
Practice Free DP-600 Exam Online Questions
You have a Fabric tenant that contains a takehouse named lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
DESCRIBE HISTORY customer
Does this meet the goal?
- A . Yes
- B . No
A
Explanation:
Yes, the DESCRIBE HISTORY statement does meet the goal. It provides information on the history of operations, including maintenance tasks, performed on a Delta table.
Reference = The functionality of the DESCRIBE HISTORY statement can be verified in the Delta Lake documentation.
Topic 3, Misc. Questions
You have a Fabric warehouse that contains a table named Staging.Sales.
Staging.Sales contains the following columns.

You need to write a T-SQL query that will return data for the year 2023 that displays ProductID and ProductName arxl has a summarized Amount that is higher than 10,000.
Which query should you use?
A)

B)

C)
![]()
D)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
B
Explanation:
The correct query to use in order to return data for the year 2023 that displays ProductID, ProductName, and has a summarized Amount greater than 10,000 is Option B. The reason is that it uses the GROUP BY clause to organize the data by ProductID and ProductName and then filters the result using the HAVING clause to only include groups where the sum of Amount is greater than 10,000. Additionally, the DATEPART(YEAR, SaleDate) = ‘2023’ part of the HAVING clause ensures that only records from the year 2023 are included.
Reference = For more information, please visit the official documentation on T-SQL queries and the GROUP BY clause at T-SQL GROUP BY.
DRAG DROP
You have a Fabric tenant that contains a lakehouse named Lakehouse1
Readings from 100 loT devices are appended to a Delta table in Lakehouse1. Each set of readings is approximately 25 KB. Approximately 10 GB of data is received daily.
All the table and SparkSession settings are set to the default.
You discover that queries are slow to execute. In addition, the lakehouse storage contains data and log files that are no longer used.
You need to remove the files that are no longer used and combine small files into larger files with a target size of 1 GB per file.
What should you do? To answer, drag the appropriate actions to the correct requirements. Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.

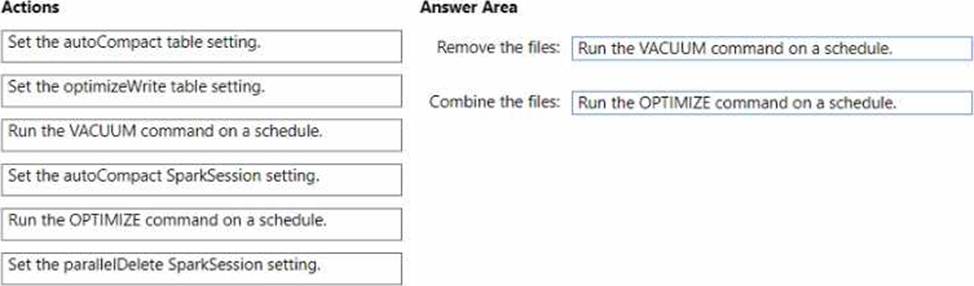
Explanation:
Remove the files: Run the VACUUM command on a schedule.
Combine the files: Set the optimizeWrite table setting. or Run the OPTIMIZE command on a schedule.
To remove files that are no longer used, the VACUUM command is used in Delta Lake to clean up invalid files from a table. To combine smaller files into larger ones, you can either set the optimizeWrite setting to combine files during write operations or use the OPTIMIZE command, which is a Delta Lake operation used to compact small files into larger ones.
What should you recommend using to ingest the customer data into the data store in the AnatyticsPOC workspace?
- A . a stored procedure
- B . a pipeline that contains a KQL activity
- C . a Spark notebook
- D . a dataflow
D
Explanation:
For ingesting customer data into the data store in the AnalyticsPOC workspace, a dataflow (D) should be recommended. Dataflows are designed within the Power BI service to ingest, cleanse, transform, and load data into the Power BI environment. They allow for the low-code ingestion and transformation of data as needed by Litware’s technical requirements.
Reference = You can learn more about dataflows and their use in Power BI environments in Microsoft’s Power BI documentation.
HOTSPOT
You have a data warehouse that contains a table named Stage. Customers. Stage-Customers contains all the customer record updates from a customer relationship management (CRM) system. There can be multiple updates per customer
You need to write a T-SQL query that will return the customer ID, name, postal code, and the last updated time of the most recent row for each customer ID.
How should you complete the code? To answer, select the appropriate options in the answer area, NOTE Each correct selection is worth one point.

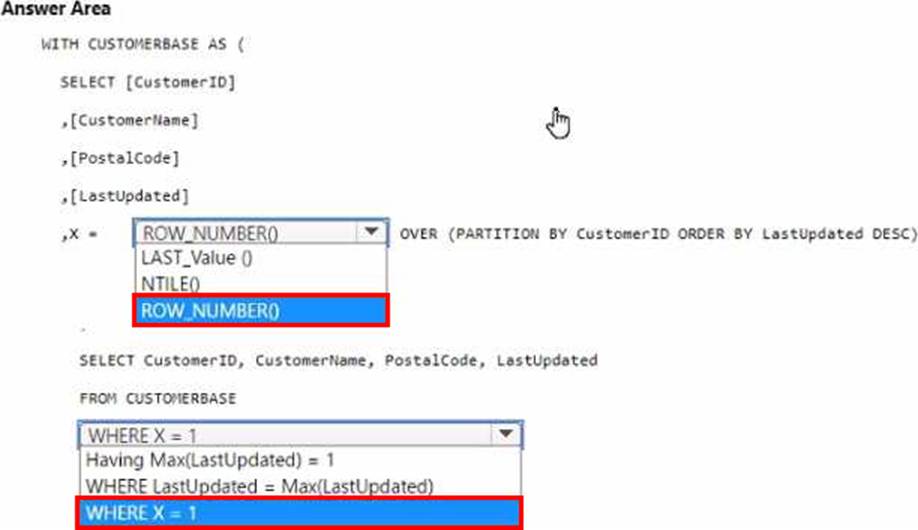
Explanation:
In the ROW_NUMBER() function, choose OVER (PARTITION BY CustomerID ORDER BY LastUpdated DESC).
In the WHERE clause, choose WHERE X = 1.
To select the most recent row for each customer ID, you use the ROW_NUMBER() window function partitioned by CustomerID and ordered by LastUpdated in descending order. This will assign a row number of 1 to the most recent update for each customer. By selecting rows where the row number
(X) is 1, you get the latest update per customer.
Reference =
Use the OVER clause to aggregate data per partition
Use window functions
HOTSPOT
You have a Fabric tenant that contains a workspace named Workspace1. Workspace1 contains a lakehouse named Lakehouse1 and a warehouse named Warehouse1.
You need to create a new table in Warehouse1 named POSCustomers by querying the customer table in Lakehouse1.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

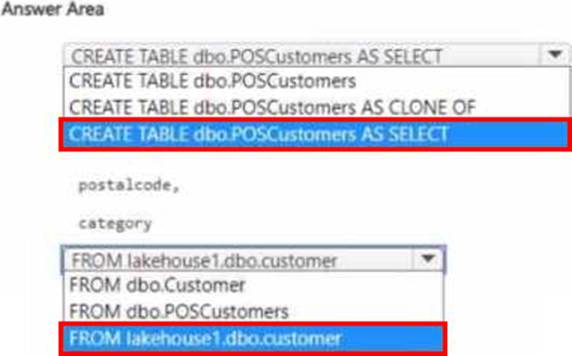
HOTSPOT
You have a Fabric tenant that contains two lakehouses.
You are building a dataflow that will combine data from the lakehouses.
The applied steps from one of the queries in the dataflow is shown in the following exhibit.

Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.

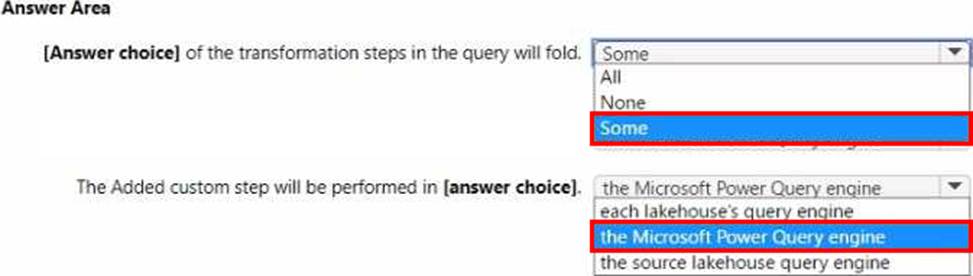
Explanation:
Folding in Power Query refers to operations that can be translated into source queries. In this case, "some" of the steps can be folded, which means that some transformations will be executed at the data source level. The steps that cannot be folded will be executed within the Power Query engine. Custom steps, especially those that are not standard query operations, are usually executed within Power Query engine rather than being pushed down to the source system.
Reference =
Query folding in Power Query
Power Query M formula language
DRAG DROP
You create a semantic model by using Microsoft Power Bl Desktop.
The model contains one security role named SalesRegionManager and the following tables:
• Sales
• SalesRegion
• Sales Ad dress
You need to modify the model to ensure that users assigned the SalesRegionManager role cannot see a column named Address in Sales Address.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

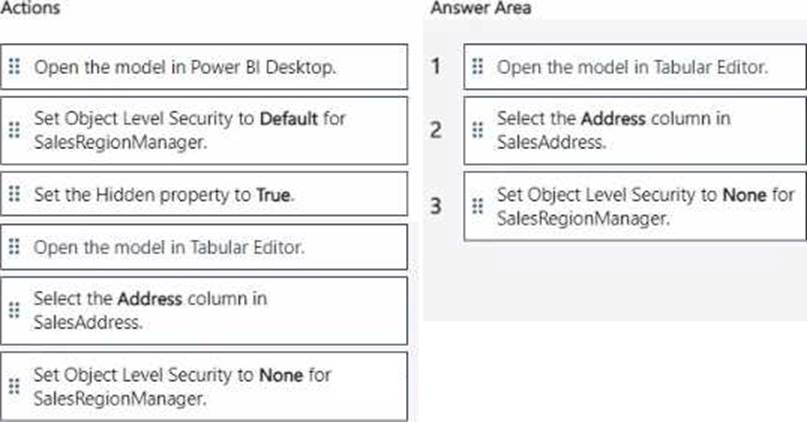
Explanation:
To ensure that users assigned the SalesRegionManager role cannot see the Address column in the SalesAddress table, follow these steps in sequence:
Open the model in Tabular Editor.
Select the Address column in SalesAddress.
Set Object Level Security to None for SalesRegionManager.
What should you use to implement calculation groups for the Research division semantic models?
- A . DAX Studio
- B . Microsoft Power Bl Desktop
- C . the Power Bl service
- D . Tabular Editor
You have a Fabric tenant that contains customer churn data stored as Parquet files in OneLake. The data contains details about customer demographics and product usage.
You create a Fabric notebook to read the data into a Spark DataFrame. You then create column charts in the notebook that show the distribution of retained customers as compared to lost customers based on geography, the number of products purchased, age. and customer tenure.
Which type of analytics are you performing?
- A . prescriptive
- B . diagnostic
- C . descriptive
- D . predictive