-learner.html
https://aws.amazon.com/sagemaker/jumpstart/
https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-automate-model-development.html
Which AWS services are specifically designed to aid in monitoring machine learning models and incorporating human review processes? (Select two)
- A . Amazon SageMaker Feature Store
- B . Amazon SageMaker Ground Truth
- C . Amazon Augmented AI (Amazon A2I)
- D . Amazon SageMaker Data Wrangler
- E . Amazon SageMaker Model Monitor
C, E
Explanation:
Correct options:
Amazon SageMaker Model Monitor
Amazon SageMaker Model Monitor is a service that continuously monitors the quality of machine learning models in production and helps detect data drift, model quality issues, and anomalies. It ensures that models perform as expected and alerts users to issues that might require human intervention.
Amazon Augmented AI (Amazon A2I)
Amazon Augmented AI (A2I) is a service that helps implement human review workflows for machine learning predictions. It integrates human judgment into ML workflows, allowing for reviews and corrections of model predictions, which is critical for applications requiring high accuracy and accountability.
via –
https://docs.aws.amazon.com/sagemaker/latest/dg/a2i-use-augmented-ai-a2i-human-review-loops.html
Incorrect options:
Amazon SageMaker Data Wrangler – Amazon SageMaker Data Wrangler is designed to simplify and streamline the process of data preparation for machine learning, not specifically for monitoring or human review.
Amazon SageMaker Feature Store – Amazon SageMaker Feature Store is a fully managed repository for storing, updating, and retrieving machine learning features. While it aids in managing features used by models, it does not directly handle monitoring or human review processes.
Amazon SageMaker Ground Truth – Amazon SageMaker Ground Truth is used for building highly accurate training datasets for machine learning quickly. It does involve human annotators for labeling data, but it is not specifically designed for monitoring or human review of model predictions in production.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html
https://docs.aws.amazon.com/sagemaker/latest/dg/a2i-use-augmented-ai-a2i-human-review-loops.html
You are a data scientist working on a regression model to predict housing prices in a large metropolitan area. The dataset contains many features, including location, square footage, number of bedrooms, and amenities. After initial testing, you notice that some features have very high variance, leading to overfitting. To address this, you are considering applying regularization to your model. You need to choose between L1 (Lasso) and L2 (Ridge) regularization.
Given the goal of reducing overfitting while also simplifying the model by eliminating less important features, which regularization method should you choose and why?
- A . L2 regularization, because it evenly reduces all feature coefficients, leading to a more stable model
- B . L2 regularization, because it eliminates less important features by setting their coefficients to zero, simplifying the model
- C . L1 regularization, because it can shrink some feature coefficients to zero, effectively performing feature selection
- D . L1 regularization, because it penalizes large coefficients more heavily, making the model less
sensitive to high-variance features
C
Explanation:
Correct option:
L1 regularization, because it can shrink some feature coefficients to zero, effectively performing feature selection
Regularization helps prevent linear models from overfitting training data examples by penalizing extreme weight values. L1 regularization reduces the number of features used in the model by pushing the weight of features that would otherwise have very small weights to zero. L1 regularization produces sparse models and reduces the amount of noise in the model. L2 regularization results in smaller overall weight values, which stabilizes the weights when there is high correlation between the features.
L1 regularization (Lasso) applies a penalty proportional to the absolute value of the coefficients. This characteristic allows it to shrink some coefficients to exactly zero, effectively removing less important features and performing feature selection. This makes L1 regularization particularly useful when you suspect that only a subset of features are truly important.
Incorrect options:
L2 regularization, because it evenly reduces all feature coefficients, leading to a more stable model – L2 regularization (Ridge) penalizes the sum of the squared coefficients, which tends to reduce the coefficients evenly but does not shrink any to zero. While this can lead to a more stable model by controlling high variance, it does not simplify the model by removing features.
L1 regularization, because it penalizes large coefficients more heavily, making the model less sensitive to high-variance features – While L1 regularization does penalize large coefficients, the key advantage here is its ability to perform feature selection by setting some coefficients to zero, not just by reducing high variance.
L2 regularization, because it eliminates less important features by setting their coefficients to zero, simplifying the model – This statement incorrectly attributes L2 regularization with the ability to eliminate features by setting coefficients to zero, which is actually a characteristic of L1 regularization.
References:
https://docs.aws.amazon.com/machine-learning/latest/dg/training-parameters.html
https://docs.aws.amazon.com/sagemaker/latest/dg/ll_hyperparameters.html
You are an ML engineer at a startup that is developing a recommendation engine for an e-commerce platform. The workload involves training models on large datasets and deploying them to serve real-time recommendations to customers. The training jobs are sporadic but require significant computational power, while the inference workloads must handle varying traffic throughout the day. The company is cost-conscious and aims to balance cost efficiency with the need for scalability and performance. Given these requirements, which approach to resource allocation is the MOST SUITABLE for training and inference, and why?
- A . Use on-demand instances for both training and inference to ensure that the company only pays for the compute resources it uses when it needs them, avoiding any upfront commitments
- B . Use on-demand instances for training, allowing the flexibility to scale resources as needed, and use provisioned resources with auto-scaling for inference to handle varying traffic while controlling costs
- C . Use provisioned resources with spot instances for both training and inference to take advantage of the lowest possible costs, accepting the potential for interruptions during workload execution
- D . Use provisioned resources with reserved instances for both training and inference to lock in lower
costs and guarantee resource availability, ensuring predictability in budgeting
B
Explanation:
Correct option:
Use on-demand instances for training, allowing the flexibility to scale resources as needed, and use provisioned resources with auto-scaling for inference to handle varying traffic while controlling costs
Using on-demand instances for training offers flexibility, allowing you to allocate resources only when needed, which is ideal for sporadic training jobs. For inference, provisioned resources with auto-scaling ensure that the system can handle varying traffic while controlling costs, as it can scale down during periods of low demand.
via – https://aws.amazon.com/ec2/pricing/
Incorrect options:
Use on-demand instances for both training and inference to ensure that the company only pays for the compute resources it uses when it needs them, avoiding any upfront commitments – On-demand instances are flexible and ensure that you only pay for what you use, but they can be more expensive over time compared to provisioned resources, especially if workloads are consistent and predictable. This approach may be suboptimal for cost-sensitive long-term use.
Use provisioned resources with reserved instances for both training and inference to lock in lower costs and guarantee resource availability, ensuring predictability in budgeting – Provisioned resources with reserved instances provide cost savings and guaranteed availability but lack the flexibility needed for sporadic training jobs. For inference workloads with fluctuating demand, this approach might not handle traffic spikes efficiently without additional auto-scaling mechanisms.
Use provisioned resources with spot instances for both training and inference to take advantage of the lowest possible costs, accepting the potential for interruptions during workload execution – Spot instances provide significant cost savings but come with the risk of interruptions, which can be problematic for both training and real-time inference workloads. This option is generally better suited for non-critical batch jobs where interruptions can be tolerated.
References:
https://aws.amazon.com/ec2/pricing/
https://aws.amazon.com/ec2/pricing/reserved-instances/
https://aws.amazon.com/ec2/spot/
https://docs.aws.amazon.com/sagemaker/latest/dg/endpoint-auto-scaling-prerequisites.html
What is uncertainty in the context of machine learning?
- A . The clarity of the model’s decision-making process
- B . The speed of the algorithm
- C . The amount of data available for training
- D . An imperfect outcome
D
Explanation:
Uncertainty refers to the imperfect outcomes in machine learning, often arising from imperfect training data.
You are a data scientist at a healthcare startup tasked with developing a machine learning model to predict the likelihood of patients developing a specific chronic disease within the next five years. The dataset available includes patient demographics, medical history, lab results, and lifestyle factors, but it is relatively small, with only 1,000 records. Additionally, the dataset has missing values in some critical features, and the class distribution is highly imbalanced, with only 5% of patients labeled as having developed the disease.
Given the data limitations and the complexity of the problem, which of the following approaches is the MOST LIKELY to determine the feasibility of an ML solution and guide your next steps?
- A . Proceed with training a deep neural network (DNN) model using the available data, as DNNs can handle small datasets by learning complex patterns
- B . Increase the dataset size by generating synthetic data and then train a simple logistic regression model to avoid overfitting
- C . Conduct exploratory data analysis (EDA) to understand the data distribution, address missing values, and assess the class imbalance before determining if an ML solution is feasible
- D . Immediately apply an oversampling technique to balance the dataset, then train an XGBoost model to maximize performance on the minority class
C
Explanation:
Correct option:
Conduct exploratory data analysis (EDA) to understand the data distribution, address missing values, and assess the class imbalance before determining if an ML solution is feasible
Conducting exploratory data analysis (EDA) is the most appropriate first step. EDA allows you to understand the data distribution, identify and address missing values, and assess the extent of the class imbalance. This process helps determine whether the available data is sufficient to build a reliable model and what preprocessing steps might be necessary.
Exploratory data analysis, feature engineering, and operationatizing your data ftow into your ML pipeline with Amazon
SageMaker Data Wrangter
by Phi Nguyen and Roberto Bruno Martins | on 11 DEC 2020 | in Amazon 5agef•1aker, Amazon SageMaker Data Wrangter, Artificial Intelligence | Permalink | Comments | r’+ Share
According to The State of Data Science 2020 survey, data management, exploratory data analysis (EDA), feature selection, and feature engineering accounts for more than 66% of a data scientist’s time (see the following diagram).
Data
loading 19o/
eta
cleansing
The same survey highlights that the top three biggest roadblocks to deploying a model in production are managing dependencies and environments, security, and skill gaps (see the following diagram).
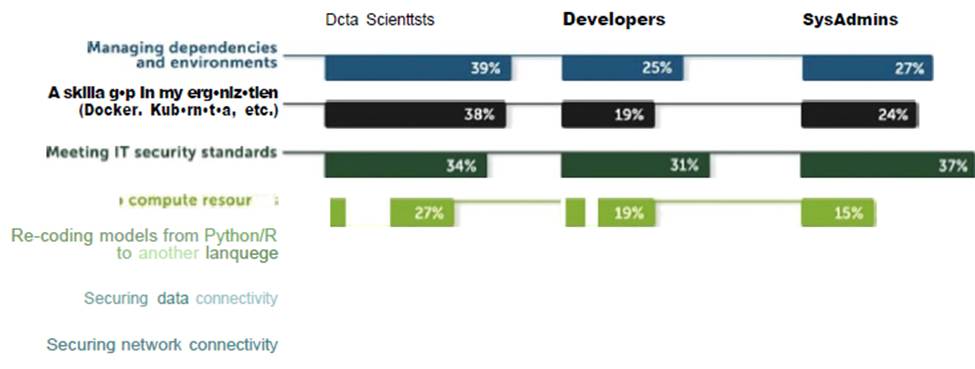
via –
https://aws.amazon.com/blogs/machine-learning/exploratory-data-analysis-feature-engineering-and-operationalizing-your-data-flow-into-your-ml-pipeline-with-amazon-sagemaker-data-wrangler/
Incorrect options:
Proceed with training a deep neural network (DNN) model using the available data, as DNNs can handle small datasets by learning complex patterns – Training a deep neural network on a small dataset is not advisable, as DNNs typically require large amounts of data to perform well and avoid overfitting. Additionally, jumping directly to model training without assessing the data first may lead to poor results.
Increase the dataset size by generating synthetic data and then train a simple logistic regression model to avoid overfitting – While generating synthetic data can help increase the dataset size, it may introduce biases if not done carefully. Additionally, without first understanding the data through EDA, you risk applying the wrong strategy or misinterpreting the results.
Immediately apply an oversampling technique to balance the dataset, then train an XGBoost model to maximize performance on the minority class – Although oversampling can address class imbalance, it’s important to first understand the underlying data issues through EDA. Oversampling should not be the immediate next step without understanding the data quality, feature importance, and potential need for feature engineering.
References:
https://aws.amazon.com/blogs/machine-learning/exploratory-data-analysis-feature-engineering-and-oper
ationalizing-your-data-flow-into-your-ml-pipeline-with-amazon-sagemaker-data-wrangler/
https://aws.amazon.com/blogs/machine-learning/use-amazon-sagemaker-canvas-for-exploratory-data-a
nalysis/
A company specializes in providing personalized product recommendations for e-commerce platforms. You’ve been tasked with developing a solution that can quickly generate high-quality product descriptions, tailor marketing copy based on customer preferences, and analyze customer reviews to identify trends in sentiment. Given the scale of data and the need for flexibility in choosing foundational models, you decide to use an AI service that can integrate seamlessly with your existing AWS infrastructure while also offering managed foundational models from third-party providers.
Which AWS service would best meet your requirements?
- A . Amazon SageMaker
- B . Amazon Rekognition
- C . Amazon Bedrock
- D . Amazon Personalize
C
Explanation:
Correct option:
Amazon Bedrock
Amazon Bedrock is the correct choice for the given use case. It is designed to help businesses build and scale generative AI applications quickly and efficiently. Bedrock offers access to a range of pre-trained foundational models from Amazon and third-party providers like AI21 Labs, Anthropic, and Stability AI. This makes it ideal for tasks such as generating product descriptions, creating marketing copy, and performing sentiment analysis on customer reviews. Bedrock allows users to easily integrate these AI capabilities into their applications without managing the underlying infrastructure, making it a perfect fit for your business needs.
via – https://aws.amazon.com/bedrock/faqs/
Incorrect options:
Amazon Rekognition – Amazon Rekognition is primarily used for image and video analysis, such as detecting objects, text, and activities. It is not designed for generating text or analyzing sentiment based on large datasets, so it would not meet the requirements in this scenario.
Amazon SageMaker – While Amazon SageMaker is a powerful service for building, training, and deploying machine learning models, it requires more manual setup and expertise compared to Amazon Bedrock. SageMaker would be a more appropriate choice if you needed custom models rather than leveraging pre-trained foundational models with generative AI capabilities.
Amazon Personalize – Amazon Personalize is a fully managed machine learning service that uses your data to generate item recommendations for your users. It can also generate user segments based on the users’ affinity for certain items or item metadata. It also lacks the flexibility provided by Bedrock in choosing from various foundational models.
via – https://docs.aws.amazon.com/personalize/latest/dg/what-is-personalize.html
References:
https://aws.amazon.com/bedrock/
https://aws.amazon.com/bedrock/faqs/ https://docs.aws.amazon.com/personalize/latest/dg/what-is-personalize.html