
Practice Free DP-100 Exam Online Questions
HOTSPOT
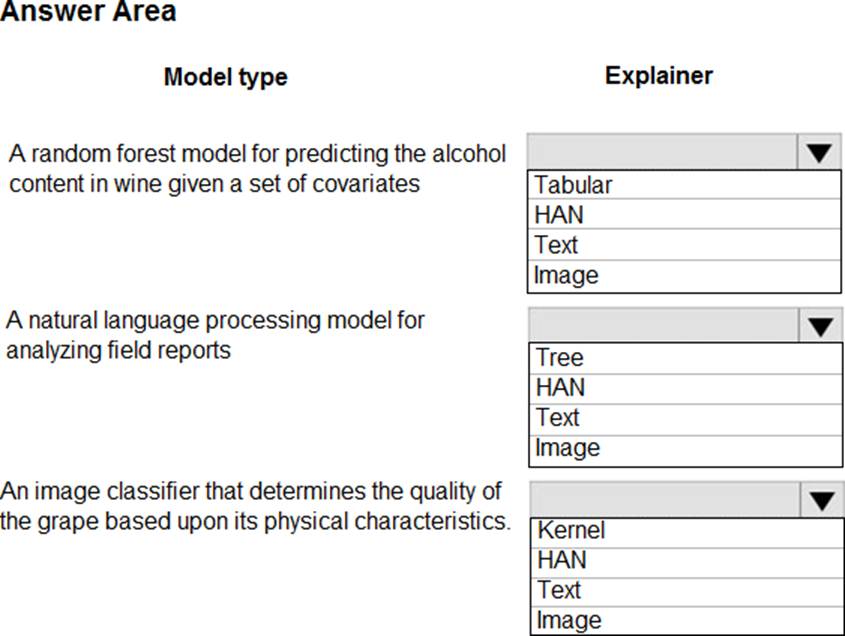
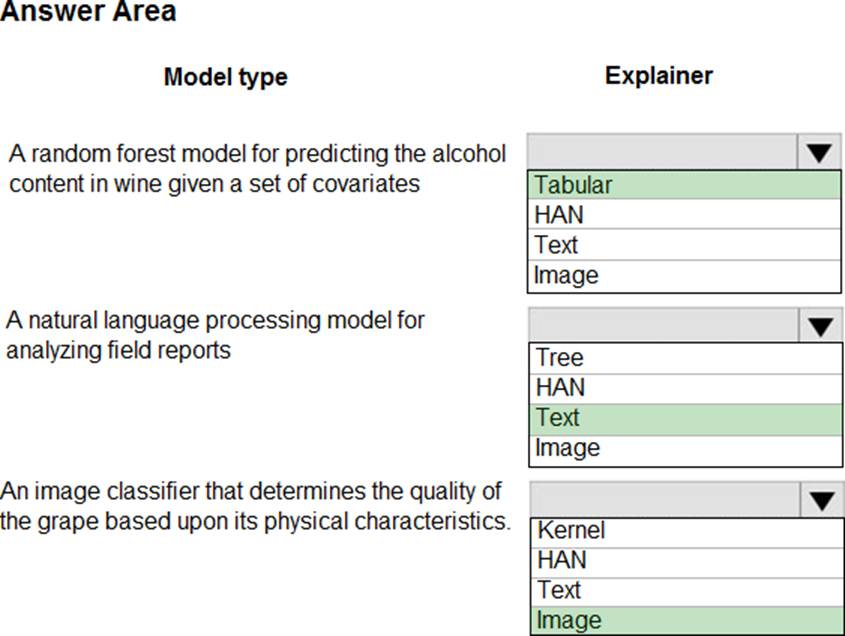
You are hired as a data scientist at a winery. The previous data scientist used Azure Machine Learning.
You need to review the models and explain how each model makes decisions.
Which explainer modules should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You are creating a compute target to train a machine learning experiment.
The compute target must support automated machine learning, machine learning pipelines, and Azure Machine Learning designer training.
You need to configure the compute target
Which option should you use?
- A . Azure HDInsight
- B . Azure Machine Learning compute cluster
- C . Azure Batch
- D . Remote VM
HOTSPOT
You collect data from a nearby weather station.
You have a pandas dataframe named weather_df that includes the following data:

The data is collected every 12 hours: noon and midnight.
You plan to use automated machine learning to create a time-series model that predicts temperature over the next seven days. For the initial round of training, you want to train a maximum of 50 different models.
You must use the Azure Machine Learning SDK to run an automated machine learning experiment to
train these models.
You need to configure the automated machine learning run.
How should you complete the AutoMLConfig definition? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


HOTSPOT
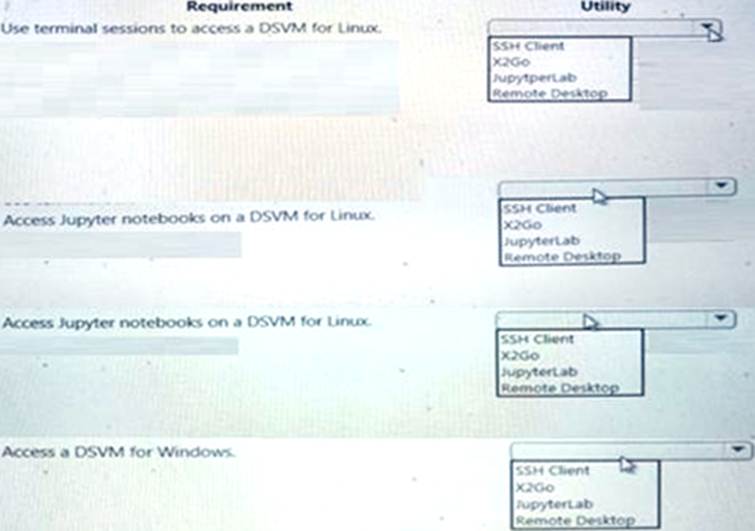
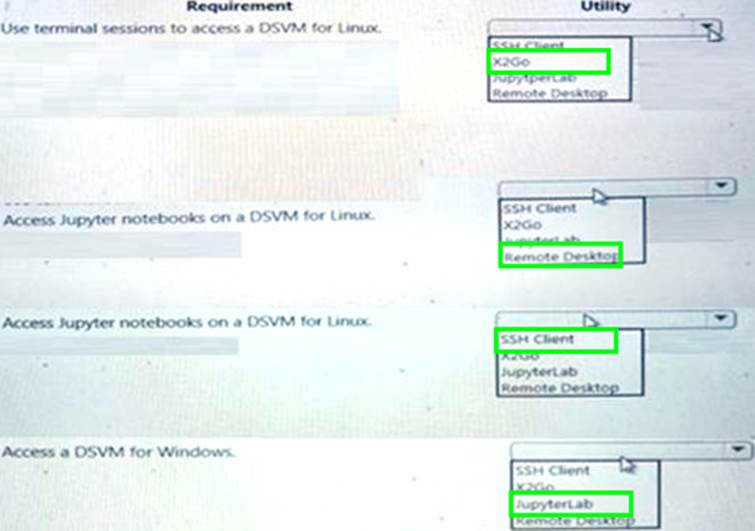
You use Data Science Virtual Machines (DSVMs) for Windows and Linux in Azure.
You need to access the DSVMs.
Which utilities should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Machine Learning workspace. You connect to a terminal session from the Notebooks page in Azure Machine Learning studio.
You plan to add a new Jupyter kernel that will be accessible from the same terminal session.
You need to perform the task that must be completed before you can add the new kernel.
Solution: Create an environment.
Does the solution meet the goal?
- A . Yes
- B . No
HOTSPOT
You are working on a classification task. You have a dataset indicating whether a student would like to play soccer and associated attributes.
The dataset includes the following columns:
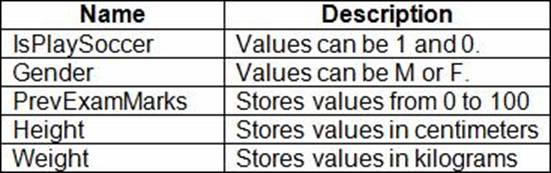
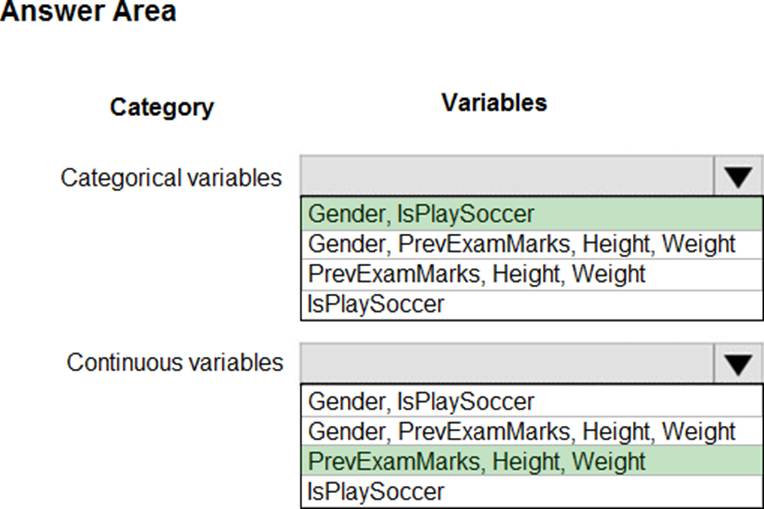
You need to classify variables by type.
Which variable should you add to each category? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Machine Learning workspace. You connect to a terminal session from the Notebooks page in Azure Machine Learning studio.
You plan to add a new Jupyter kernel that will be accessible from the same terminal session.
You need to perform the task that must be completed before you can add the new kernel.
Solution: Delete the Python 3.8 – AzureML kernel.
Does the solution meet the goal?
- A . Yes
- B . No
You register a file dataset named csvjolder that references a folder. The folder includes multiple com ma-separated values (CSV) files in an Azure storage blob container. You plan to use the following code to run a script that loads data from the file dataset.
You create and instantiate the following variables:

You have the following code:
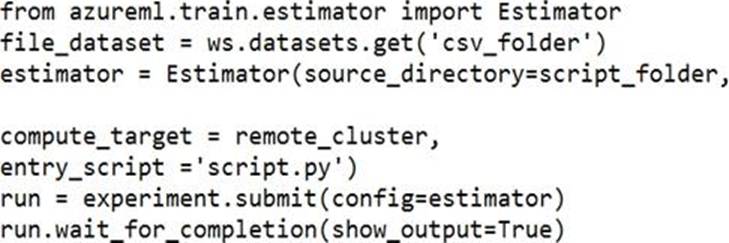
You need to pass the dataset to ensure that the script can read the files it references.
Which code segment should you insert to replace the code comment?
- A . inputs=[file_dataset.as_named_input(‘training_files’).to_pandas_dataframe()],
- B . inputs=[file_dataset.as_named_input(‘training_files’).as_mount()],
- C . script_params={‘–training_files’: file_dataset},
- D . inputs=[file_dataset.as_named_input(‘training_files’)],
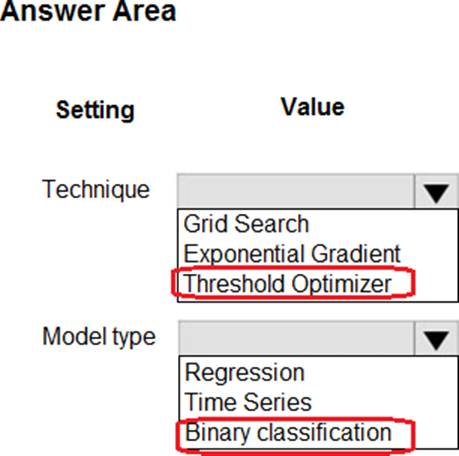
HOTSPOT
You have machine learning models produce unfair predictions across sensitive features.
You must use a post-processing technique to apply a constraint to the models to mitigate their unfairness.
You need to select a post-processing technique and model type.
What should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

You are evaluating a completed binary classification machine.
You need to use the precision as the evaluation metric.
Which visualization should you use?
- A . scatter plot
- B . coefficient of determination
- C . Receiver Operating Characteristic CROC) curve
- D . Gradient descent