Practice Free DP-100 Exam Online Questions
HOTSPOT
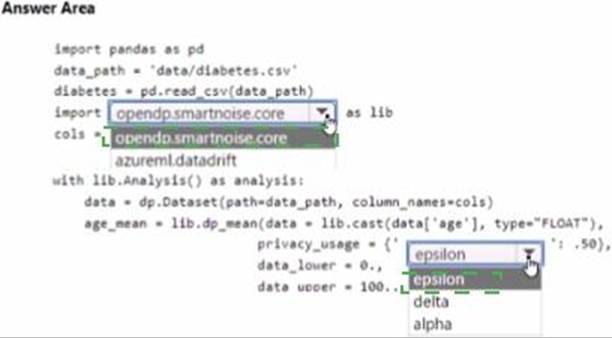
You are developing code to analyse a dataset that includes age information for a large group of diabetes patients. You create an Azure Machine Learning workspace and install all required libraries. You set the privacy budget to 1.0).
You must analyze the dataset and preserve data privacy. The code must run twice before the privacy budget is depleted.
You need to complete the code.
Which values should you use? To answer, select the appropriate options m the answer area. NOTE: Each correct selection is worth one point.

You are building a binary classification model by using a supplied training set.
The training set is imbalanced between two classes.
You need to resolve the data imbalance.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution NOTE: Each correct selection is worth one point.
- A . Penalize the classification
- B . Resample the data set using under sampling or oversampling
- C . Generate synthetic samples in the minority class.
- D . Use accuracy as the evaluation metric of the model.
- E . Normalize the training feature set.
ABD
Explanation:
Reference: https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
You are building a binary classification model by using a supplied training set.
The training set is imbalanced between two classes.
You need to resolve the data imbalance.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution NOTE: Each correct selection is worth one point.
- A . Penalize the classification
- B . Resample the data set using under sampling or oversampling
- C . Generate synthetic samples in the minority class.
- D . Use accuracy as the evaluation metric of the model.
- E . Normalize the training feature set.
ABD
Explanation:
Reference: https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
You are building a binary classification model by using a supplied training set.
The training set is imbalanced between two classes.
You need to resolve the data imbalance.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution NOTE: Each correct selection is worth one point.
- A . Penalize the classification
- B . Resample the data set using under sampling or oversampling
- C . Generate synthetic samples in the minority class.
- D . Use accuracy as the evaluation metric of the model.
- E . Normalize the training feature set.
ABD
Explanation:
Reference: https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
You create a workspace by using Azure Machine Learning Studio.
You must run a Python SDK v2 notebook in the workspace by using Azure Machine Learning Studio.
You need to reset the state of the notebook.
Which three actions should you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . Reset the compute.
- B . Change the current kernel.
- C . Stop the current kernel.
- D . Change the compute.
- E . Navigate to another section of the workspace.
You plan to run a Python script as an Azure Machine Learning experiment.
The script contains the following code:
import os, argparse, glob
from azureml.core import Run
parser = argparse.ArgumentParser()
parser.add_argument(‘–input-data’,
type=str, dest=’data_folder’)
args = parser.parse_args()
data_path = args.data_folder
file_paths = glob.glob(data_path + "/*.jpg")
You must specify a file dataset as an input to the script. The dataset consists of multiple large image files and must be streamed directly from its source.
You need to write code to define a ScriptRunConfig object for the experiment and pass the ds dataset as an argument.
Which code segment should you use?
- A . arguments = [‘–input-data’, ds.to_pandas_dataframe()]
- B . arguments = [‘–input-data’, ds.as_mount()]
- C . arguments = [‘–data-data’, ds]
- D . arguments = [‘–input-data’, ds.as_download()]
A
Explanation:
If you have structured data not yet registered as a dataset, create a TabularDataset and use it directly in your training script for your local or remote experiment.
To load the TabularDataset to pandas DataFrame
df = dataset.to_pandas_dataframe()
Note: TabularDataset represents data in a tabular format created by parsing the provided file or list of files.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-train-with-datasets
DRAG DROP
You are analyzing a raw dataset that requires cleaning.
You must perform transformations and manipulations by using Azure Machine Learning Studio.
You need to identify the correct modules to perform the transformations.
Which modules should you choose? To answer, drag the appropriate modules to the correct scenarios. Each module may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: Clean Missing Data
Box 2: SMOTE
Use the SMOTE module in Azure Machine Learning Studio to increase the number of underepresented cases in a dataset used for machine learning. SMOTE is a better way of increasing the number of rare cases than simply duplicating existing cases.
Box 3: Convert to Indicator Values
Use the Convert to Indicator Values module in Azure Machine Learning Studio. The purpose of this module is to convert columns that contain categorical values into a series of binary indicator columns that can more easily be used as features in a machine learning model.
Box 4: Remove Duplicate Rows
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/convert-to-indicator-values
DRAG DROP
You train and register a model by using the Azure Machine Learning SDK on a local workstation.
Python 3.6 and Visual Studio Code are installed on the workstation.
When you try to deploy the model into production as an Azure Kubernetes Service (AKS)-based web service, you experience an error in the scoring script that causes deployment to fail.
You need to debug the service on the local workstation before deploying the service to production.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


Explanation:
Step 1: Install Docker on the workstation
Prerequisites include having a working Docker installation on your local system.
Build or download the dockerfile to the compute node.
Step 2: Create an AksWebservice deployment configuration and deploy the model to it To deploy a model to Azure Kubernetes Service, create a deployment configuration that describes the compute resources needed.
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Step 3: Create a LocalWebservice deployment configuration for the service and deploy the model to it
To deploy locally, modify your code to use LocalWebservice.deploy_configuration() to create a deployment configuration. Then use Model.deploy() to deploy the service.
Step 4: Debug and modify the scoring script as necessary. Use the reload() method of the service after each modification.
During local testing, you may need to update the score.py file to add logging or attempt to resolve any problems that you’ve discovered. To reload changes to the score.py file, use reload(). For example, the following code reloads the script for the service, and then sends data to it.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-deploy-azure-kubernetes-service
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-troubleshoot-deployment-local
You use the Azure Machine Learning designer to create and run a training pipeline.
The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset.
You need to publish the pipeline as a REST service that can be used for the nightly inferencing run.
What should you do?
- A . Create a batch inference pipeline
- B . Set the compute target for the pipeline to an inference cluster
- C . Create a real-time inference pipeline
- D . Clone the pipeline
A
Explanation:
Azure Machine Learning Batch Inference targets large inference jobs that are not time-sensitive. Batch Inference provides cost-effective inference compute scaling, with unparalleled throughput for asynchronous applications. It is optimized for high-throughput, fire-and-forget inference over large collections of data.
You can submit a batch inference job by pipeline_run, or through REST calls with a published pipeline.
Reference: https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/machine-learning-pipelines/parallel-run/README.md
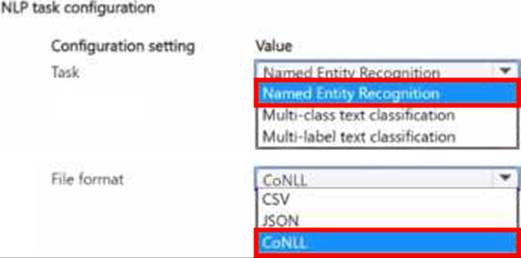
HOTSPOT
You manage an Azure Machine Learning workspace.
You plan to train a natural language processing (NLP) model that will assign labels ‘or designated tokens in unstructured text
You need to configure the NLP task by using automated machine learning.
Which configuration values should you use? To answer, select the appropriate options in the answer area.
NOTE Each correct selection is worth one point.