
Practice Free DP-420 Exam Online Questions
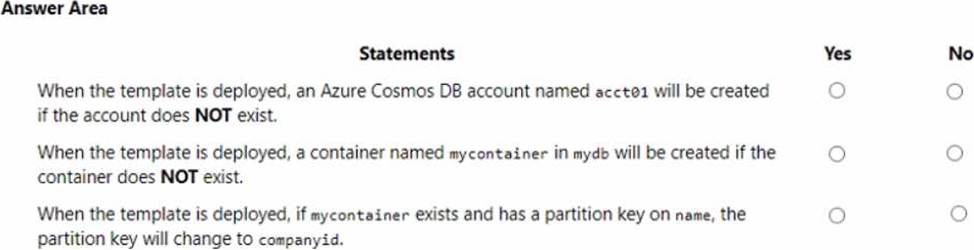
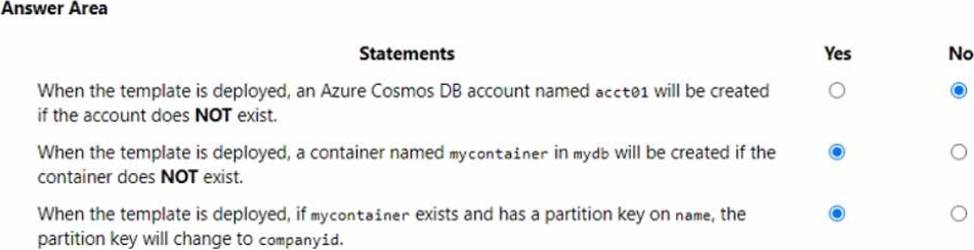
HOTSPOT
You have the following Azure Resource Manager (ARM) template.

You plan to deploy the template in incremental mode.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
You have the following query.
SELECT * FROM с
WHERE c.sensor = "TEMP1"
AND c.value < 22
AND c.timestamp >= 1619146031231
You need to recommend a composite index strategy that will minimize the request units (RUs) consumed by the query.
What should you recommend?
- A . a composite index for (sensor ASC, value ASC) and a composite index for (sensor ASC, timestamp ASC)
- B . a composite index for (sensor ASC, value ASC, timestamp ASC) and a composite index for (sensor DESC, value DESC, timestamp DESC)
- C . a composite index for (value ASC, sensor ASC) and a composite index for (timestamp ASC, sensor ASC)
- D . a composite index for (sensor ASC, value ASC, timestamp ASC)
A
Explanation:
If a query has a filter with two or more properties, adding a composite index will improve performance.
Consider the following query:
SELECT * FROM c WHERE c.name = “Tim” and c.age > 18
In the absence of a composite index on (name ASC, and age ASC), we will utilize a range index for this query. We can improve the efficiency of this query by creating a composite index for name and age. Queries with multiple equality filters and a maximum of one range filter (such as >,<, <=, >=, !=) will utilize the composite index.
Reference: https://azure.microsoft.com/en-us/blog/three-ways-to-leverage-composite-indexes-in-azure-cosmos-db/
HOTSPOT
You have an Azure Cosmos DB Core (SQL) API account named account1.
You have the Azure virtual networks and subnets shown in the following table.

The vnet1 and vnet2 networks are connected by using a virtual network peer.
The Firewall and virtual network settings for account1 are configured as shown in the exhibit.
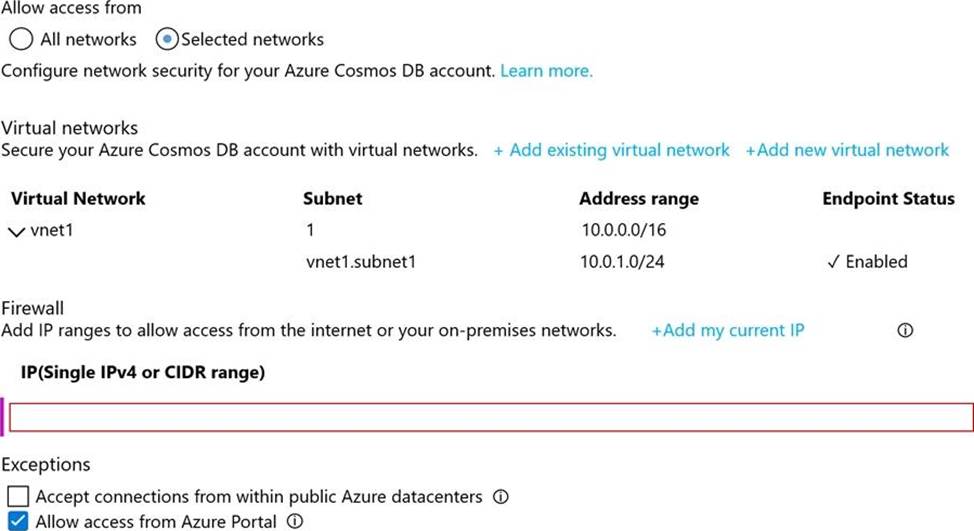
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
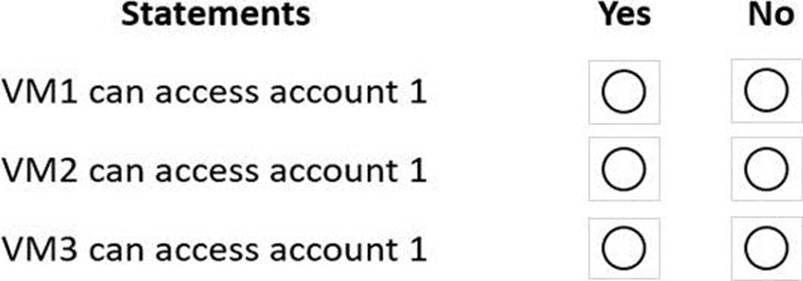
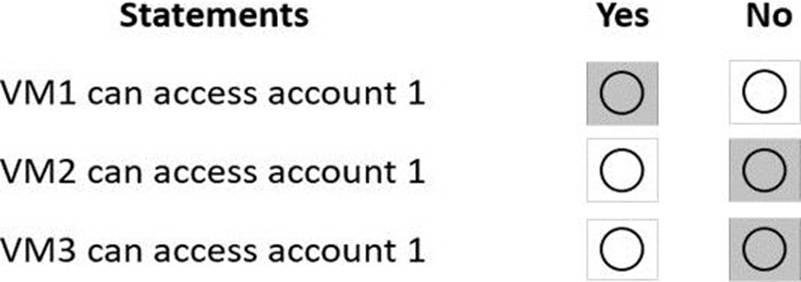
Explanation:
Box 1: Yes
VM1 is on vnet1.subnet1 which has the Endpoint Status enabled.
Box 2: No
Only virtual network and their subnets added to Azure Cosmos account have access. Their peered VNets cannot access the account until the subnets within peered virtual networks are added to the account.
Box 3: No
Only virtual network and their subnets added to Azure Cosmos account have access.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-configure-vnet-service-endpoint
HOTSPOT
You are developing an application that will connect to an Azure Cosmos DB for NoSQL account. The account has a single readme region and one agonal read region. The regions are configured for automatic failover.
The account has the following connect strings. (Line numbers are included for reference only.)
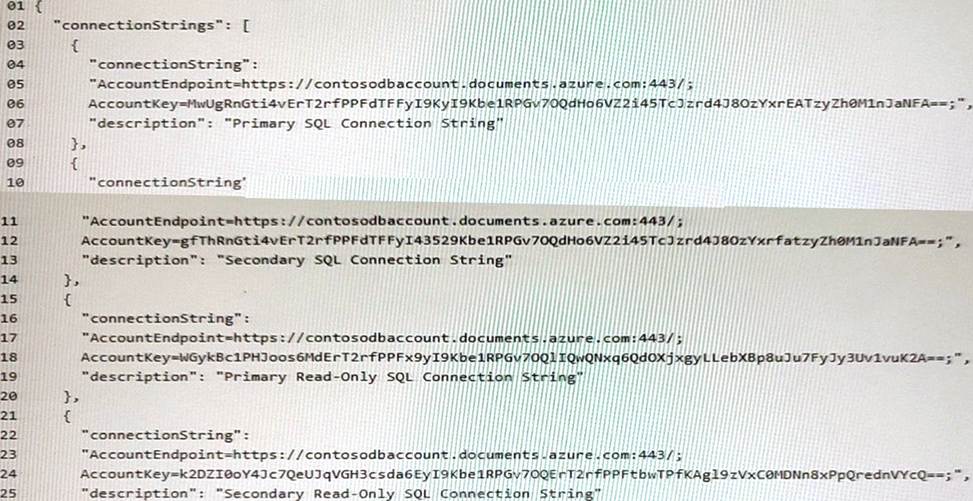
For each of the following statements, select Yes if the statement is true. otherwise, select No. NOTE: Each correct selection is worth one point.
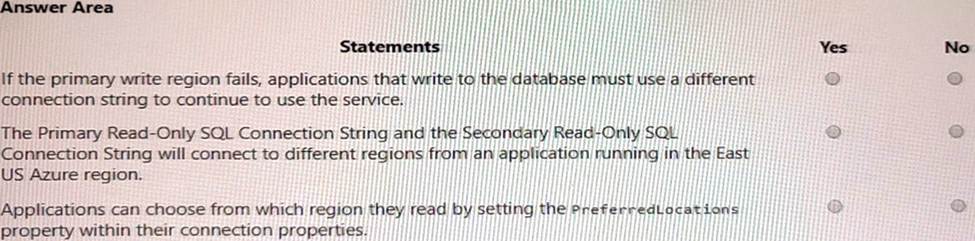
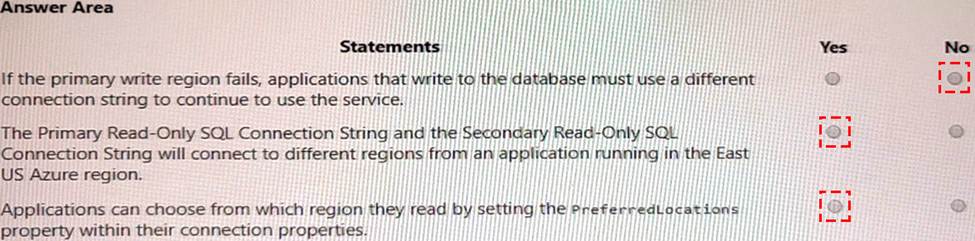
Explanation:
If the primary write region fails, applications that write to the database must use a different connection string to continue to use the service. = NO
You do not need to use a different connection string to continue to use the service if the primary write region fails. This is because Azure Cosmos DB supports automatic failover, which means that it will automatically switch the primary write region to another region in case of a regional outage2. The application does not need to change the connection string or specify the failover priority3. The connection string contains a list of all the regions associated with your account, and Azure Cosmos DB will route the requests to the appropriate region based on the availability and latency1.
The primary Read-Only SQL Connection String and the Secondary Read-Only SQL Connection String will connect to different regions from an application running in the East US Azure region = Yes
The primary read-only SQL connection string and the secondary read-only SQL connection string will connect to different regions from an application running in the East US Azure region. This is because the primary read-only SQL connection string contains the endpoint for the East US region, which is the same as the primary write region. The secondary read-only SQL connection string contains the endpoint for the West US region, which is the additional read region. Therefore, if an application running in the East US Azure region uses these connection strings, it will connect to different regions depending on which one it chooses.
Applications can choose from which region by setting the PreferredLocations property within their connection properties = Yes
Applications can choose from which region by setting the PreferredLocations property within their connection properties. This property allows you to specify a list of regions that you prefer to read from based on their proximity to your application2. Azure Cosmos DB will route the requests to the appropriate region based on the availability and latency1. You can also set the ApplicationRegion property to the region where your application is deployed, and Azure Cosmos DB will automatically populate the PreferredLocations property based on the geo-proximity from that location1.
HOTSPOT
You have an Azure Cosmos DB Core (SQL) account that has a single write region in West Europe. You run the following Azure CLI script.

For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: Yes
The Automatic failover option allows Azure Cosmos DB to failover to the region with the highest failover priority with no user action should a region become unavailable.
Box 2: No
West Europe is used for failover. Only North Europe is writable. To Configure multi-region set UseMultipleWriteLocations to true.
Box 3: Yes
Provisioned throughput with single write region costs $0.008/hour per 100 RU/s and provisioned throughput with multiple writable regions costs $0.016/per hour per 100 RU/s.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/how-to-multi-master
https://docs.microsoft.com/en-us/azure/cosmos-db/optimize-cost-regions
DRAG DROP
You have an app that stores data in an Azure Cosmos DB Core (SQL) API account The app performs queries that return large result sets.
You need to return a complete result set to the app by using pagination. Each page of results must return 80 items.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
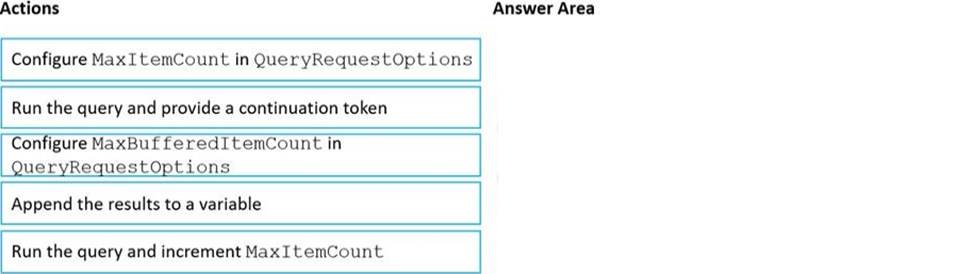

Explanation:
Step 1: Configure the MaxItemCount in QueryRequestOptions
You can specify the maximum number of items returned by a query by setting the MaxItemCount. The MaxItemCount is specified per request and tells the query engine to return that number of items or fewer.
Box 2: Run the query and provide a continuation token
In the .NET SDK and Java SDK you can optionally use continuation tokens as a bookmark for your query’s progress. Azure Cosmos DB query executions are stateless at the server side and can be resumed at any time using the continuation token.
If the query returns a continuation token, then there are additional query results.
Step 3: Append the results to a variable
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/sql/sql-query-pagination
You have a database named db1 in an Azure Cosmos DB for NoSQL
You are designing an application that will use dbl.
In db1, you are creating a new container named coll1 that will store in coll1.
The following is a sample of a document that will be stored in coll1.
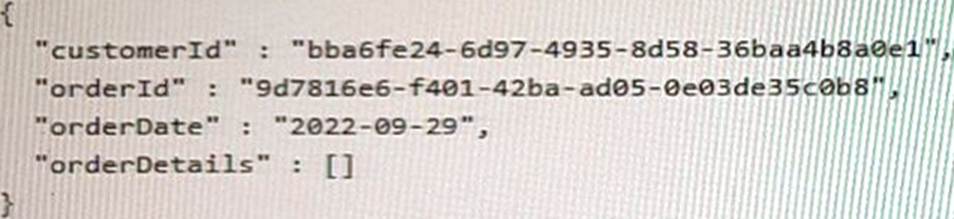
The application will have the following characteristics:
• New orders will be created frequently by different customers.
• Customers will often view their past order history.
You need to select the partition key value for coll1 to support the application.
The solution must minimize costs.
To what should you set the partition key?
- A . id
- B . customerId
- C . orderDate
- D . orderId
C
Explanation:
Based on the characteristics of the application and the provided document structure, the most suitable partition key value for coll1 in the given scenario would be the customerId,
Option B.
The application frequently creates new orders by different customers and customers often view their past order history. Using customerId as the partition key would ensure that all orders associated with a particular customer are stored in the same partition. This enables efficient querying of past order history for a specific customer and reduces cross-partition queries, resulting in lower costs and improved performance.
a partition key is a JSON property (or path) within your documents that is used by Azure Cosmos DB to distribute data among multiple partitions3. A partition key should have a high cardinality, which means it should have many distinct values, such as hundreds or thousands1. A partition key should also align with the most common query patterns of your application, so that you can efficiently retrieve data by using the partition key value1.
Based on these criteria, one possible partition key that you could use for coll1 is
B. customerId.
This partition key has the following advantages:
It has a high cardinality, as each customer will have a unique ID3.
It aligns with the query patterns of the application, as customers will often view their past order history3.
It minimizes costs, as it reduces the number of cross-partition queries and optimizes the storage and throughput utilization1.
This partition key also has some limitations, such as:
It may not be optimal for scenarios where orders need to be queried independently from customers or aggregated by date or other criteria3.
It may result in hot partitions or throttling if some customers create orders more frequently than others or have more data than others1.
It may not support transactions across multiple customers, as transactions are scoped to a single logical partition2.
Depending on your specific use case and requirements, you may need to adjust this partition key or choose a different one. For example, you could use a synthetic partition key that concatenates multiple properties of an item2, or you could use a partition key with a random or pre-calculated suffix to distribute the workload more evenly2.
HOTSPOT
You configure Azure Cognitive Search to index a container in an Azure Cosmos DB Core (SQL) API account as shown in the following exhibit.

Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: country
The country field is filterable.
Note: filterable: Indicates whether to enable the field to be referenced in $filter queries. Filterable differs from searchable in how strings are handled. Fields of type Edm.String or Collection(Edm.String) that are filterable do not undergo lexical analysis, so comparisons are for exact matches only.
Box 2: name
The name field is not Retrievable.
Retrievable: Indicates whether the field can be returned in a search result. Set this attribute to false if you want to use a field (for example, margin) as a filter, sorting, or scoring mechanism but do not want the field to be visible to the end user.
Note: searchable: Indicates whether the field is full-text searchable and can be referenced in search queries.
Reference: https://docs.microsoft.com/en-us/rest/api/searchservice/create-index
You have a database named db1 in an Azure Cosmos DB f You have a third-party application that is exposed thro You need to migrate data from the application to a
What should you use?
- A . Database Migration Assistant
- B . Azure Data Factory
- C . Azure Migrate
B
Explanation:
you can migrate data from various data sources to Azure Cosmos DB using different tools and methods. The choice of the migration tool depends on factors such as the data source, the Azure Cosmos DB API, the size of data, and the expected migration duration1. Some of the common migration tools are:
Azure Cosmos DB Data Migration tool: This is an open source tool that can import data to Azure Cosmos DB from sources such as JSON files, MongoDB, SQL Server, CSV files, and Azure Cosmos DB collections. This tool supports the SQL API and the Table API of Azure Cosmos DB2.
Azure Data Factory: This is a cloud-based data integration service that can copy data from various sources to Azure Cosmos DB using connectors. This tool supports the SQL API, MongoDB API, Cassandra API, Gremlin API, and Table API of Azure Cosmos DB3.
Azure Cosmos DB live data migrator: This is a command-line tool that can migrate data from one Azure Cosmos DB container to another container within the same or different account. This tool supports live migration with minimal downtime and works with any Azure Cosmos DB API4.
For your scenario, if you want to migrate data from a third-party application that is exposed through an OData endpoint to a container in Azure Cosmos DB for NoSQL, you should use Azure Data Factory. Azure Data Factory has an OData connector that can read data from an OData source and write it to an Azure Cosmos DB sink using the SQL API5. You can create a copy activity in Azure Data Factory that specifies the OData source and the Azure Cosmos DB sink, and run it on demand or on a schedule.
HOTSPOT
You have a database named telemetry in an Azure Cosmos DB Core (SQL) API account that stores IoT data. The database contains two containers named readings and devices.
Documents in readings have the following structure.
id
deviceid
timestamp
ownerid
measures (array)
– type
– value
– metricid
Documents in devices have the following structure.
id
deviceid
owner
– ownerid
– emailaddress
– name
brand
model
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: Yes
Need to join readings and devices.
Box 2: No
Only readings is required. All required fields are in readings.
Box 3: No
Only devices is required. All required fields are in devices.