
Practice Free DP-100 Exam Online Questions
You use Azure Machine Learning Designer to load the following datasets into an experiment:
Dataset1

Dataset2

You use Azure Machine Learning Designer to load the following datasets into an experiment:
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Join Data component.
Does the solution meet the goal?
- A . Yes
- B . No
HOTSPOT
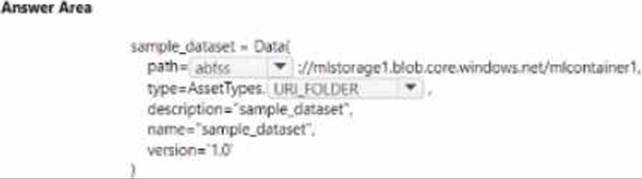
You manage an Azure Machine Learning won pace named workspace 1 by using the Python SDK v2. You create a Gene-al Purpose v2 Azure storage account named mlstorage1. The storage account includes a pulley accessible container name micOTtalnerl. The container stores 10 blobs with files in the CSV format.
You must develop Python SDK v2 code to create a data asset referencing all blobs in the container named mtcontamer1.
You need to complete the Python SDK v2 code.
How should you complete the code? To answer select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

DRAG DROP
You have several machine learning models registered in an Azure Machine Learning workspace.
You must use the Fairlearn dashboard to assess fairness in a selected model.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


Explanation:
Step 1: Select a model feature to be evaluated.
Step 2: Select a binary classification or regression model.
Register your models within Azure Machine Learning. For convenience, store the results in a dictionary, which maps the id of the registered model (a string in name:version format) to the predictor itself.
Example:
model_dict = {}
lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)
model_dict[lr_reg_id] = lr_predictor
svm_reg_id = register_model("fairness_svm", svm_predictor)
model_dict[svm_reg_id] = svm_predictor
Step 3: Select a metric to be measured
Precompute fairness metrics.
Create a dashboard dictionary using Fairlearn’s metrics package.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-machine-learning-fairness-aml
HOTSPOT
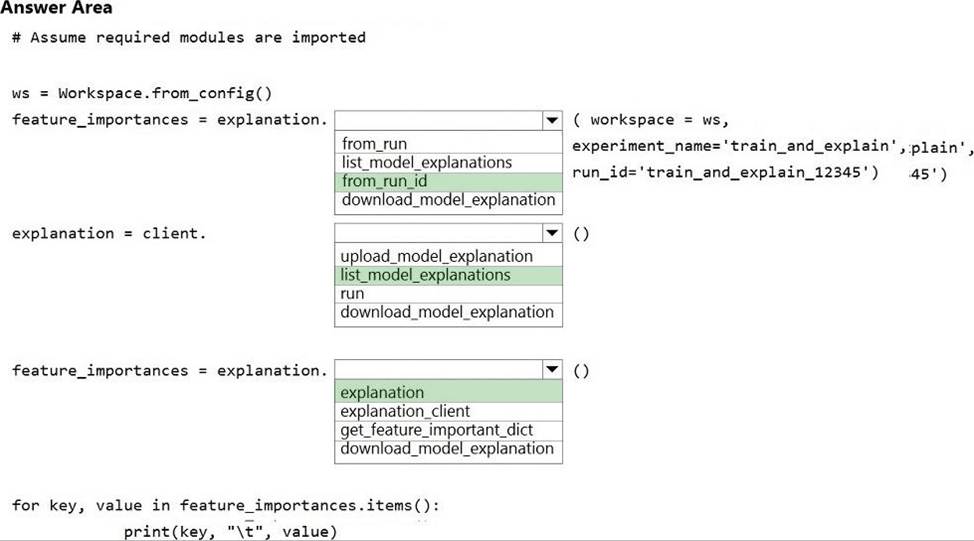
You write code to retrieve an experiment that is run from your Azure Machine Learning workspace.
The run used the model interpretation support in Azure Machine Learning to generate and upload a model explanation.
Business managers in your organization want to see the importance of the features in the model.
You need to print out the model features and their relative importance in an output that looks similar to the following.

How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

Explanation:
Box 1: from_run_id
from_run_id(workspace, experiment_name, run_id) Create the client with factory method given a run ID.
Returns an instance of the ExplanationClient.
Parameters
✑ Workspace Workspace An object that represents a workspace.
✑ experiment_name str The name of an experiment.
✑ run_id str A GUID that represents a run.
Box 2: list_model_explanations
list_model_explanations returns a dictionary of metadata for all model explanations available.
Returns
A dictionary of explanation metadata such as id, data type, explanation method, model type, and upload time, sorted by upload time
Box 3: explanation
Reference: https://docs.microsoft.com/en-us/python/api/azureml-contrib-interpret/azureml.contrib.interpret.explanation.explanation_client.explanationclient?view=azure-ml-py
DRAG DROP
You manage an Azure Machine Learning workspace That has an Azure Machine Learning datastore.
Data must be loaded from the following sources:
• a credential-less Azure Blob Storage
• an Azure Data Lake Storage (ADLS) Gen 2 which is not a credential-less datastore
You need to define the authentication mechanisms to access data in the Azure Machine Learning datastore.
Which data access mechanism should you use? To answer, move the appropriate data access mechanisms to the correct storage types. You may use each data access mechanism once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


HOTSPOT
You train a model by using Azure Machine Learning. You use Azure Blob Storage to store production data.
The model must be re-trained when new data is uploaded to Azure Blob Storage. You need to minimize development and coding.
You need to configure Azure services to develop a re-training solution.
Which Azure services should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Explanation:
To set up a solution for retraining a model when new data is uploaded to Azure Blob Storage, you can use a combination of Azure services. Here are the appropriate services to use for each requirement:
Identify when new data is uploaded:
Event Grid: Azure Event Grid can be used to monitor Azure Blob Storage for events, such as the upload of new data. It is designed to handle events in a scalable way, making it a suitable choice for identifying new data uploads.
Trigger re-training:
Logic Apps: Azure Logic Apps can be used to create workflows that automate the process of retraining your model. It allows you to create workflows with minimal code and can integrate with various Azure services, including Azure Machine Learning and Event Grid.
So, the correct selections are:
Identify when new data is uploaded: Event Grid
Trigger re-training: Logic Apps
An organization creates and deploys a multi-class image classification deep learning model that uses
a set of labeled photographs.
The software engineering team reports there is a heavy inferencing load for the prediction web services during the summer. The production web service for the model fails to meet demand despite having a fully-utilized compute cluster where the web service is deployed.
You need to improve performance of the image classification web service with minimal downtime and minimal administrative effort.
What should you advise the IT Operations team to do?
- A . Increase the minimum node count of the compute cluster where the web service is deployed.
- B . Create a new compute cluster by using larger VM sizes for the nodes, redeploy the web service to that cluster, and update the DNS registration for the service endpoint to point to the new cluster.
- C . Increase the VM size of nodes in the compute cluster where the web service is deployed.
- D . Increase the node count of the compute cluster where the web service is deployed.
D
Explanation:
The Azure Machine Learning SDK does not provide support scaling an AKS cluster. To scale the nodes in the cluster, use the UI for your AKS cluster in the Azure Machine Learning studio. You can only change the node count, not the VM size of the cluster.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-attach-kubernetes
You define a datastore named ml-data for an Azure Storage blob container. In the container, you have a folder named train that contains a file named data.csv. You plan to use the file to train a model by using the Azure Machine Learning SDK.
You plan to train the model by using the Azure Machine Learning SDK to run an experiment on local compute.
You define a DataReference object by running the following code:

You need to load the training data.
Which code segment should you use?
A)

B)

C)

D)

E)

A. Option A
B. Option B
C. Option C
D. Option D
E. Option E
Explanation:
Example:
data_folder = args.data_folder
# Load Train and Test data
train_data = pd.read_csv(os.path.join(data_folder, ‘data.csv’))
Reference: https://www.element61.be/en/resource/azure-machine-learning-services-complete-toolbox-ai
You are creating a new Azure Machine Learning pipeline using the designer.
The pipeline must train a model using data in a comma-separated values (CSV) file that is published on a website. You have not created a dataset for this file.
You need to ingest the data from the CSV file into the designer pipeline using the minimal administrative effort.
Which module should you add to the pipeline in Designer?
- A . Convert to CSV
- B . Enter Data Manually
- C . Import Data
- D . Dataset
D
Explanation:
The preferred way to provide data to a pipeline is a Dataset object. The Dataset object points to data that lives in or is accessible from a datastore or at a Web URL. The Dataset class is abstract, so you will create an instance of either a FileDataset (referring to one or more files) or a TabularDataset that’s created by from one or more files with delimited columns of data.
Example:
from azureml.core import Dataset
iris_tabular_dataset = Dataset.Tabular.from_delimited_files([(def_blob_store, ‘train-dataset/iris.csv’)])
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-your-first-pipeline
You are building a machine learning model for translating English language textual content into French language textual content.
You need to build and train the machine learning model to learn the sequence of the textual content.
Which type of neural network should you use?
- A . Multilayer Perceptions (MLPs)
- B . Convolutional Neural Networks (CNNs)
- C . Recurrent Neural Networks (RNNs)
- D . Generative Adversarial Networks (GANs)
C
Explanation:
To translate a corpus of English text to French, we need to build a recurrent neural network (RNN).
Note: RNNs are designed to take sequences of text as inputs or return sequences of text as outputs, or both.
They’re called recurrent because the network’s hidden layers have a loop in which the output and cell state from each time step become inputs at the next time step. This recurrence serves as a form of memory. It allows contextual information to flow through the network so that relevant outputs from previous time steps can be applied to network operations at the current time step.
Reference: https://towardsdatascience.com/language-translation-with-rnns-d84d43b40571