
Practice Free DP-203 Exam Online Questions
HOTSPOT
You have an Azure subscription that is linked to a hybrid Azure Active Directory (Azure AD) tenant.
The subscription contains an Azure Synapse Analytics SQL pool named Pool1.
You need to recommend an authentication solution for Pool1. The solution must support multi-factor authentication (MFA) and database-level authentication.
Which authentication solution or solutions should you include in the recommendation? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
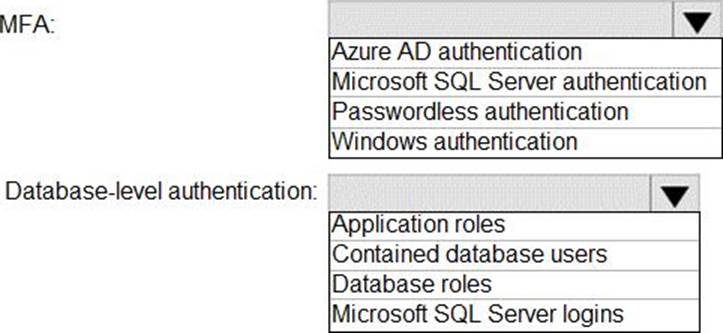
Explanation:
Box 1: Azure AD authentication
Azure Active Directory authentication supports Multi-Factor authentication through Active Directory Universal Authentication.
Box 2: Contained database users
Azure Active Directory Uses contained database users to authenticate identities at the database level.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-
authentication
You have an Azure subscription that contains an Azure Data Factory data pipeline named Pipeline1, a Log Analytics workspace named LA1, and a storage account named account1.
You need to retain pipeline-run data for 90 days.
The solution must meet the following requirements:
• The pipeline-run data must be removed automatically after 90 days.
• Ongoing costs must be minimized.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Configure Pipeline1 to send logs to LA1.
- B . From the Diagnostic settings (classic) settings of account1. set the retention period to 90 days.
- C . Configure Pipeline1 to send logs to account1.
- D . From the Data Retention settings of LA1, set the data retention period to 90 days.
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1.
Table1 contains the following:
✑ One billion rows
✑ A clustered columnstore index
✑ A hash-distributed column named Product Key
✑ A column named Sales Date that is of the date data type and cannot be null
Thirty million rows will be added to Table1 each month.
You need to partition Table1 based on the Sales Date column. The solution must optimize query performance and data loading.
How often should you create a partition?
- A . once per month
- B . once per year
- C . once per day
- D . once per week
B
Explanation:
Need a minimum 1 million rows per distribution. Each table is 60 distributions. 30 millions rows is added each month. Need 2 months to get a minimum of 1 million rows per distribution in a new partition.
Note: When creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and partition is needed. Before partitions are created, dedicated SQL pool already divides each table into 60 distributions.
Any partitioning added to a table is in addition to the distributions created behind the scenes. Using this example, if the sales fact table contained 36 monthly partitions, and given that a dedicated SQL pool has 60 distributions, then the sales fact table should contain 60 million rows per month, or 2.1 billion rows when all months are populated. If a table contains fewer than the recommended minimum number of rows per partition, consider using fewer partitions in order to increase the number of rows per partition.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-partition
HOTSPOT
You have an Azure Data Factory pipeline that has the activities shown in the following exhibit.
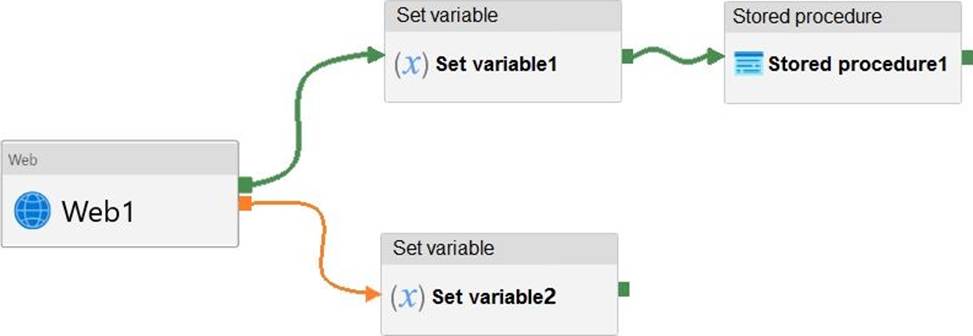
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: succeed
Box 2: failed
Example:
Now let’s say we have a pipeline with 3 activities, where Activity1 has a success path to Activity2 and a failure path to Activity3. If Activity1 fails and Activity3 succeeds, the pipeline will fail. The presence of the success path alongside the failure path changes the outcome reported by the pipeline, even though the activity executions from the pipeline are the same as the previous scenario.

Activity1 fails, Activity2 is skipped, and Activity3 succeeds. The pipeline reports failure.
Reference: https://datasavvy.me/2021/02/18/azure-data-factory-activity-failures-and-pipeline-outcomes/
You are designing an Azure Data Lake Storage solution that will transform raw JSON files for use in an analytical workload.
You need to recommend a format for the transformed files.
The solution must meet the following requirements:
✑ Contain information about the data types of each column in the files.
✑ Support querying a subset of columns in the files.
✑ Support read-heavy analytical workloads.
✑ Minimize the file size.
What should you recommend?
- A . JSON
- B . CSV
- C . Apache Avro
- D . Apache Parquet
D
Explanation:
Parquet, an open-source file format for Hadoop, stores nested data structures in a flat columnar format.
Compared to a traditional approach where data is stored in a row-oriented approach, Parquet file format is more efficient in terms of storage and performance.
It is especially good for queries that read particular columns from a “wide” (with many columns) table since only needed columns are read, and IO is minimized.
Reference: https://www.clairvoyant.ai/blog/big-data-file-formats
HOTSPOT
You have two Azure SQL databases named DB1 and DB2.
DB1 contains a table named Table 1. Table1 contains a timestamp column named LastModifiedOn.
LastModifiedOn contains the timestamp of the most recent update for each individual row.
DB2 contains a table named Watermark. Watermark contains a single timestamp column named WatermarkValue.
You plan to create an Azure Data Factory pipeline that will incrementally upload into Azure Blob Storage all the rows in Table1 for which the LastModifiedOn column contains a timestamp newer than the most recent value of the WatermarkValue column in Watermark.
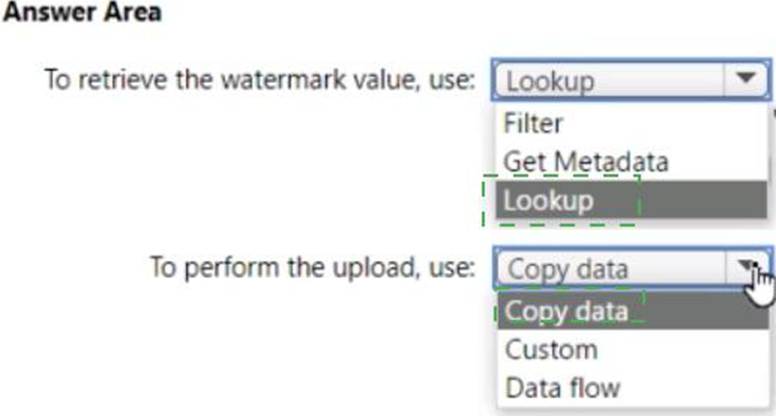
You need to identify which activities to include in the pipeline.
The solution must meet the following requirements:
• Minimize the effort to author the pipeline.
• Ensure that the number of data integration units allocated to the upload operation can be controlled.
What should you identify? To answer, select the appropriate options in the answer area.
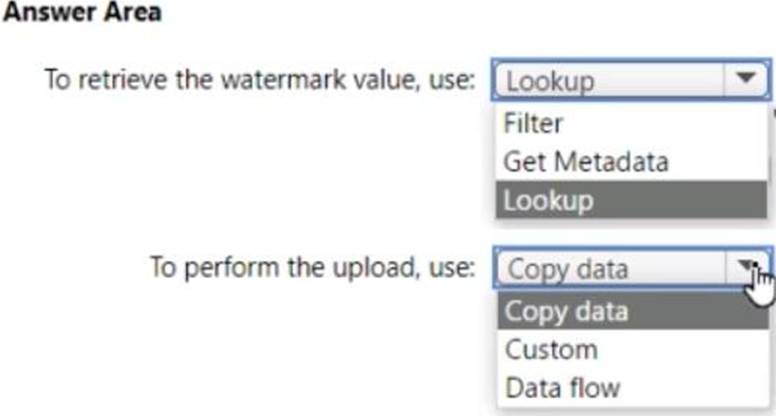
You have an Azure Synapse Analystics dedicated SQL pool that contains a table named Contacts.
Contacts contains a column named Phone.
You need to ensure that users in a specific role only see the last four digits of a phone number when querying the Phone column.
What should you include in the solution?
- A . a default value
- B . dynamic data masking
- C . row-level security (RLS)
- D . column encryption
- E . table partitions
B
Explanation:
Dynamic data masking helps prevent unauthorized access to sensitive data by enabling customers to designate how much of the sensitive data to reveal with minimal impact on the application layer. It’s a policy-based security feature that hides the sensitive data in the result set of a query over designated database fields, while the data in the database is not changed.
Reference: https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview
HOTSPOT
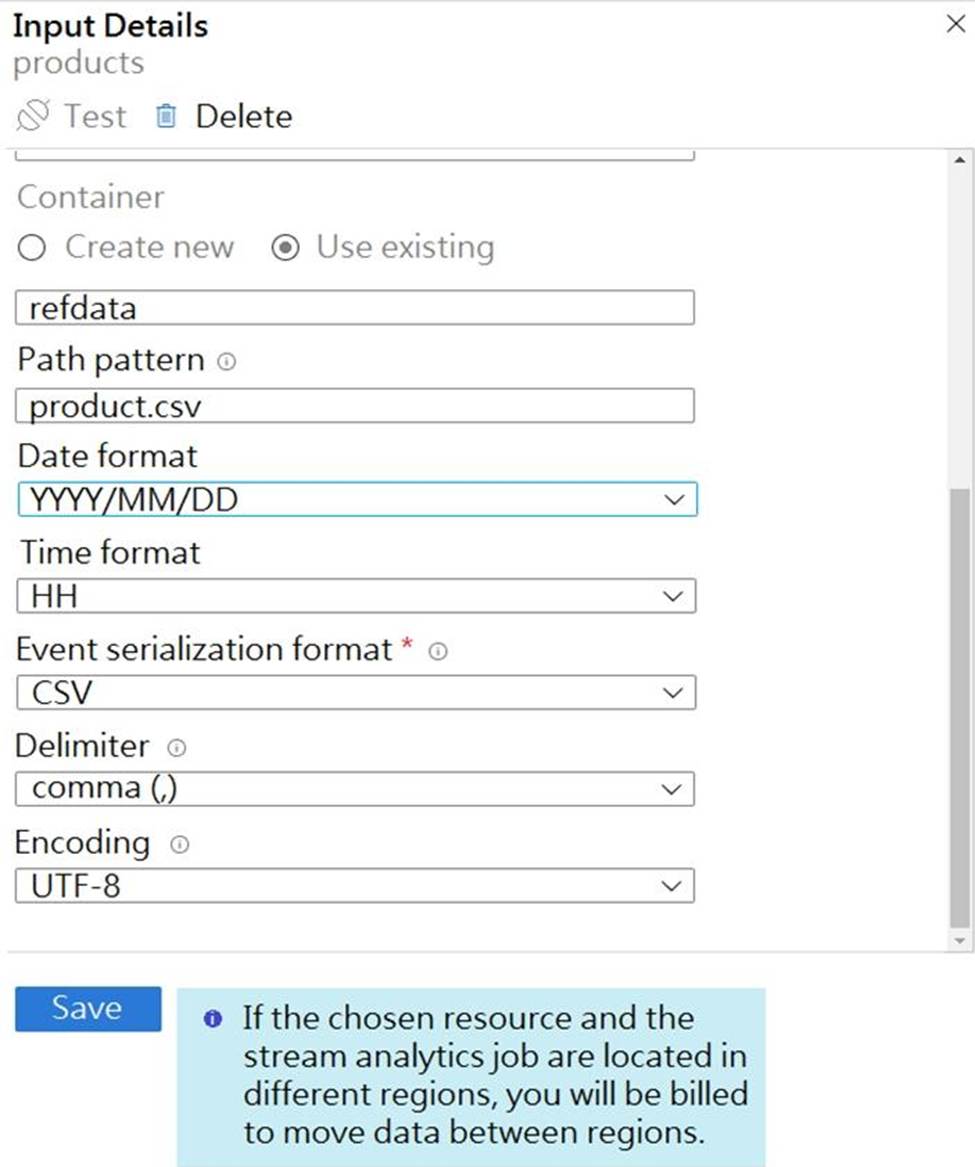
You are building an Azure Stream Analytics job that queries reference data from a product catalog file. The file is updated daily.
The reference data input details for the file are shown in the Input exhibit. (Click the Input tab.)
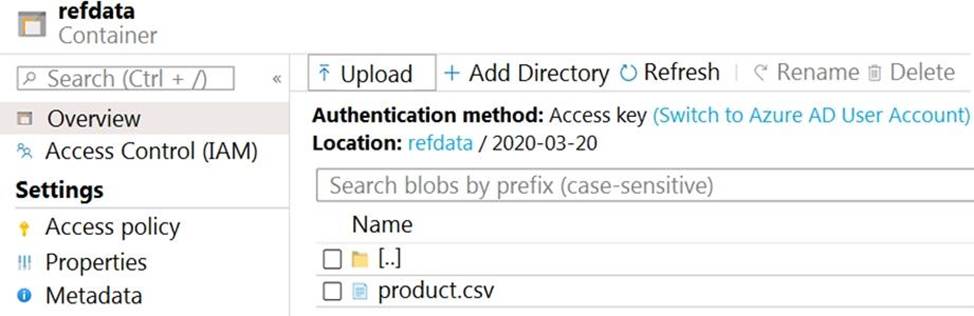
The storage account container view is shown in the Refdata exhibit. (Click the Refdata tab.)
You need to configure the Stream Analytics job to pick up the new reference data.
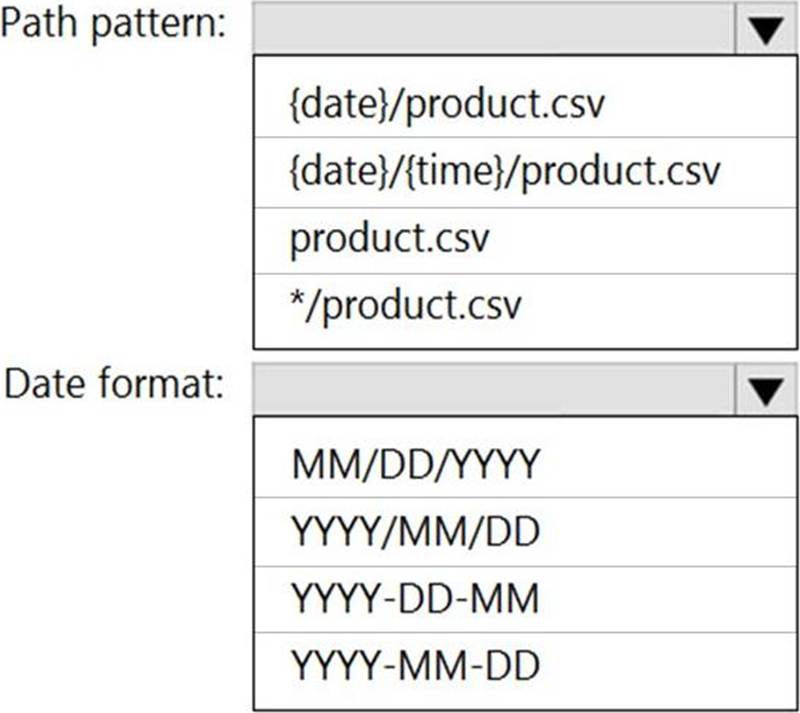
What should you configure? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
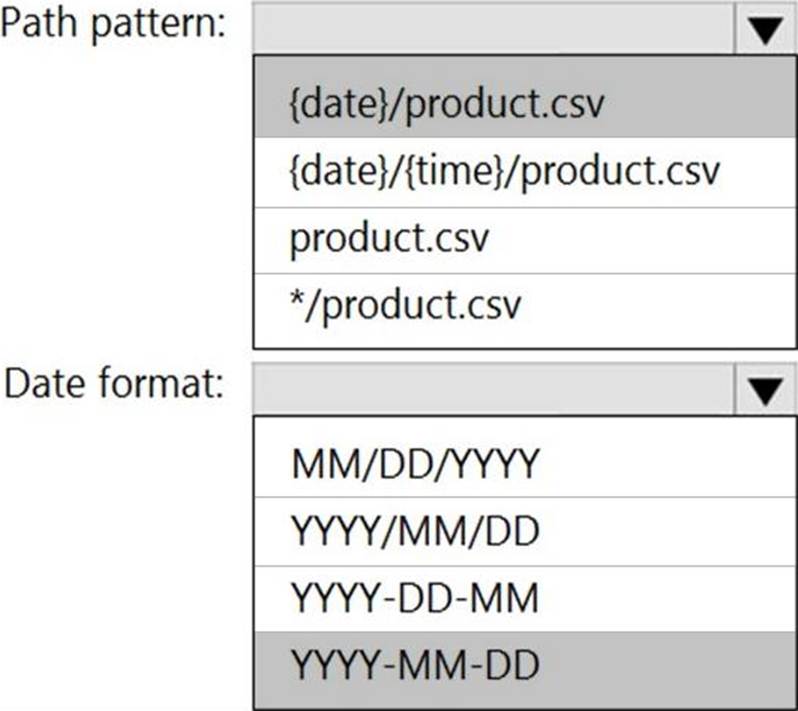
Explanation:
Box 1: {date}/product.csv
In the 2nd exhibit we see: Location: refdata / 2020-03-20
Note: Path Pattern: This is a required property that is used to locate your blobs within the specified container. Within the path, you may choose to specify one or more instances of the following 2 variables:
{date}, {time}
Example 1: products/{date}/{time}/product-list.csv
Example 2: products/{date}/product-list.csv
Example 3: product-list.csv
Box 2: YYYY-MM-DD
Note: Date Format [optional]: If you have used {date} within the Path Pattern that you specified, then you can select the date format in which your blobs are organized from the drop-down of supported formats.
Example: YYYY/MM/DD, MM/DD/YYYY, etc.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-use-reference-data
You have an Azure Data Lake Storage Gen2 account that contains two folders named Folder and Folder2.
You use Azure Data Factory to copy multiple files from Folder1 to Folder2.
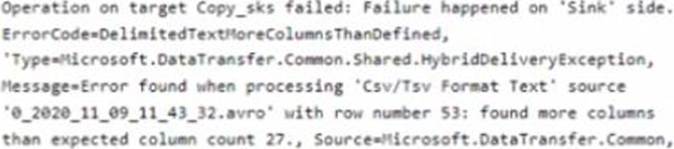
You receive the following error.
What should you do to resolve the error.
- A . Add an explicit mapping.
- B . Enable fault tolerance to skip incompatible rows.
- C . Lower the degree of copy parallelism
- D . Change the Copy activity setting to Binary Copy
A
Explanation:
Reference: https://knowledge.informatica.com/s/article/Microsoft-Azure-Data-Lake-Store-Gen2-target-file-names-not-generating-as-expected-using-create-at-runtime-option
You have an Azure subscription that contains an Azure Blob Storage account named storage1 and an Azure Synapse Analytics dedicated SQL pool named Pool1.
You need to store data in storage 1. The data will be read by Pool 1.
The solution must meet the following requirements:
✑ Enable Pool1 to skip columns and rows that are unnecessary in a query.
✑ Automatically create column statistics.
✑ Minimize the size of files.
Which type of file should you use?
- A . JSON
- B . Parquet
- C . Avro
- D . CSV
B
Explanation:
Automatic creation of statistics is turned on for Parquet files. For CSV files, you need to create statistics manually until automatic creation of CSV files statistics is supported.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-statistics