
Practice Free MLA-C01 Exam Online Questions
A data science team is working on a machine learning project that requires them to ingest large volumes of raw data for analysis and feature engineering. The team plans to use Amazon SageMaker for the project, and they need to efficiently ingest the data into a platform where they can perform transformations and store features for future model training.
Which of the following approaches is the most efficient for ingesting data, performing data transformations, and then storing the engineered features?
- A . Load the data into an Amazon RDS database, then use SageMaker Clarify to ingest and transform the data for storing in the Feature Store
- B . Ingest the data into Amazon SageMaker Data Wrangler, perform transformations, and then store the transformed data in SageMaker Feature Store
- C . Ingest the data into AWS Glue for transformations, then store the transformed data in Amazon S3 and load it into Amazon SageMaker using the AWS SDK for Python
- D . Use Amazon S3 to store the raw data, then directly connect SageMaker Feature Store to ingest and transform the data
B
Explanation:
Correct option:
Ingest the data into Amazon SageMaker Data Wrangler, perform transformations, and then store the transformed data in SageMaker Feature Store
This is the optimal approach because SageMaker Data Wrangler is specifically designed to perform data transformations through a visual interface. After the transformations, the cleaned and engineered features can be stored in the SageMaker Feature Store for efficient retrieval during model training.
Incorrect options:
Use Amazon S3 to store the raw data, then directly connect SageMaker Feature Store to ingest and transform the data – While Amazon S3 is commonly used to store raw data, SageMaker Feature Store is designed to store engineered features, not to perform data transformations. A Data Wrangler is needed to transform the data before it’s stored in the Feature Store.
By using feature processing, you can specify your batch data source and feature transformation function (for example, count of product views or time window aggregates) and SageMaker Feature Store transforms the data at the time of ingest into ML features. However, performing complex transformations on petabyte-scale data is most efficient with SageMaker Data Wrangler, which is specifically designed for this purpose.
Ingest the data into AWS Glue for transformations, then store the transformed data in Amazon S3 and load it into Amazon SageMaker using the AWS SDK for Python – This option doesn’t provide a method for storing the engineered features, making it an unsuitable choice.
Load the data into an Amazon RDS database, then use SageMaker Clarify to ingest and transform the data for storing in the Feature Store – Amazon RDS is not necessary for this workflow, and SageMaker Clarify is used for bias detection and explainability rather than data transformation. Data Wrangler is the correct tool for transformations, followed by storing features in the Feature Store.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler.html
https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store.html
You are preparing a dataset for training a machine learning model using SageMaker Data Wrangler. The dataset has several missing values spread across different columns, and these columns contain numeric data. Before training the model, it is essential to handle these missing values to ensure the model performs optimally. The goal is to replace the missing values in each numeric column with the mean of that column.
Which transformation in SageMaker Data Wrangler should you apply to replace the missing values in numeric columns with the mean of those columns?
- A . Encode
- B . Impute
- C . Scale
- D . Drop
B
Explanation:
Correct option:
Impute
Amazon SageMaker Data Wrangler provides numerous ML data transforms to streamline cleaning, transforming, and featurizing your data. When you add a transform, it adds a step to the data flow. Each transform you add modifies your dataset and produces a new dataframe. All subsequent transforms apply to the resulting dataframe.
Use the Impute missing transform to create a new column that contains imputed values where missing values were found in input categorical and numerical data. The configuration depends on your data type. For numeric data, choose an imputing strategy, the strategy used to determine the new value to impute. You can choose to impute the mean (as needed in the use case)or the median over the values that are present in your dataset. Data Wrangler uses the value that it computes to impute the missing values.
For categorical data, Data Wrangler imputes missing values using the most frequent value in the column.
To impute a custom string, use the Fill missing transform instead.
Incorrect options:
Drop – Use the Drop missing option to drop rows that contain missing values from the Input column.
Scale – This action normalizes or standardizes the data but does not handle missing values.
Encode – This action transforms categorical data into numerical data. Encoding categorical data is the process of creating a numerical representation for categories. For example, if your categories are Dog and Cat, you may encode this information into two vectors, [1,0] to represent Dog, and [0,1] to represent Cat. Encoding does not address missing values.
Reference: https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-transform.html
You are a machine learning engineer at a healthcare company responsible for developing and deploying an end-to-end ML workflow for predicting patient readmission rates. The workflow involves data preprocessing, model training, hyperparameter tuning, and deployment. Additionally, the solution must support regular retraining of the model as new data becomes available, with minimal manual intervention. You need to select the right solution to orchestrate this workflow efficiently while ensuring scalability, reliability, and ease of management.
Given these requirements, which of the following options is the MOST SUITABLE for orchestrating your ML workflow?
- A . Implement the entire ML workflow using Amazon SageMaker Pipelines, which provides integrated orchestration for data processing, model training, tuning, and deployment
- B . Use AWS Step Functions to define and orchestrate each step of the ML workflow, integrate with SageMaker for model training and deployment, and leverage AWS Lambda for data preprocessing tasks
- C . Leverage Amazon EC2 instances to manually execute each step of the ML workflow, use Amazon RDS for storing intermediate results, and deploy the model using Amazon SageMaker endpoints
- D . Use AWS Glue for data preprocessing, Amazon SageMaker for model training and tuning, and
manually deploy the model to an Amazon EC2 instance for inference
A
Explanation:
Correct option:
Implement the entire ML workflow using Amazon SageMaker Pipelines, which provides integrated orchestration for data processing, model training, tuning, and deployment
Amazon SageMaker Pipelines is a purpose-built workflow orchestration service to automate machine learning (ML) development. SageMaker Pipelines is specifically designed to orchestrate end-to-end ML workflows, integrating data processing, model training, hyperparameter tuning, and deployment in a seamless manner. It provides built-in versioning, lineage tracking, and support for continuous integration and delivery (CI/CD), making it the best choice for this use case.
via – https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Incorrect options:
Use AWS Step Functions to define and orchestrate each step of the ML workflow, integrate with SageMaker for model training and deployment, and leverage AWS Lambda for data preprocessing tasks – AWS Step Functions is a powerful service for orchestrating workflows, and it can integrate with SageMaker and Lambda. However, using Step Functions for the entire ML workflow adds complexity since it requires coordinating multiple services, whereas SageMaker Pipelines provides a more seamless, integrated solution for ML-specific workflows.
Leverage Amazon EC2 instances to manually execute each step of the ML workflow, use Amazon RDS for storing intermediate results, and deploy the model using Amazon SageMaker endpoints – Manually managing each step of the ML workflow using EC2 instances and RDS is labor-intensive, prone to errors, and not scalable. It also lacks the automation and orchestration capabilities needed for a robust ML workflow.
Use AWS Glue for data preprocessing, Amazon SageMaker for model training and tuning, and manually deploy the model to an Amazon EC2 instance for inference – While using AWS Glue for data preprocessing and SageMaker for training is possible, manually deploying the model on EC2 lacks the orchestration and management features provided by SageMaker Pipelines. This approach also misses out on the integrated tracking, automation, and scalability features offered by SageMaker Pipelines.
Use AWS Glue for data preprocessing, Amazon SageMaker for model training and tuning, and manually deploy the model to an Amazon EC2 instance for inference – While using AWS Glue for data preprocessing and SageMaker for training is possible, manually deploying the model on EC2 lacks the orchestration and management features provided by SageMaker Pipelines. This approach also misses out on the integrated tracking, automation, and scalability features offered by SageMaker Pipelines.
Reference: https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
A machine learning specialist is developing a proof of concept for government users whose primary concern is security. The specialist is using Amazon SageMaker to train a convolutional neural network (CNN) model for a photo classifier application. The specialist wants to protect the data so that it cannot be accessed and transferred to a remote host by malicious code accidentally installed on the training container.
Which action will provide the MOST secure protection?
- A . Encrypt the weights of the CNN model.
- B . Enable network isolation for training jobs.
- C . Remove Amazon S3 access permissions from the SageMaker execution role.
- D . Encrypt the training and validation dataset.
You are a machine learning engineer working for an e-commerce company. You have developed a recommendation model that predicts products customers are likely to buy based on their browsing
history and past purchases. The model initially performs well, but after deploying it in production, you notice two issues: the model’s performance degrades over time as new data is added (catastrophic forgetting) and the model shows signs of overfitting during retraining on updated datasets.
Given these challenges, which of the following strategies is the MOST LIKELY to help prevent overfitting and catastrophic forgetting while maintaining model accuracy?
- A . Reduce the model complexity by decreasing the number of features, apply data augmentation to handle underfitting, and leverage L1 regularization to address catastrophic forgetting
- B . Apply L2 regularization to reduce overfitting, use dropout to prevent underfitting, and retrain the model on the entire dataset periodically to avoid catastrophic forgetting
- C . Use early stopping during training to prevent overfitting, incorporate new data incrementally through transfer learning to mitigate catastrophic forgetting, and apply L1 regularization to ensure feature selection
- D . Regularly update the training dataset with new data, apply L2 regularization to manage overfitting,
and use an ensemble of models to prevent catastrophic forgetting
C
Explanation:
Correct option:
Use early stopping during training to prevent overfitting, incorporate new data incrementally through transfer learning to mitigate catastrophic forgetting, and apply L1 regularization to ensure feature selection
Early stopping is a proven method to prevent overfitting by halting training when the model’s performance on the validation set stops improving. Incorporating new data incrementally through transfer learning helps to mitigate catastrophic forgetting by allowing the model to learn new information while retaining its prior knowledge.
via – https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-early-stopping.html
Regularization helps prevent linear models from overfitting training data examples by penalizing extreme weight values. L1 regularization reduces the number of features used in the model by pushing the weight of features that would otherwise have very small weights to zero. L1 regularization produces sparse models and reduces the amount of noise in the model. L2 regularization results in smaller overall weight values, which stabilizes the weights when there is high correlation between the features.
L1 regularization is beneficial for feature selection, which can improve model generalization and prevent both overfitting and underfitting.
via – https://aws.amazon.com/blogs/machine-learning/automatically-retrain-neural-networks-with-renate/
Incorrect options:
Apply L2 regularization to reduce overfitting, use dropout to prevent underfitting, and retrain the model on the entire dataset periodically to avoid catastrophic forgetting – While L2 regularization is effective for reducing overfitting, using dropout typically addresses overfitting, not underfitting. Retraining the model on the entire dataset periodically may help, but it could still lead to catastrophic forgetting as the model might "forget" previous knowledge when learning from new data.
Reduce the model complexity by decreasing the number of features, apply data augmentation to handle
underfitting, and leverage L1 regularization to address catastrophic forgetting – Reducing model complexity can help with overfitting, but it might lead to underfitting if too many features are removed. Data augmentation is more relevant for addressing overfitting, particularly in image or text data, rather than underfitting. L1 regularization is effective for reducing overfitting, and not for addressing catastrophic forgetting.
Regularly update the training dataset with new data, apply L2 regularization to manage overfitting, and use an ensemble of models to prevent catastrophic forgetting – Regularly updating the dataset can help with model performance over time, but it might not address catastrophic forgetting unless combined with techniques like transfer learning. L2 regularization and ensembling are useful strategies, but ensembling does not specifically prevent catastrophic forgetting.
References:
https://aws.amazon.com/blogs/machine-learning/automatically-retrain-neural-networks-with-renate/
https://docs.aws.amazon.com/machine-learning/latest/dg/training-parameters.html
https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-early-stopping.html
Which solution will meet these requirements?
- A . Use the SageMaker Feature Store GetRecord API with the record identifier.
- B . Use the SageMaker Feature Store BatchGetRecord API with the record identifier. Filter to find the latest record.
- C . Create an Amazon Athena query to retrieve the data from the feature table. Use the write_time value to find the latest record.
- D . Create an Amazon Athena query to retrieve the data from the feature table.
What is the first step in building a machine learning application?
- A . Preparing the data
- B . Training the model
- C . Formulating the problem
- D . Testing the model
C
Explanation:
The first step is to frame the core ML problem(s) in terms of what is observed and what you want the model to predict.
You are a machine learning engineer at a fintech company tasked with developing and deploying an end-to-end machine learning workflow for fraud detection. The workflow involves multiple steps, including data extraction, preprocessing, feature engineering, model training, hyperparameter tuning, and deployment. The company requires the solution to be scalable, support complex dependencies between tasks, and provide robust monitoring and versioning capabilities. Additionally, the workflow needs to integrate seamlessly with existing AWS services.
Which deployment orchestrator is the MOST SUITABLE for managing and automating your ML workflow?
- A . Use AWS Step Functions to build a serverless workflow that integrates with SageMaker for model training and deployment, ensuring scalability and fault tolerance
- B . Use AWS Lambda functions to manually trigger each step of the ML workflow, enabling flexible execution without needing a predefined orchestration tool
- C . Use Amazon SageMaker Pipelines to orchestrate the entire ML workflow, leveraging its built-in integration with SageMaker features like training, tuning, and deployment
- D . Use Apache Airflow to define and manage the workflow with custom DAGs (Directed Acyclic
Graphs), integrating with AWS services through operators and hooks
C
Explanation:
Correct option:
Use Amazon SageMaker Pipelines to orchestrate the entire ML workflow, leveraging its built-in integration with SageMaker features like training, tuning, and deployment
Amazon SageMaker Pipelines is a purpose-built workflow orchestration service to automate machine learning (ML) development.
SageMaker Pipelines is specifically designed for orchestrating ML workflows. It provides native integration with SageMaker features like model training, tuning, and deployment. It also supports versioning, lineage tracking, and automatic execution of workflows, making it the ideal choice for managing end-to-end ML workflows in AWS.
via – https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Incorrect options:
Use Apache Airflow to define and manage the workflow with custom DAGs (Directed Acyclic Graphs), integrating with AWS services through operators and hooks – Apache Airflow is a powerful orchestration tool that allows you to define complex workflows using custom DAGs. However, it requires significant setup and maintenance, and while it can integrate with AWS services, it does not provide the seamless, built-in integration with SageMaker that SageMaker Pipelines offers.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA):
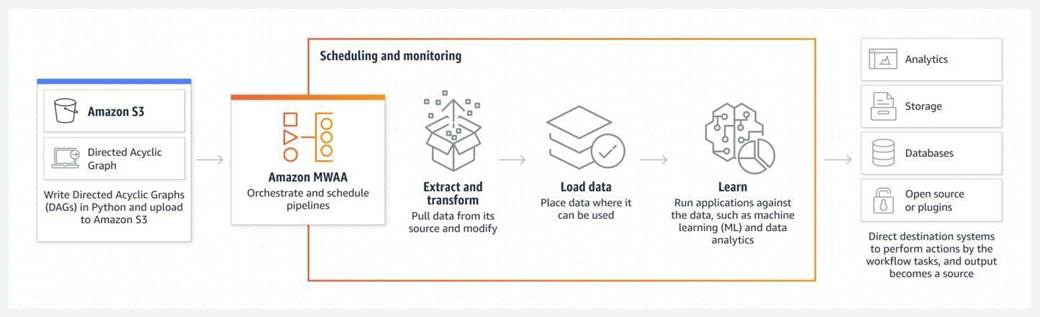
via – https://aws.amazon.com/managed-workflows-for-apache-airflow/
Use AWS Step Functions to build a serverless workflow that integrates with SageMaker for model training and deployment, ensuring scalability and fault tolerance – AWS Step Functions is a serverless orchestration service that can integrate with SageMaker and other AWS services. However, it is more general-purpose and lacks some of the ML-specific features, such as model lineage tracking and hyperparameter tuning, that are built into SageMaker Pipelines.
Use AWS Lambda functions to manually trigger each step of the ML workflow, enabling flexible execution without needing a predefined orchestration tool – AWS Lambda is useful for triggering specific tasks, but manually managing each step of a complex ML workflow without a comprehensive orchestration tool is not scalable or maintainable. It does not provide the task dependency management, monitoring, and versioning required for an end-to-end ML workflow.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html https://aws.amazon.com/managed-workflows-for-apache-airflow/
How do financial institutions use machine learning with mobile check deposits?
- A . To automate logistics
- B . To improve ride-sharing apps
- C . To reduce wait times
- D . To recognize content
D
Explanation:
Financial institutions use AI to recognize content on mobile check deposits.
You are a data scientist at a marketing agency tasked with creating a sentiment analysis model to analyze customer reviews for a new product. The company wants to quickly deploy a solution with minimal training time and development effort. You decide to leverage a pre-trained natural language processing (NLP) model and fine-tune it using a custom dataset of labeled customer reviews. Your team has access to both Amazon Bedrock and SageMaker JumpStart.
Which approach is the MOST APPROPRIATE for fine-tuning the pre-trained model with your custom dataset?
- A . Use SageMaker JumpStart to create a custom container for your pre-trained model and manually implement fine-tuning with TensorFlow
- B . Use SageMaker JumpStart to deploy a pre-trained NLP model and use the built-in fine-tuning functionality with your custom dataset to create a customized sentiment analysis model
- C . Use Amazon Bedrock to train a model from scratch using your custom dataset, as Bedrock is optimized for training large models efficiently
- D . Use Amazon Bedrock to select a foundation model from a third-party provider, then fine-tune the
model directly in the Bedrock interface using your custom dataset
B
Explanation:
Correct option:
Use SageMaker JumpStart to deploy a pre-trained NLP model and use the built-in fine-tuning functionality with your custom dataset to create a customized sentiment analysis model
Amazon Bedrock is the easiest way to build and scale generative AI applications with foundation models. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and
Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Amazon SageMaker JumpStart is a machine learning (ML) hub that can help you accelerate your ML journey. With SageMaker JumpStart, you can evaluate, compare, and select FMs quickly based on pre-defined quality and responsibility metrics to perform tasks like article summarization and image generation. SageMaker JumpStart provides managed infrastructure and tools to accelerate scalable, reliable, and secure model building, training, and deployment of ML models.
Fine-tuning trains a pretrained model on a new dataset without training from scratch. This process, also known as transfer learning, can produce accurate models with smaller datasets and less training time.
SageMaker JumpStart is specifically designed for scenarios like this, where you can quickly deploy a pre-trained model and fine-tune it using your custom dataset. This approach allows you to leverage existing NLP models, reducing both development time and computational resources needed for training from scratch.

via – https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-fine-tune.html
Incorrect options:
Use Amazon Bedrock to select a foundation model from a third-party provider, then fine-tune the model directly in the Bedrock interface using your custom dataset – Amazon Bedrock provides access to foundation models from third-party providers, allowing for easy deployment and integration into
applications. However, as of now, Bedrock does not directly support fine-tuning these models within its interface. Fine-tuning is better suited for SageMaker JumpStart in this scenario.
Use Amazon Bedrock to train a model from scratch using your custom dataset, as Bedrock is optimized for training large models efficiently – Amazon Bedrock is not intended for training models from scratch, especially not for scenarios where fine-tuning a pre-trained model would be more efficient. Bedrock is optimized for deploying and scaling foundation models, not for raw model training.
Use SageMaker JumpStart to create a custom container for your pre-trained model and manually implement fine-tuning with TensorFlow – While it’s possible to create a custom container and manually fine-tune a model, SageMaker JumpStart already offers an integrated solution for fine-tuning pre-trained models without the need for custom containers or manual implementation. This makes it a more efficient and straightforward option for the task at hand.
Reference: https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-fine-tune.html