
Practice Free DP-203 Exam Online Questions
You have an Azure Stream Analytics job named Job1.
The metrics of Job1 from the last hour are shown in the following table.
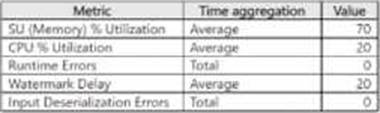
The late arrival tolerance for Job1 is set to the five seconds.
You need to optimize Job1.
Which two actions achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
- A . Resolution errors in inputs processing.
- B . Parallelize the query
- C . Resolution errors in output processing
- D . Increase the number of SUs.
DRAG DROP
You need to create an Azure Data Factory pipeline to process data for the following three departments at your company: Ecommerce, retail, and wholesale. The solution must ensure that data can also be processed for the entire company.
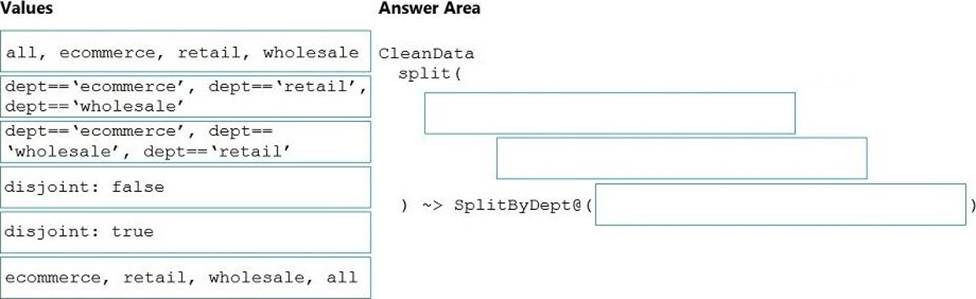
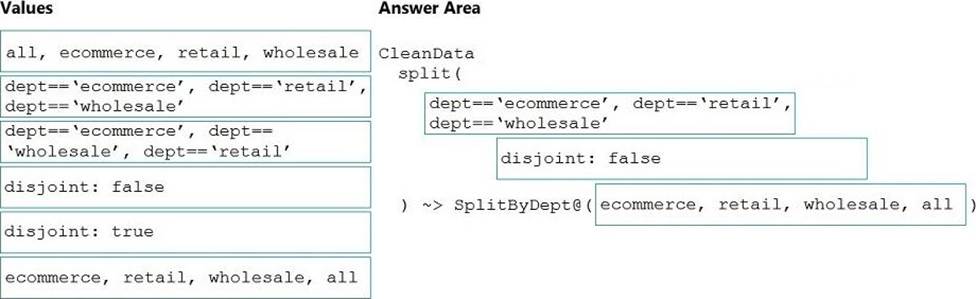
How should you complete the Data Factory data flow script? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
The conditional split transformation routes data rows to different streams based on matching conditions. The conditional split transformation is similar to a CASE decision structure in a programming language. The transformation evaluates expressions, and based on the results, directs the data row to the specified stream.
Box 1: dept==’ecommerce’, dept==’retail’, dept==’wholesale’
First we put the condition. The order must match the stream labeling we define in Box 3.
Syntax:
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
…
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, …, <defaultStream>)
Box 2: discount : false
disjoint is false because the data goes to the first matching condition. All remaining rows matching the third condition go to output stream all.
Box 3: ecommerce, retail, wholesale, all
Label the streams
Reference: https://docs.microsoft.com/en-us/azure/data-factory/data-flow-conditional-split
You have an Azure Data Factory pipeline named pipeline1 that includes a Copy activity named Copy1.
Copy1 has the following configurations:
• The source of Copy1 is a table in an on-premises Microsoft SQL Server instance that is accessed by using a linked service connected via a self-hosted integration runtime.
• The sink of Copy1 uses a table in an Azure SQL database that is accessed by using a linked service connected via an Azure integration runtime.
You need to maximize the amount of compute resources available to Copy1. The solution must minimize administrative effort.
What should you do?
- A . Scale up the data flow runtime of the Azure integration runtime.
- B . Scale up the data flow runtime of the Azure integration runtime and scale out the self-hosted integration runtime.
- C . Scale out the self-hosted integration runtime.
DRAG DROP
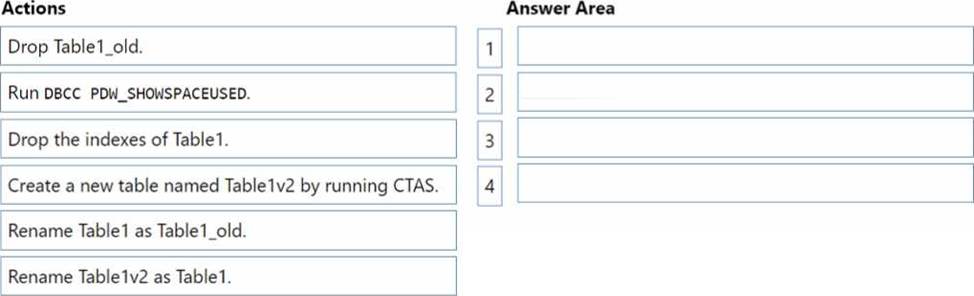
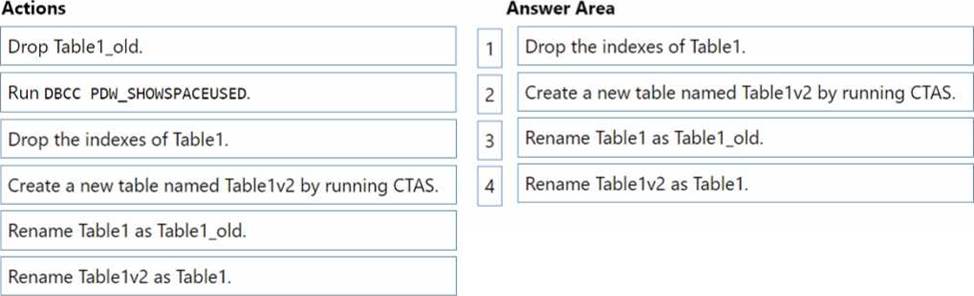
You have an Azure Synapse Analytics dedicated SQL pool named SQL1 that contains a hash-distributed fact table named Table1.
You need to recreate Table1 and add a new distribution column. The solution must maximize the availability of data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
You need to design a solution that will process streaming data from an Azure Event Hub and output
the data to Azure Data Lake Storage. The solution must ensure that analysts can interactively query
the streaming data.
What should you use?
- A . event triggers in Azure Data Factory
- B . Azure Stream Analytics and Azure Synapse notebooks
- C . Structured Streaming in Azure Databricks
- D . Azure Queue storage and read-access geo-redundant storage (RA-GRS)
C
Explanation:
Apache Spark Structured Streaming is a fast, scalable, and fault-tolerant stream processing API. You can use it to perform analytics on your streaming data in near real-time.
With Structured Streaming, you can use SQL queries to process streaming data in the same way that you would process static data.
Azure Event Hubs is a scalable real-time data ingestion service that processes millions of data in a matter of seconds. It can receive large amounts of data from multiple sources and stream the prepared data to Azure Data Lake or Azure Blob storage.
Azure Event Hubs can be integrated with Spark Structured Streaming to perform the processing of messages in near real-time. You can query and analyze the processed data as it comes by using a Structured Streaming query and Spark SQL.
Reference: https://k21academy.com/microsoft-azure/data-engineer/structured-streaming-with-azure-event-hubs/
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool. You need to identify whether a single distribution of a parallel query takes longer than other distributions.
- A . sys.dm_pdw_sql_requests
- B . sys.dm_pdw_Mec_sessions
- C . sys.dm_pdw_dns_workers
- D . sys.dm_pdw_request_steps
You have an Azure subscription that contains an Azure Synapse Analytics account. The account is integrated with an Azure Repos repository named Repo1 and contains a pipeline named Pipeline1.
Repo1 contains the branches shown in the following table.
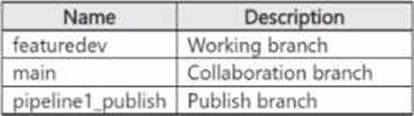
From featuredev, you develop and test changes to Pipeline1. You need to publish the changes.
What should you do first?
- A . From featuredev. create a pull request.
- B . From main, create a pull request.
- C . Add a Publish_config.json file to the root folder of the collaboration branch.
- D . Switch to live mode.
You have an Azure data factory named ADM.
You currently publish all pipeline authoring changes directly to ADF1.
You need to implement version control for the changes made to pipeline artifacts The solution must ensure that you can apply version control to the resources currently defined in the Azure Data Factory Studio for AOFl
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Create an Azure Data Factory trigger.
- B . From the Azure Data Factory Studio, select Publish.
- C . From the Azure Data Factory Studio, run Publish All
- D . Create a Git repository.
- E . Create a GitHub action.
- F . From the Azure Data Factory Studio, select up code respository
You have an Azure Stream Analytics job that read data from an Azure event hub.
You need to evaluate whether the job processes data as quickly as the data arrives or cannot keep up.
Which metric should you review?
- A . InputEventLastPunctuationTime
- B . Input Sources Receive
- C . Late input Events
- D . Backlogged input Events