
Practice Free DP-100 Exam Online Questions
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder.
You must run the script as an Azure ML experiment on a compute cluster named aml-compute.
You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml-compute that references the target compute cluster.
Solution: Run the following code:

Does the solution meet the goal?
- A . Yes
- B . No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:
from azureml.core import Run
import pandas as pd
run = Run.get_context()
data = pd.read_csv(‘data.csv’)
label_vals = data[‘label’].unique()
# Add code to record metrics here run.complete()
The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.log_table(‘Label Values’, label_vals)
Does the solution meet the goal?
- A . Yes
- B . No
You use the Azure Machine Learning designer to create and run a training pipeline.
The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset.
You need to publish the pipeline as a REST service that can be used for the nightly inferencing run.
What should you do?
- A . Create a batch inference pipeline
- B . Set the compute target for the pipeline to an inference cluster
- C . Create a real-time inference pipeline
- D . Clone the pipeline
You use the Azure Machine Learning designer to create and run a training pipeline.
The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset.
You need to publish the pipeline as a REST service that can be used for the nightly inferencing run.
What should you do?
- A . Create a batch inference pipeline
- B . Set the compute target for the pipeline to an inference cluster
- C . Create a real-time inference pipeline
- D . Clone the pipeline
HOTSPOT
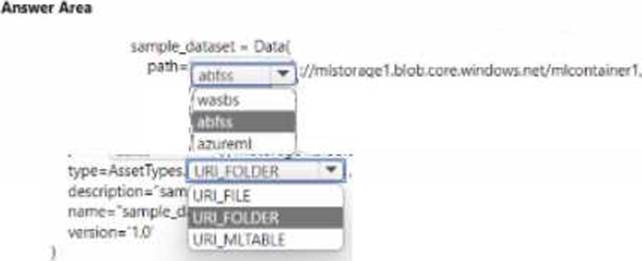
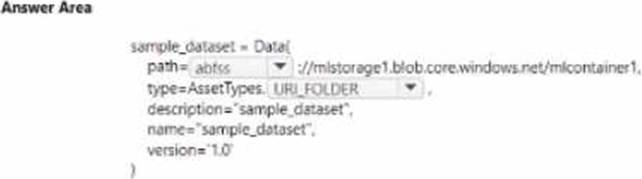
You manage an Azure Machine Learning won pace named workspace 1 by using the Python SDK v2. You create a Gene-al Purpose v2 Azure storage account named mlstorage1. The storage account includes a pulley accessible container name micOTtalnerl. The container stores 10 blobs with files in the CSV format.
You must develop Python SDK v2 code to create a data asset referencing all blobs in the container named mtcontamer1.
You need to complete the Python SDK v2 code.
How should you complete the code? To answer select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
HOTSPOT
You manage an Azure Machine Learning workspace. You create an experiment named experiment1 by using the Azure Machine Learning Python SDK v2 and MLflow.
You are reviewing the results of experiment1 by using the following code segment:
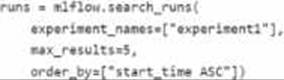
For each of the following statements, Select Yes if the statement is true Otherwise, select No.


You create a binary classification model by using Azure Machine Learning Studio.
You must tune hyperparameters by performing a parameter sweep of the model.
The parameter sweep must meet the following requirements:
iterate all possible combinations of hyperparameters minimize computing resources required to perform the sweep You need to perform a parameter sweep of the model.
Which parameter sweep mode should you use?
- A . Random sweep
- B . Sweep clustering
- C . Entire grid
- D . Random grid
- E . Random seed
You are creating a new Azure Machine Learning pipeline using the designer.
The pipeline must train a model using data in a comma-separated values (CSV) file that is published on a
website. You have not created a dataset for this file.
You need to ingest the data from the CSV file into the designer pipeline using the minimal administrative effort.
Which module should you add to the pipeline in Designer?
- A . Convert to CSV
- B . Enter Data Manually
- C . Import Data
- D . Dataset
DRAG DROP
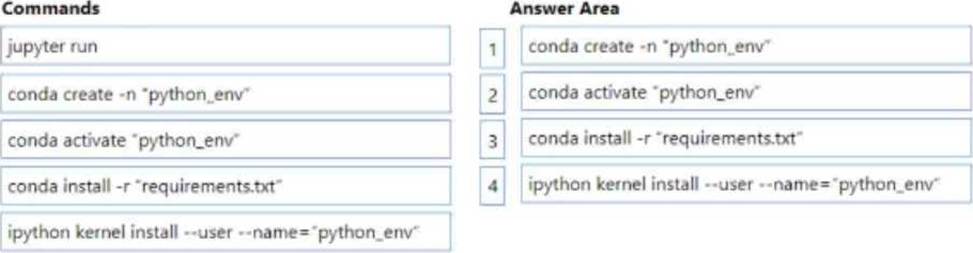
You manage an Azure Machine Learning workspace named workspace1 with a compute instance named compute1. You connect to compute! by using a terminal window from wofkspace1. You create a file named "requirements.txt" containing Python dependencies to include Jupyler.
You need to add a new Jupyter kernel to compute1.
Which four commands should you use? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

DRAG DROP
You manage an Azure Machine Learning workspace named workspace1 with a compute instance named compute1. You connect to compute! by using a terminal window from wofkspace1. You create a file named "requirements.txt" containing Python dependencies to include Jupyler.
You need to add a new Jupyter kernel to compute1.
Which four commands should you use? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.