
Practice Free DP-100 Exam Online Questions
you create an Azure Machine learning workspace named workspace1. The workspace contains a Python SOK v2 notebook mat uses Mallow to correct model coaxing men’s anal arracks from your local computer.
Vou must reuse the notebook to run on Azure Machine I earning compute instance m workspace.
You need to comminute to log training and artifacts from your data science code.
What should you do?
- A . Configure the tracking URL.
- B . Instantiate the MLClient class.
- C . Log in to workspace1.
- D . Instantiate the job class.
you create an Azure Machine learning workspace named workspace1. The workspace contains a Python SOK v2 notebook mat uses Mallow to correct model coaxing men’s anal arracks from your local computer.
Vou must reuse the notebook to run on Azure Machine I earning compute instance m workspace.
You need to comminute to log training and artifacts from your data science code.
What should you do?
- A . Configure the tracking URL.
- B . Instantiate the MLClient class.
- C . Log in to workspace1.
- D . Instantiate the job class.
A set of CSV files contains sales records. All the CSV files have the same data schema.
Each CSV file contains the sales record for a particular month and has the filename sales.csv. Each file in stored in a folder that indicates the month and year when the data was recorded. The folders are in an Azure blob container for which a datastore has been defined in an Azure Machine Learning workspace.
The folders are organized in a parent folder named sales to create the following hierarchical structure:

At the end of each month, a new folder with that month’s sales file is added to the sales folder.
You plan to use the sales data to train a machine learning model based on the following requirements:
✑ You must define a dataset that loads all of the sales data to date into a structure that can be easily converted to a dataframe.
✑ You must be able to create experiments that use only data that was created before a specific previous month, ignoring any data that was added after that month.
✑ You must register the minimum number of datasets possible.
You need to register the sales data as a dataset in Azure Machine Learning service workspace.
What should you do?
- A . Create a tabular dataset that references the datastore and explicitly specifies each ‘sales/mm-yyyy/ sales.csv’ file every month. Register the dataset with the name sales_dataset each month, replacing the existing dataset and specifying a tag named month indicating the month and year it was registered. Use this dataset for all experiments.
- B . Create a tabular dataset that references the datastore and specifies the path ‘sales/*/sales.csv’, register the dataset with the name sales_dataset and a tag named month indicating the month and year it was registered, and use this dataset for all experiments.
- C . Create a new tabular dataset that references the datastore and explicitly specifies each ‘sales/mm-yyyy/ sales.csv’ file every month. Register the dataset with the name sales_dataset_MM-YYYY each month with appropriate MM and YYYY values for the month and year. Use the appropriate month-specific dataset for experiments.
- D . Create a tabular dataset that references the datastore and explicitly specifies each ‘sales/mm-yyyy/
sales.csv’ file. Register the dataset with the name sales_dataset each month as a new version and with a tag named month indicating the month and year it was registered. Use this dataset for all experiments,
identifying the version to be used based on the month tag as necessary.
B
Explanation:
Specify the path.
Example:
The following code gets the workspace existing workspace and the desired datastore by name. And then passes the datastore and file locations to the path parameter to create a new TabularDataset, weather_ds.
from azureml.core import Workspace, Datastore, Dataset
datastore_name = ‘your datastore name’
# get existing workspace
workspace = Workspace.from_config()
# retrieve an existing datastore in the workspace by name
datastore = Datastore.get(workspace, datastore_name)
# create a TabularDataset from 3 file paths in datastore
datastore_paths = [(datastore, ‘weather/2018/11.csv’),
(datastore, ‘weather/2018/12.csv’),
(datastore, ‘weather/2019/*.csv’)]
weather_ds = Dataset.Tabular.from_delimited_files(path=datastore_paths)
DRAG DROP
You have an Azure Machine Learning workspace that contains a CPU-based compute cluster and an Azure Kubernetes Services (AKS) inference cluster. You create a tabular dataset containing data that you plan to use to create a classification model.
You need to use the Azure Machine Learning designer to create a web service through which client applications can consume the classification model by submitting new data and getting an immediate prediction as a response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

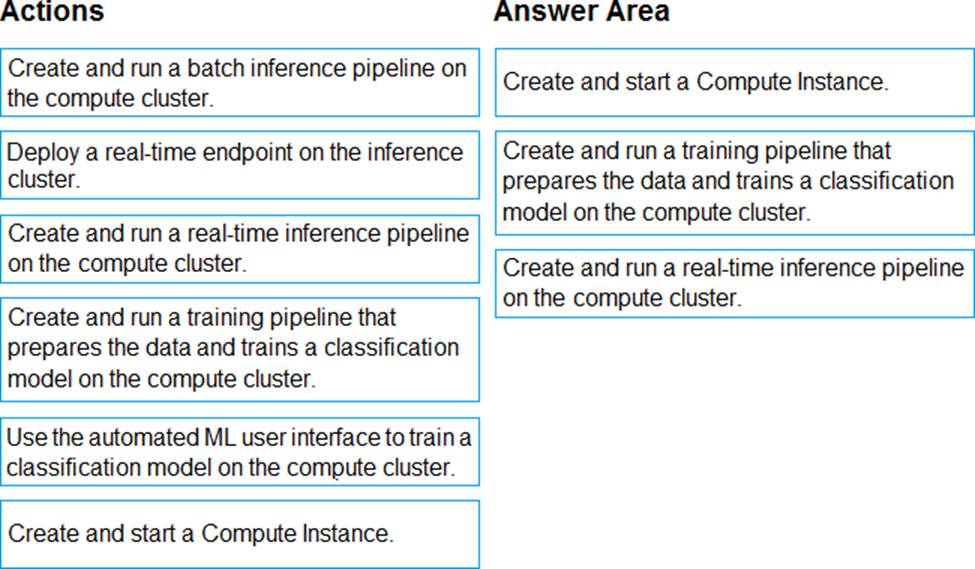
Explanation:
Step 1: Create and start a Compute Instance
To train and deploy models using Azure Machine Learning designer, you need compute on which to run the training process, test the model, and host the model in a deployed service.
There are four kinds of compute resource you can create:
Compute Instances: Development workstations that data scientists can use to work with data and models.
Compute Clusters: Scalable clusters of virtual machines for on-demand processing of experiment
code.
Inference Clusters: Deployment targets for predictive services that use your trained models.
Attached Compute: Links to existing Azure compute resources, such as Virtual Machines or Azure Databricks clusters.
Step 2: Create and run a training pipeline..
After you’ve used data transformations to prepare the data, you can use it to train a machine learning model. Create and run a training pipeline
Step 3: Create and run a real-time inference pipeline
After creating and running a pipeline to train the model, you need a second pipeline that performs the same data transformations for new data, and then uses the trained model to inference (in other words, predict) label values based on its features. This pipeline will form the basis for a predictive service that you can publish for applications to use.
Reference: https://docs.microsoft.com/en-us/learn/modules/create-classification-model-azure-machine-learning-designer/
DRAG DROP
You have an Azure Machine Learning workspace.
You plan to use the terminal to configure a compute instance to run a notebook.
You need to add a new R kernel to the compute instance.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


You have the following code. The code prepares an experiment to run a script:

The experiment must be run on local computer using the default environment.
You need to add code to start the experiment and run the script.
Which code segment should you use?
- A . run = script_experiment.start_logging()
- B . run = Run(experiment=script_experiment)
- C . ws.get_run(run_id=experiment.id)
- D . run = script_experiment.submit(config=script_config)
D
Explanation:
The experiment class submit method submits an experiment and return the active created run.
Syntax: submit(config, tags=None, **kwargs)
Reference: https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.experiment.experiment
You create an Azure Machine Learning workspace.
You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log string metrics. You need to implement the method to log the string metrics.
Which method should you use?
- A . mlflowlog_metrk()
- B . mlflow.log.dict()
- C . mlflow.log text()
- D . mlflow.log_artifact()
You create an Azure Machine Learning workspace.
You must use the Python SDK v2 to implement an experiment from a Jupyter notebook in the workspace. The experiment must log string metrics. You need to implement the method to log the string metrics.
Which method should you use?
- A . mlflowlog_metrk()
- B . mlflow.log.dict()
- C . mlflow.log text()
- D . mlflow.log_artifact()
You use the Azure Machine learning SDK v2 tor Python and notebooks to tram a model. You use Python code to create a compute target, an environment, and a taring script. You need to prepare information to submit a training job.
Which class should you use?
- A . MLClient
- B . command
- C . BuildContext
- D . EndpointConnection
HOTSPOT
You have a binary classifier that predicts positive cases of diabetes within two separate age groups.
The classifier exhibits a high degree of disparity between the age groups.
You need to modify the output of the classifier to maximize its degree of fairness across the age groups and meet the following requirements:
• Eliminate the need to retrain the model on which the classifier is based.
• Minimize the disparity between true positive rates and false positive rates across age groups.
Which algorithm and panty constraint should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

