
Practice Free DP-600 Exam Online Questions
Which of the following is NOT a core component of Microsoft Fabric’s analytics solutions?
- A . Lakehouses
- B . Semantic models
- C . Blockchain networks
- D . Dataflows
When setting up a data integration pipeline in Microsoft Fabric, which activity should be performed to process real-time data streams? (Choose two)
- A . Use Azure Stream Analytics
- B . Configure a batch processing job
- C . Set up a real-time Power BI dashboard
- D . Utilize Azure Data Factory for orchestration
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a lakehouse named Lakehousel. Lakehousel contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
DESCRIBE DETAIL customer
Does this meet the goal?
- A . Yes
- B . No
DRAG DROP
You are implementing a medallion architecture in a single Fabric workspace.
You have a lakehouse that contains the Bronze and Silver layers and a warehouse that contains the Gold layer.
You create the items required to populate the layers as shown in the following table.

You need to ensure that the layers are populated daily in sequential order such that Silver is populated only after Bronze is complete, and Gold is populated only after Silver is complete. The solution must minimize development effort and complexity.
What should you use to execute each set of items? To answer, drag the appropriate options to the correct items. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


Explanation:
To execute each set of items in sequential order with minimized development effort and complexity, you should use the following options:
Orchestration pipeline: Use a pipeline with an Invoke pipeline activity. This allows for orchestrating and scheduling the execution of other pipelines, ensuring they run in the correct sequence.
Bronze layer: Implement a pipeline Copy activity. This aligns with the table indicating that the Bronze layer uses pipelines with Copy activities for data integration.
Silver layer: Implement a pipeline Dataflow activity. The table specifies that Dataflows are used for the Silver layer.
Gold layer: Implement a pipeline Stored procedure activity. Stored procedures are specified for the Gold layer according to the table.
You need to create a data loading pattern for a Type 1 slowly changing dimension (SCD).
Which two actions should you include in the process? Each correct answer presents part of the solution. NOTE: Each correct answer is worth one point.
- A . Update rows when the non-key attributes have changed.
- B . Insert new rows when the natural key exists in the dimension table, and the non-key attribute values have changed.
- C . Update the effective end date of rows when the non-key attribute values have changed.
- D . Insert new records when the natural key is a new value in the table.
A, D
Explanation:
For a Type 1 SCD, you should include actions that update rows when non-key attributes have changed (A), and insert new records when the natural key is a new value in the table (D). A Type 1 SCD does not track historical data, so you always overwrite the old data with the new data for a given key.
Reference = Details on Type 1 slowly changing dimension patterns can be found in data warehousing literature and Microsoft’s official documentation.
HOTSPOT
You have a Fabric warehouse that contains a table named Sales.Products. Sales.Products contains the following columns.

You need to write a T-SQL query that will return the following columns.

How should you complete the code? To answer, select the appropriate options in the answer area.


Explanation:
For the HighestSellingPrice, you should use the GREATEST function to find the highest value from the given price columns. However, T-SQL does not have a GREATEST function as found in some other SQL dialects, so you would typically use a CASE statement or an IIF statement with nested MAX functions. Since neither of those are provided in the options, you should select MAX as a placeholder to indicate the function that would be used to find the highest value if combining multiple MAX functions or a similar logic was available.
For the TradePrice, you should use the COALESCE function, which returns the first non-null value in a list. The COALESCE function is the correct choice as it will return AgentPrice if it’s not null; if AgentPrice is null, it will check WholesalePrice, and if that is also null, it will return ListPrice.
The complete code with the correct SQL functions would look like this:
SELECT ProductID,
MAX(ListPrice, WholesalePrice, AgentPrice) AS HighestSellingPrice, — MAX is used as a placeholder
COALESCE(AgentPrice, WholesalePrice, ListPrice) AS TradePrice FROM Sales.Products
Select MAX for HighestSellingPrice and COALESCE for TradePrice in the answer area.
HOTSPOT
You have source data in a CSV file that has the following fields:
• SalesTra nsactionl D
• SaleDate
• CustomerCode
• CustomerName
• CustomerAddress
• ProductCode
• ProductName
• Quantity
• UnitPrice
You plan to implement a star schema for the tables in WH1. Thedimension tables in WH1 will implement Type 2 slowly changing dimension (SCD) logic.
You need to design the tables that will be used for sales transaction analysis and load the source data.
Which type of target table should you specify for the CustomerName, CustomerCode, and SaleDate fields? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

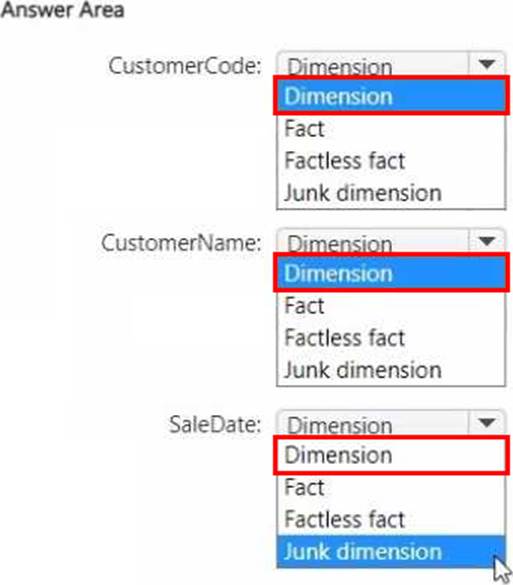
You have a Fabric tenant that contains a lakehouse. You plan to use a visual query to merge two tables.
You need to ensure that the query returns all the rows that are present in both tables.
Which type of join should you use?
- A . left outer
- B . right anti
- C . full outer
- D . left anti
- E . right outer
- F . inner
C
Explanation:
When you need to return all rows that are present in both tables, you use a full outer join. This type of join combines the results of both left and right outer joins and returns all rows from both tables, with matching rows from both sides where available. If there is no match, the result is NULL on the side of the join where there is no match.
Reference: Information about joins and their use in querying data in a lakehouse can be typically found in the SQL and data processing documentation of the Fabric tenant or lakehouse solutions.
You have a Fabric workspace named Workspace 1 that contains a dataflow named Dataflow1. Dataflow! has a query that returns 2.000 rows.
You view the query in Power Query as shown in the following exhibit.

What can you identify about the pickupLongitude column?
- A . The column has duplicate values.
- B . All the table rows are profiled.
- C . The column has missing values.
- D . There are 935 values that occur only once.
A
Explanation:
The pickup Longitude column has duplicate values. This can be inferred because the ‘Distinct count’ is 935 while the ‘Count’ is 1000, indicating that there are repeated values within the column. Reference
= Microsoft Power BI documentation on data profiling could provide further insights into understanding and interpreting column statistics like these.
You need to implement the date dimension in the data store. The solution must meet the technical requirements.
What are two ways to achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . Populate the date dimension table by using a dataflow.
- B . Populate the date dimension table by using a Stored procedure activity in a pipeline.
- C . Populate the date dimension view by using T-SQL.
- D . Populate the date dimension table by using a Copy activity in a pipeline.
A, B
Explanation:
Both a dataflow (A) and a Stored procedure activity in a pipeline (B) are capable of creating and populating a date dimension table. A dataflow can perform the transformation needed to create the date dimension, and it aligns with the preference for using low-code tools for data ingestion when possible. A Stored procedure could be written to generate the necessary date dimension data and executed within a pipeline, which also adheres to the technical requirements for the PoC.