
Practice Free DP-203 Exam Online Questions
You have an enterprise-wide Azure Data Lake Storage Gen2 account. The data lake is accessible only through an Azure virtual network named VNET1.
You are building a SQL pool in Azure Synapse that will use data from the data lake.
Your company has a sales team. All the members of the sales team are in an Azure Active Directory group named Sales. POSIX controls are used to assign the Sales group access to the files in the data lake.
You plan to load data to the SQL pool every hour.
You need to ensure that the SQL pool can load the sales data from the data lake.
Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each area selection is worth one point.
- A . Add the managed identity to the Sales group.
- B . Use the managed identity as the credentials for the data load process.
- C . Create a shared access signature (SAS).
- D . Add your Azure Active Directory (Azure AD) account to the Sales group.
- E . Use the snared access signature (SAS) as the credentials for the data load process.
- F . Create a managed identity.
A, D, F
Explanation:
The managed identity grants permissions to the dedicated SQL pools in the workspace. Note: Managed identity for Azure resources is a feature of Azure Active Directory. The feature provides Azure services with an automatically managed identity in Azure AD
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/security/synapse-workspace-managed-identity
You have an Azure data factory.
You need to examine the pipeline failures from the last 60 days.
What should you use?
- A . the Activity log blade for the Data Factory resource
- B . the Monitor & Manage app in Data Factory
- C . the Resource health blade for the Data Factory resource
- D . Azure Monitor
D
Explanation:
Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to keep that data for a longer time.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
You implement an enterprise data warehouse in Azure Synapse Analytics.
You have a large fact table that is 10 terabytes (TB) in size.
Incoming queries use the primary key SaleKey column to retrieve data as displayed in the following table:
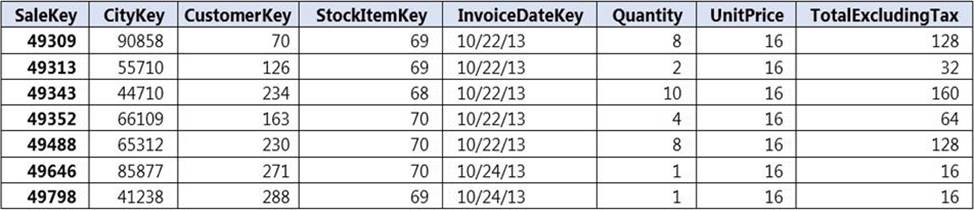
You need to distribute the large fact table across multiple nodes to optimize performance of the table.
Which technology should you use?
- A . hash distributed table with clustered index
- B . hash distributed table with clustered Columnstore index
- C . round robin distributed table with clustered index
- D . round robin distributed table with clustered Columnstore index
- E . heap table with distribution replicate
B
Explanation:
Hash-distributed tables improve query performance on large fact tables.
Columnstore indexes can achieve up to 100x better performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-query-performance
You implement an enterprise data warehouse in Azure Synapse Analytics.
You have a large fact table that is 10 terabytes (TB) in size.
Incoming queries use the primary key SaleKey column to retrieve data as displayed in the following table:
You need to distribute the large fact table across multiple nodes to optimize performance of the table.
Which technology should you use?
- A . hash distributed table with clustered index
- B . hash distributed table with clustered Columnstore index
- C . round robin distributed table with clustered index
- D . round robin distributed table with clustered Columnstore index
- E . heap table with distribution replicate
B
Explanation:
Hash-distributed tables improve query performance on large fact tables.
Columnstore indexes can achieve up to 100x better performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-query-performance
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Assign Azure AD security groups to Azure Data Lake Storage.
- B . Configure end-user authentication for the Azure Data Lake Storage account.
- C . Configure service-to-service authentication for the Azure Data Lake Storage account.
- D . Create security groups in Azure Active Directory (Azure AD) and add project members.
- E . Configure access control lists (ACL) for the Azure Data Lake Storage account.
ADE
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-secure-data
DRAG DROP
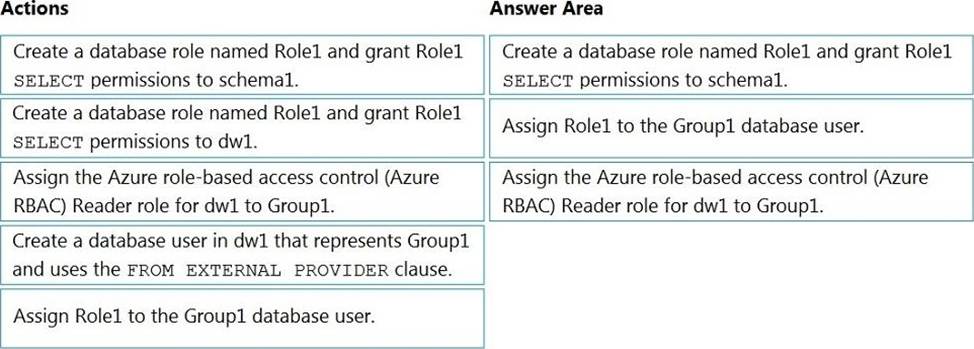
You have an Azure Active Directory (Azure AD) tenant that contains a security group named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1 that contains a schema named schema1.
You need to grant Group1 read-only permissions to all the tables and views in schema1. The solution must use the principle of least privilege.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.

Explanation:
Step 1: Create a database role named Role1 and grant Role1 SELECT permissions to schema You need to grant Group1 read-only permissions to all the tables and views in schema1.
Place one or more database users into a database role and then assign permissions to the database role.
Step 2: Assign Rol1 to the Group database user
Step 3: Assign the Azure role-based access control (Azure RBAC) Reader role for dw1 to Group1
Reference: https://docs.microsoft.com/en-us/azure/data-share/how-to-share-from-sql
You need to design a data retention solution for the Twitter teed data records. The solution must meet the customer sentiment analytics requirements.
Which Azure Storage functionality should you include in the solution?
- A . time-based retention
- B . change feed
- C . soft delete
- D . Iifecycle management
HOTSPOT
You have an Azure Data Lake Storage Gen2 container.
Data is ingested into the container, and then transformed by a data integration application. The data is NOT modified after that. Users can read files in the container but cannot modify the files.
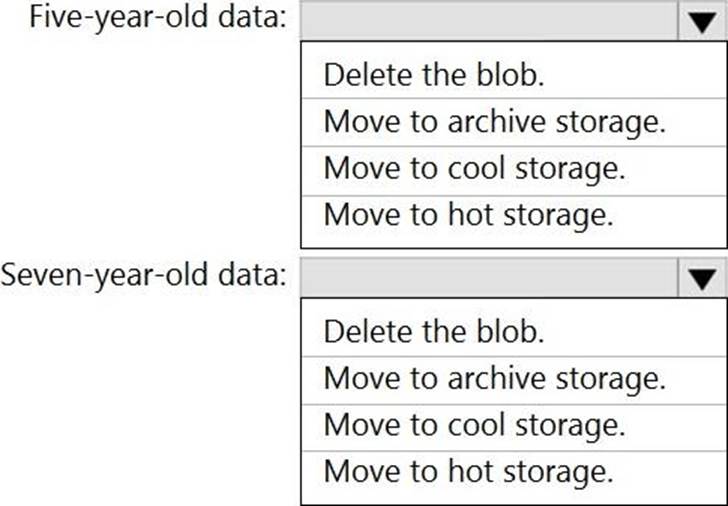
You need to design a data archiving solution that meets the following requirements:
New data is accessed frequently and must be available as quickly as possible.
Data that is older than five years is accessed infrequently but must be available within one second when requested.
Data that is older than seven years is NOT accessed. After seven years, the data must be persisted at the lowest cost possible.
Costs must be minimized while maintaining the required availability.
How should you manage the data? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point

Explanation:
Box 1: Move to cool storage
Box 2: Move to archive storage
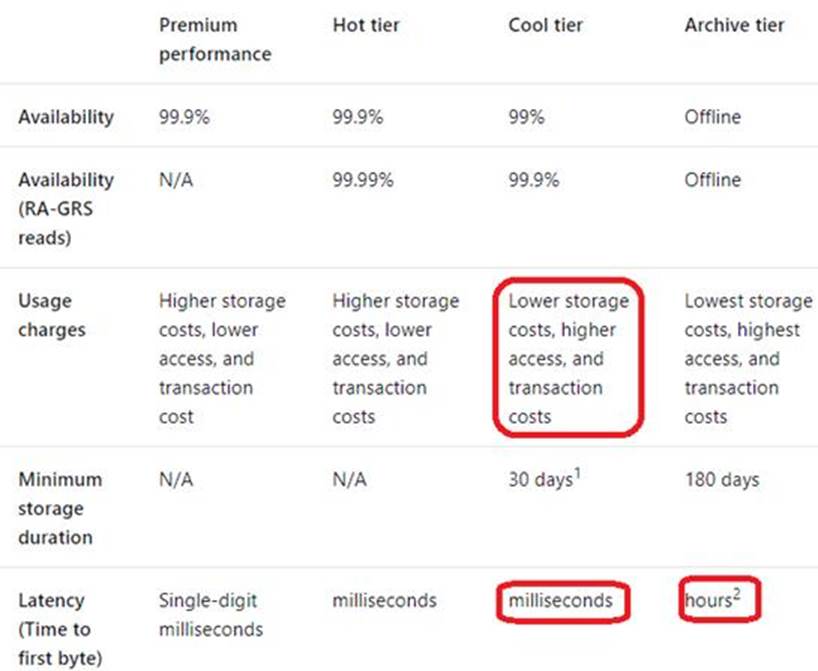
Archive – Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements, on the order of hours.
The following table shows a comparison of premium performance block blob storage, and the hot, cool, and archive access tiers.
Reference: https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers
Box 1: Replicated
Replicated tables are ideal for small star-schema dimension tables, because the fact table is often distributed on a column that is not compatible with the connected dimension tables. If this case applies to your schema, consider changing small dimension tables currently implemented as round-robin to replicated.
Box 2: Replicated
Box 3: Replicated
Box 4: Hash-distributed
For Fact tables use hash-distribution with clustered columnstore index. Performance improves when two hash tables are joined on the same distribution column.
Reference:
https://azure.microsoft.com/en-us/updates/reduce-data-movement-and-make-your-queries-more-efficient-with-the-general-availability-of-replicated-tables/
https://azure.microsoft.com/en-us/blog/replicated-tables-now-generally-available-in-azure-sql-data-warehouse/
HOTSPOT
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage account named storage1. Storage1 requires secure transfers.
You need to create an external data source in Pool1 that will be used to read .orc files in storage1.
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
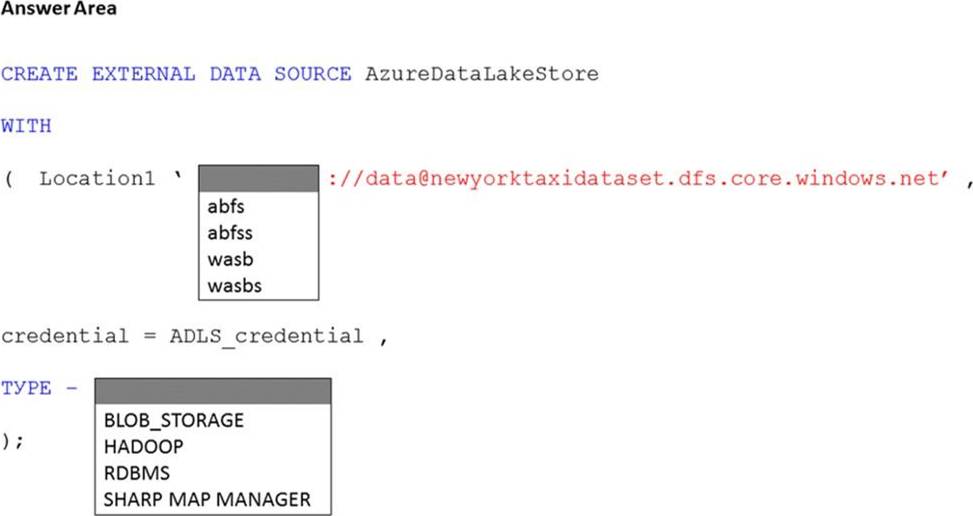
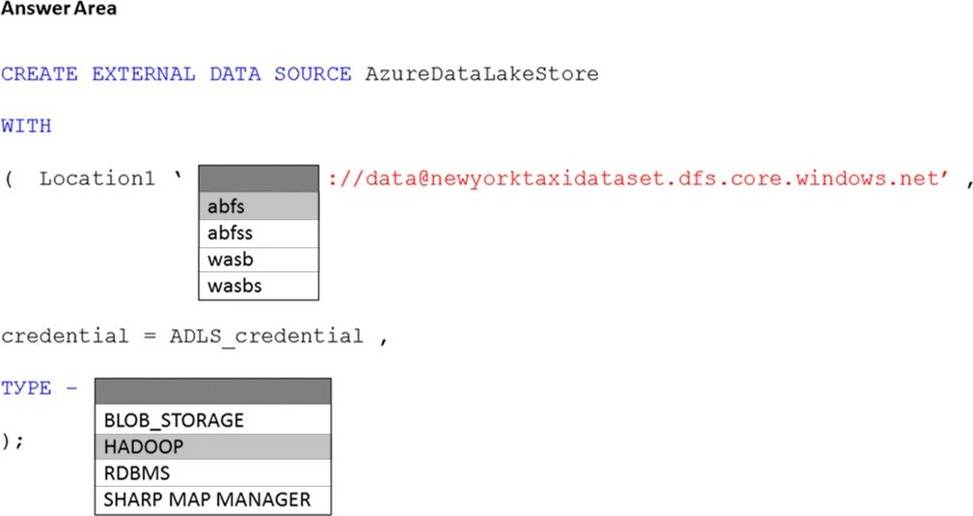
Explanation:
Reference: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-data-source-transact-sql?view=azure-sqldw-latest&preserve-view=true&tabs=dedicated
You have an Azure Synapse Analytics dedicated SQL pool named SA1 that contains a table named
Table1. You need to identify tables that have a high percentage of deleted rows.
What should you run?
A)
![]()
B)
![]()
C)
![]()
D)
![]()
- A . Option
- B . Option
- C . Option
- D . Option