
Practice Free DP-100 Exam Online Questions
DRAG DROP
You are using a Git repository to track work in an Azure Machine Learning workspace.
You need to authenticate a Git account by using SSH.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

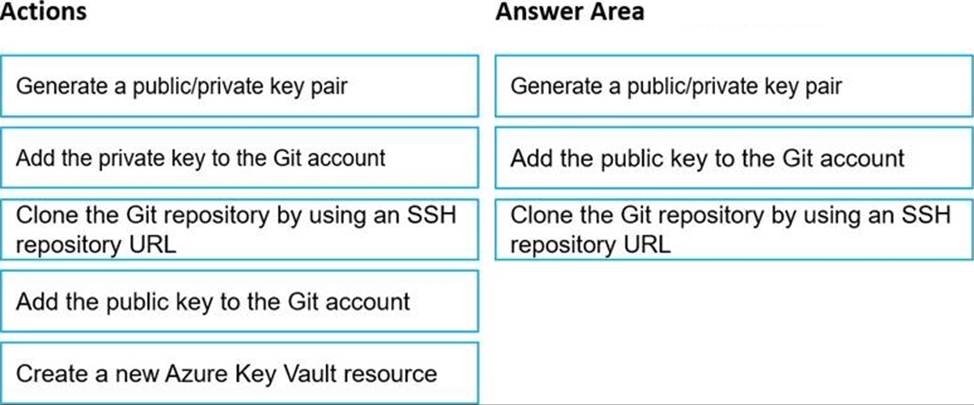
Explanation:
Authenticate your Git Account with SSH:
Step 1: Generating a public/private key pair
Generate a new SSH key
You manage an Azure Machine Learning workspace.
You need to define an environment from a Docker image by using the Azure Machine Learning Python SDK v2.
Which parameter should you use?
- A . conda_file
- B . image
- C . build
- D . properties
You have an Azure Machine Learning workspace. You are connecting an Azure Data Lake Storage Gen2 account to the workspace as a data store. You need to authorize access from the workspace to the Azure Data Lake Storage Gen2 account.
What should you use?
- A . Managed identity
- B . SAS token
- C . Service principal
- D . Account key
You manage an Azure Machine Learning workspace named workspaces
You K v2 code to attach an Azure Synapse Spark pool as a compute target in workspaces. The code must invoke the constructor of the SynapseSparkCompute class.
You need to invoke the constructor.
What should you use?
- A . Synapse workspace web URL and Spark pool name
- B . resource ID of the Synapse Spark pool and a user-defined name
- C . pool URL of the Synapse Spark pool and a system-assigned name
- D . Synapse workspace name and workspace web URL
HOTSPOT
You load data from a notebook in an Azure Machine Learning workspace into a panda’s cat frame.
The data contains 10.000 records. Each record consists of 10 columns.
You must identify the number of missing values in each of the columns.
You need to complete the Python code that will return the number of missing values in each of the columns.
Which code segments should you use? To answer, select the appropriate options in the answer area. NOTE; Each correct selection it worth one point.

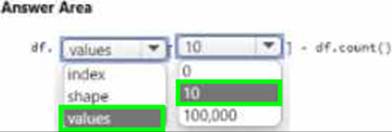
HOTSPOT
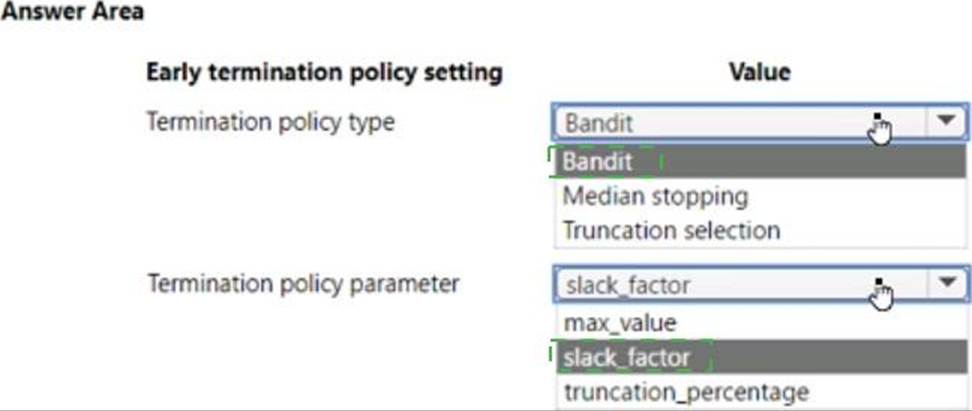
You use Azure Machine Learning to implement hyperparameter tuning for an Azure ML Python SDK v2-based model training.
Training runs must terminate when the primary metric is lowered by 25 percent or more compared to the best performing run.
You need to configure an early termination policy to terminate training jobs.
Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

You use the designer to create a training pipeline for a classification model. The pipeline uses a dataset that includes the features and labels required for model training.
You create a real-time inference pipeline from the training pipeline. You observe that the schema for the generated web service input is based on the dataset and includes the label column that the model predicts. Client applications that use the service must not be required to submit this value.
You need to modify the inference pipeline to meet the requirement.
What should you do?
- A . Add a Select Columns in Dataset module to the inference pipeline after the dataset and use it to select all columns other than the label.
- B . Delete the dataset from the training pipeline and recreate the real-time inference pipeline.
- C . Delete the Web Service Input module from the inference pipeline.
- D . Replace the dataset in the inference pipeline with an Enter Data Manually module that includes data for the feature columns but not the label column.
A
Explanation:
By default, the Web Service Input will expect the same data schema as the module output data which connects to the same downstream port as it. You can remove the target variable column in the inference pipeline using Select Columns in Dataset module. Make sure that the output of Select Columns in Dataset removing target variable column is connected to the same port as the output of the Web Service Intput module.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/tutorial-designer-automobile-price-deploy
You have a dataset that contains records of patients tested for diabetes. The dataset includes the patient s age.
You plan to create an analysis that will report the mean age value from the differentially private data derived from the dataset.
You need to identify the epsilon value to use in the analysis that minimizes the risk of exposing the actual data.
Which epsilon value should you use?
- A . -1.5
- B . -0.5
- C . 0.5
- D . 1.5
You are creating a classification model for a banking company to identify possible instances of credit card fraud. You plan to create the model in Azure Machine Learning by using automated machine learning.
The training dataset that you are using is highly unbalanced.
You need to evaluate the classification model.
Which primary metric should you use?
- A . normalized_mean_absolute_error
- B . [spearman_correlation
- C . AUC.weighted
- D . accuracy
- E . normalized_root_mean_squared_error
C
Explanation:
AUC_weighted is a Classification metric.
Note: AUC is the Area under the Receiver Operating Characteristic Curve. Weighted is the arithmetic mean of the score for each class, weighted by the number of true instances in each class.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-understand-automated-ml
You are building a regression model tot estimating the number of calls during an event.
You need to determine whether the feature values achieve the conditions to build a Poisson regression model.
Which two conditions must the feature set contain? I ach correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . The label data must be a negative value.
- B . The label data can be positive or negative,
- C . The label data must be a positive value
- D . The label data must be non discrete.
- E . The data must be whole numbers.
CE
Explanation:
Poisson regression is intended for use in regression models that are used to predict numeric values, typically counts. Therefore, you should use this module to create your regression model only if the values you are trying to predict fit the following conditions:
The response variable has a Poisson distribution.
Counts cannot be negative. The method will fail outright if you attempt to use it with negative labels.
A Poisson distribution is a discrete distribution; therefore, it is not meaningful to use this method with non-whole numbers.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/poisson-regression