
Practice Free DP-700 Exam Online Questions
You need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
- A . Schedule a data pipeline that calls other data pipelines.
- B . Schedule a notebook.
- C . Schedule an Apache Spark job.
- D . Schedule multiple data pipelines.
A
Explanation:
The technical requirements specify that:
– Medallion layers must be fully populated sequentially (bronze → silver → gold). Each layer must be populated before the next.
– If any step fails, the process must notify the data engineers.
– Data imports should run simultaneously when possible.
Why Use a Data Pipeline That Calls Other Data Pipelines?
– A data pipeline provides a modular and reusable approach to orchestrating the sequential population of medallion layers.
– By calling other pipelines, each pipeline can focus on populating a specific layer (bronze, silver, or gold), simplifying development and maintenance.
– A parent pipeline can handle:
– Sequential execution of child pipelines.
– Error handling to send email notifications upon failures.
– Parallel execution of tasks where possible (e.g., simultaneous imports into the bronze layer).
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database.
The table contains the following columns:
– BikepointID
– Street
– Neighbourhood
– No_Bikes
– No_Empty_Docks
– Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:

Does this meet the goal?
- A . Yes
- B . no
B
Explanation:
This code does not meet the goal because this is an SQL-like query and cannot be executed in KQL, which is required for the database.
Correct code should look like:

You have a Fabric workspace that contains a warehouse named DW1. DW1 is loaded by using a notebook named Notebook1.
You need to identify which version of Delta was used when Notebook1 was executed.
What should you use?
- A . Real-Time hub
- B . OneLake data hub
- C . the Admin monitoring workspace
- D . Fabric Monitor
- E . the Microsoft Fabric Capacity Metrics app
C
Explanation:
To identify the version of Delta used when Notebook1 was executed, you should use the Admin monitoring workspace. The Admin monitoring workspace allows you to track and monitor detailed information about the execution of notebooks and jobs, including the underlying versions of Delta or other technologies used. It provides insights into execution details, including versions and configurations used during job runs, making it the most appropriate choice for identifying the Delta version used during the execution of Notebook1.
Topic 2, Litware, Inc
Case Study
Overview
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Litware, Inc. is a publishing company that has an online bookstore and several retail bookstores worldwide. Litware also manages an online advertising business for the authors it represents.
Existing Environment. Fabric Environment
Litware has a Fabric workspace named Workspace1. High concurrency is enabled for Workspace1.
The company has a data engineering team that uses Python for data processing.
Existing Environment. Data Processing
The retail bookstores send sales data at the end of each business day, while the online bookstore constantly provides logs and sales data to a central enterprise resource planning (ERP) system.
Litware implements a medallion architecture by using the following three layers: bronze, silver, and gold. The sales data is ingested from the ERP system as Parquet files that land in the Files folder in a lakehouse. Notebooks are used to transform the files in a Delta table for the bronze and silver layers. The gold layer is in a warehouse that has V-Order disabled.
Litware has image files of book covers in Azure Blob Storage. The files are loaded into the Files folder.
Existing Environment. Sales Data
Month-end sales data is processed on the first calendar day of each month. Data that is older than one month never changes.
In the source system, the sales data refreshes every six hours starting at midnight each day.
The sales data is captured in a Dataflow Gen1 dataflow. When the dataflow runs, new and historical data is captured.
The dataflow captures the following fields of the source:
– Sales Date
– Author
– Price
– Units
– SKU
A table named AuthorSales stores the sales data that relates to each author. The table contains a column named AuthorEmail. Authors authenticate to a guest Fabric tenant by using their email address.
Existing Environment. Security Groups
Litware has the following security groups:
– Sales
– Fabric Admins
– Streaming Admins
Existing Environment. Performance Issues
Business users perform ad-hoc queries against the warehouse. The business users indicate that reports against the warehouse sometimes run for two hours and fail to load as expected. Upon further investigation, the data engineering team receives the following error message when the reports fail to load: “The SQL query failed while running.”
The data engineering team wants to debug the issue and find queries that cause more than one failure.
When the authors have new book releases, there is often an increase in sales activity. This increase slows the data ingestion process.
The company’s sales team reports that during the last month, the sales data has NOT been up-to-date when they arrive at work in the morning.
Requirements. Planned Changes
Litware recently signed a contract to receive book reviews. The provider of the reviews exposes the data in Amazon Simple Storage Service (Amazon S3) buckets.
Litware plans to manage Search Engine Optimization (SEO) for the authors. The SEO data will be streamed from a REST API.
Requirements. Version Control
Litware plans to implement a version control solution in Fabric that will use GitHub integration and follow the principle of least privilege.
Requirements. Governance Requirements
To control data platform costs, the data platform must use only Fabric services and items. Additional Azure resources must NOT be provisioned.
Requirements. Data Requirements
Litware identifies the following data requirements:
– Process the SEO data in near-real-time (NRT).
– Make the book reviews available in the lakehouse without making a copy of the data.
– When a new book cover image arrives in the Files folder, process the image as soon as possible.
You need to implement the solution for the book reviews.
Which should you do?
- A . Create a Dataflow Gen2 dataflow.
- B . Create a shortcut.
- C . Enable external data sharing.
- D . Create a data pipeline.
B
Explanation:
The requirement specifies that Litware plans to make the book reviews available in the lakehouse without making a copy of the data. In this case, creating a shortcut in Fabric is the most appropriate solution. A shortcut is a reference to the external data, and it allows Litware to access the book reviews stored in Amazon S3 without duplicating the data into the lakehouse.
You have a Fabric workspace named Workspace1.
You plan to integrate Workspace1 with Azure DevOps.
You will use a Fabric deployment pipeline named deployPipeline1 to deploy items from Workspace1 to higher environment workspaces as part of a medallion architecture. You will run deployPipeline1 by using an API call from an Azure DevOps pipeline.
You need to configure API authentication between Azure DevOps and Fabric.
Which type of authentication should you use?
- A . service principal
- B . Microsoft Entra username and password
- C . managed private endpoint
- D . workspace identity
A
Explanation:
When integrating Azure DevOps with Fabric (Workspace1), using a service principal is the recommended authentication method. A service principal provides a way for applications (such as an Azure DevOps pipeline) to authenticate and interact with resources securely. It allows Azure DevOps to authenticate API calls to Fabric without requiring direct user credentials. This method is ideal for automating tasks such as deploying items through a Fabric deployment pipeline.
You have a Fabric workspace named Workspace1 that contains a data pipeline named Pipeline1 and a lakehouse named Lakehouse1.
You have a deployment pipeline named deployPipeline1 that deploys Workspace1 to Workspace2.
You restructure Workspace1 by adding a folder named Folder1 and moving Pipeline1 to Folder1.
You use deployPipeline1 to deploy Workspace1 to Workspace2.
What occurs to Workspace2?
- A . Folder1 is created, Pipeline1 moves to Folder1, and Lakehouse1 is deployed.
- B . Only Pipeline1 and Lakehouse1 are deployed.
- C . Folder1 is created, and Pipeline1 and Lakehouse1 move to Folder1.
- D . Only Folder1 is created and Pipeline1 moves to Folder1.
A
Explanation:
When you restructure Workspace1 by adding a new folder (Folder1) and moving Pipeline1 into it, deployPipeline1 will deploy the entire structure of Workspace1 to Workspace2, preserving the changes made in Workspace1.
This includes:
Folder1 will be created in Workspace2, mirroring the structure in Workspace1.
Pipeline1 will be moved into Folder1 in Workspace2, maintaining the same folder structure.
Lakehouse1 will be deployed to Workspace2 as it exists in Workspace1.
HOTSPOT
You have a Fabric workspace named Workspace1 that contains the items shown in the following table.
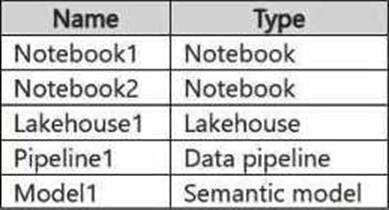
For Model1, the Keep your Direct Lake data up to date option is disabled.
You need to configure the execution of the items to meet the following requirements:
– Notebook1 must execute every weekday at 8:00 AM.
– Notebook2 must execute when a file is saved to an Azure Blob Storage container.
– Model1 must refresh when Notebook1 has executed successfully.
How should you orchestrate each item? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have a Fabric workspace named Workspace1 that contains a lakehouse named Lakehouse1.
Lakehouse1 contains the following tables:
– Orders
– Customer
– Employee
The Employee table contains Personally Identifiable Information (PII).
A data engineer is building a workflow that requires writing data to the Customer table, however, the user does NOT have the elevated permissions required to view the contents of the Employee table. You need to ensure that the data engineer can write data to the Customer table without reading data from the Employee table.
Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Share Lakehouse1 with the data engineer.
- B . Assign the data engineer the Contributor role for Workspace2.
- C . Assign the data engineer the Viewer role for Workspace2.
- D . Assign the data engineer the Contributor role for Workspace1.
- E . Migrate the Employee table from Lakehouse1 to Lakehouse2.
- F . Create a new workspace named Workspace2 that contains a new lakehouse named Lakehouse2.
- G . Assign the data engineer the Viewer role for Workspace1.
A, D, E
Explanation:
To meet the requirements of ensuring that the data engineer can write data to the Customer table
without reading data from the Employee table (which contains Personally Identifiable Information, or
PII), you can implement the following steps:
Share Lakehouse1 with the data engineer.
By sharing Lakehouse1 with the data engineer, you provide the necessary access to the data within the lakehouse. However, this access should be controlled through roles and permissions, which will allow writing to the Customer table but prevent reading from the Employee table.
Assign the data engineer the Contributor role for Workspace1.
Assigning the Contributor role for Workspace1 grants the data engineer the ability to perform actions such as writing to tables (e.g., the Customer table) within the workspace. This role typically allows users to modify and manage data without necessarily granting them access to view all data (e.g., PII data in the Employee table).
Migrate the Employee table from Lakehouse1 to Lakehouse2.
To prevent the data engineer from accessing the Employee table (which contains PII), you can migrate the Employee table to a separate lakehouse (Lakehouse2) or workspace (Workspace2). This separation of sensitive data ensures that the data engineer’s access is restricted to the Customer table in Lakehouse1, while the Employee table can be managed separately and protected under different access controls.
HOTSPOT
You have a Fabric workspace named Workspace1_DEV that contains the following items:
– 10 reports
– Four notebooks
– Three lakehouses
– Two data pipelines
– Two Dataflow Gen1 dataflows
– Three Dataflow Gen2 dataflows
– Five semantic models that each has a scheduled refresh policy
You create a deployment pipeline named Pipeline1 to move items from Workspace1_DEV to a new workspace named Workspace1_TEST.
You deploy all the items from Workspace1_DEV to Workspace1_TEST.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


You have a Fabric workspace that contains a lakehouse named Lakehouse1.
In an external data source, you have data files that are 500 GB each. A new file is added every day.
You need to ingest the data into Lakehouse1 without applying any transformations.
The solution must meet the following requirements
Trigger the process when a new file is added.
Provide the highest throughput.
Which type of item should you use to ingest the data?
- A . Event stream
- B . Dataflow Gen2
- C . Streaming dataset
- D . Data pipeline
A
Explanation:
To ingest large files (500 GB each) from an external data source into Lakehouse1 with high throughput and to trigger the process when a new file is added, an Eventstream is the best solution.
An Eventstream in Fabric is designed for handling real-time data streams and can efficiently ingest large files as soon as they are added to an external source. It is optimized for high throughput and can be configured to trigger upon detecting new files, allowing for fast and continuous ingestion of data with minimal delay.