
Practice Free DP-203 Exam Online Questions
DRAG DROP
You have an Azure subscription.
You plan to build a data warehouse in an Azure Synapse Analytics dedicated SQL pool named pool1 that will contain staging tables and a dimensional model.
Pool1 will contain the following tables.
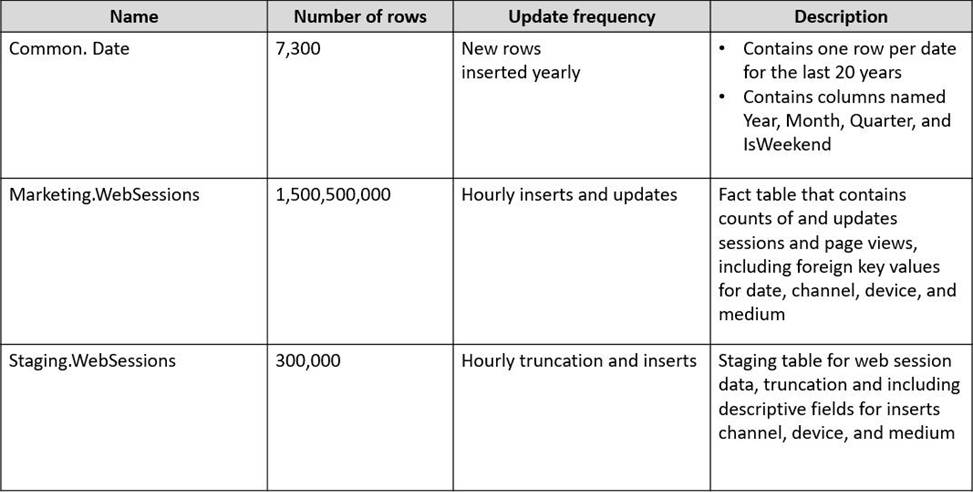
You need to design the table storage for pool1.
The solution must meet the following requirements:
✑ Maximize the performance of data loading operations to Staging.WebSessions.
✑ Minimize query times for reporting queries against the dimensional model.
Which type of table distribution should you use for each table? To answer, drag the appropriate table distribution types to the correct tables. Each table distribution type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: Replicated
The best table storage option for a small table is to replicate it across all the Compute nodes.
Box 2: Hash
Hash-distribution improves query performance on large fact tables.
Box 3: Round-robin
Round-robin distribution is useful for improving loading speed.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
- A . Azure Stream Analytics cloud job using Azure PowerShell
- B . Azure Analysis Services using Azure Portal
- C . Azure Data Factory instance using Azure Portal
- D . Azure Analysis Services using Azure PowerShell
A
Explanation:
Stream Analytics is a cost-effective event processing engine that helps uncover real-time insights from devices, sensors, infrastructure, applications and data quickly and easily.
Monitor and manage Stream Analytics resources with Azure PowerShell cmdlets and powershell scripting that execute basic Stream Analytics tasks.
Reference: https://cloudblogs.microsoft.com/sqlserver/2014/10/29/microsoft-adds-iot-streaming-analytics-
data-production-and-workflow-services-to-azure/
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1.
DB1 contains a fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
- A . Connect to the built-in pool and query sysdm_pdw_sys_info.
- B . Connect to Pool1 and run DBCC CHECKALLOC.
- C . Connect to the built-in pool and run DBCC CHECKALLOC.
- D . Connect to Pool! and query sys.dm_pdw_nodes_db_partition_stats.
D
Explanation:
Microsoft recommends use of sys.dm_pdw_nodes_db_partition_stats to analyze any skewness in the data.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/cheat-sheet
HOTSPOT
You have an Azure Synapse Analytics pipeline named Pipeline1 that contains a data flow activity named Dataflow1.
Pipeline1 retrieves files from an Azure Data Lake Storage Gen 2 account named storage1.
Dataflow1 uses the AutoResolveIntegrationRuntime integration runtime configured with a core count of 128.
You need to optimize the number of cores used by Dataflow1 to accommodate the size of the files in storage1.
What should you configure? To answer, select the appropriate options in the answer area.

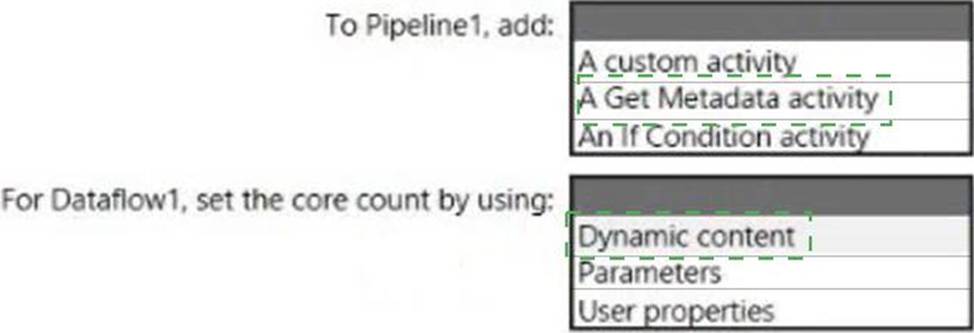
Explanation:
Box 1: A Get Metadata activity
Dynamically size data flow compute at runtime
The Core Count and Compute Type properties can be set dynamically to adjust to the size of your incoming source data at runtime. Use pipeline activities like Lookup or Get Metadata in order to find the size of the source dataset data. Then, use Add Dynamic Content in the Data Flow activity properties.
Box 2: Dynamic content
Reference: https://docs.microsoft.com/en-us/azure/data-factory/control-flow-execute-data-flow-activity
You plan to create a dimension table in Azure Synapse Analytics that will be less than 1 GB.
You need to create the table to meet the following requirements:
• Provide the fastest Query time.
• Minimize data movement during queries.
Which type of table should you use?
- A . hash distributed
- B . heap
- C . replicated
- D . round-robin
C
Explanation:
A replicated table has a full copy of the table accessible on each Compute node. Replicating a table removes the need to transfer data among Compute nodes before a join or aggregation. Since the table has multiple copies, replicated tables work best when the table size is less than 2 GB compressed. 2 GB is not a hard limit.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/design-guidance-for-replicated-tables
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1.
You need to determine the size of the transaction log file for each distribution of DW1.
What should you do?
- A . On DW1, execute a query against the sys.database_files dynamic management view.
- B . From Azure Monitor in the Azure portal, execute a query against the logs of DW1.
- C . Execute a query against the logs of DW1 by using the Get-AzOperationalInsightsSearchResult PowerShell cmdlet.
- D . On the master database, execute a query against the sys.dm_pdw_nodes_os_performance_counters dynamic management view.
A
Explanation:
For information about the current log file size, its maximum size, and the autogrow option for the file, you can also use the size, max_size, and growth columns for that log file in sys.database_files.
Reference: https://docs.microsoft.com/en-us/sql/relational-databases/logs/manage-the-size-of-the-transaction-log-file
You are performing exploratory analysis of the bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool.
You execute the Transact-SQL query shown in the following exhibit.
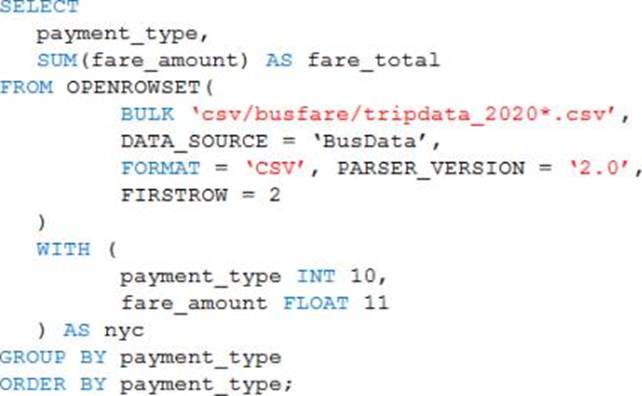
What do the query results include?
- A . Only CSV files in the tripdata_2020 subfolder.
- B . All files that have file names that beginning with "tripdata_2020".
- C . All CSV files that have file names that contain "tripdata_2020".
- D . Only CSV that have file names that beginning with "tripdata_2020".
You are creating an Apache Spark job in Azure Databricks that will ingest JSON-formatted data.
You need to convert a nested JSON string into a DataFrame that will contain multiple rows.
Which Spark SQL function should you use?
- A . explode
- B . filter
- C . coalesce
- D . extract
A
Explanation:
Convert nested JSON to a flattened DataFrame
You can to flatten nested JSON, using only $"column.*" and explode methods.
Note: Extract and flatten
Use $"column.*" and explode methods to flatten the struct and array types before displaying the flattened DataFrame.
Scala
display(DF.select($"id" as "main_id",$"name",$"batters",$"ppu",explode($"topping")) // Exploding the topping column using explode as it is an array type
.withColumn("topping_id",$"col.id") // Extracting topping_id from col using DOT form
.withColumn("topping_type",$"col.type") // Extracting topping_tytpe from col using DOT form
.drop($"col")
.select($"*",$"batters.*") // Flattened the struct type batters tto array type which is batter
.drop($"batters")
.select($"*",explode($"batter"))
.drop($"batter")
.withColumn("batter_id",$"col.id") // Extracting batter_id from col using DOT form
.withColumn("battter_type",$"col.type") // Extracting battter_type from col using DOT form
.drop($"col")
)
Reference: https://learn.microsoft.com/en-us/azure/databricks/kb/scala/flatten-nested-columns-dynamically
You have an Azure Databricks workspace named workspace! in the Standard pricing tier. Workspace1 contains an all-purpose cluster named cluster1.
You need to reduce the time it takes for cluster 1 to start and scale up. The solution must minimize costs.
What should you do first?
- A . Upgrade workspace1 to the Premium pricing tier.
- B . Create a cluster policy in workspace1.
- C . Create a pool in workspace1.
- D . Configure a global init script for workspace1.
C
Explanation:
You can use Databricks Pools to Speed up your Data Pipelines and Scale Clusters Quickly. Databricks Pools, a managed cache of virtual machine instances that enables clusters to start and scale 4 times faster.
Reference: https://databricks.com/blog/2019/11/11/databricks-pools-speed-up-data-pipelines.html
HOTSPOT
You are incrementally loading data into fact tables in an Azure Synapse Analytics dedicated SQL pool.
Each batch of incoming data is staged before being loaded into the fact tables. |
You need to ensure that the incoming data is staged as quickly as possible. |
How should you configure the staging tables? To answer, select the appropriate options in the answer area.
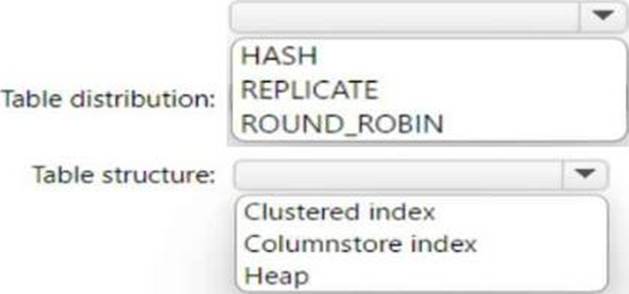
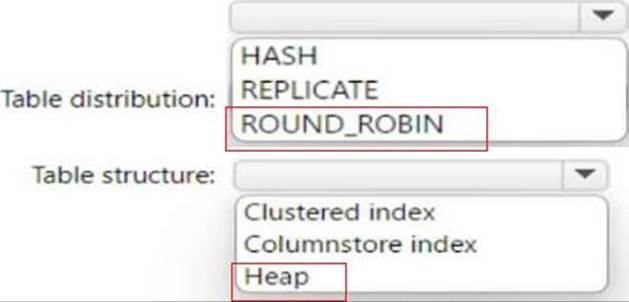
Explanation:
Round-robin distribution is recommended for staging tables because it distributes data evenly across
all the distributions without requiring a hash column. This can improve the speed of data loading and avoid data skew. Heap tables are recommended for staging tables because they do not have any indexes or partitions that can slow down the data loading process. Heap tables are also easier to truncate and reload than clustered index or columnstore index tables.