
Practice Free DP-100 Exam Online Questions
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You use Azure Machine Learning designer to load the following datasets into an experiment:

You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Execute Python Script module.
Does the solution meet the goal?
- A . Yes
- B . No
You run a script as an experiment in Azure Machine Learning.
You have a Run object named run that references the experiment run. You must review the log files that were generated during the experiment run.
You need to download the log files to a local folder for review.
Which two code segments can you run to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . run.get_details()
- B . run.get_file_names()
- C . run.get_metrics()
- D . run.download_files(output_directory=’./runfiles’)
- E . run.get_all_logs(destination=’./runlogs’)
AE
Explanation:
The run Class get_all_logs method downloads all logs for the run to a directory.
The run Class get_details gets the definition, status information, current log files, and other details of the run.
Reference: https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.run(class)
You create a datastore named training_data that references a blob container in an Azure Storage account. The blob container contains a folder named csv_files in which multiple comma-separated values (CSV) files are stored.
You have a script named train.py in a local folder named ./script that you plan to run as an experiment using an estimator.
The script includes the following code to read data from the csv_files folder:

You have the following script.

You need to configure the estimator for the experiment so that the script can read the data from a data reference named data_ref that references the csv_files folder in the training_data datastore.
Which code should you use to configure the estimator?
A)

B)

C)

D)

E)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B
Explanation:
Besides passing the dataset through the inputs parameter in the estimator, you can also pass the dataset through script_params and get the data path (mounting point) in your training script via arguments. This way, you can keep your training script independent of azureml-sdk. In other words, you will be able use the same training script for local debugging and remote training on any cloud platform.
Example:
from azureml.train.sklearn import SKLearn
script_params = {
# mount the dataset on the remote compute and pass the mounted path as an argument to the training script
‘–data-folder’: mnist_ds.as_named_input(‘mnist’).as_mount(),
‘–regularization’: 0.5
}
est = SKLearn(source_directory=script_folder,
script_params=script_params,
compute_target=compute_target,
environment_definition=env,
entry_script=’train_mnist.py’)
# Run the experiment
run = experiment.submit(est)
run.wait_for_completion(show_output=True)
Incorrect Answers:
A: Pandas DataFrame not used.
Reference: https://docs.microsoft.com/es-es/azure/machine-learning/how-to-train-with-datasets
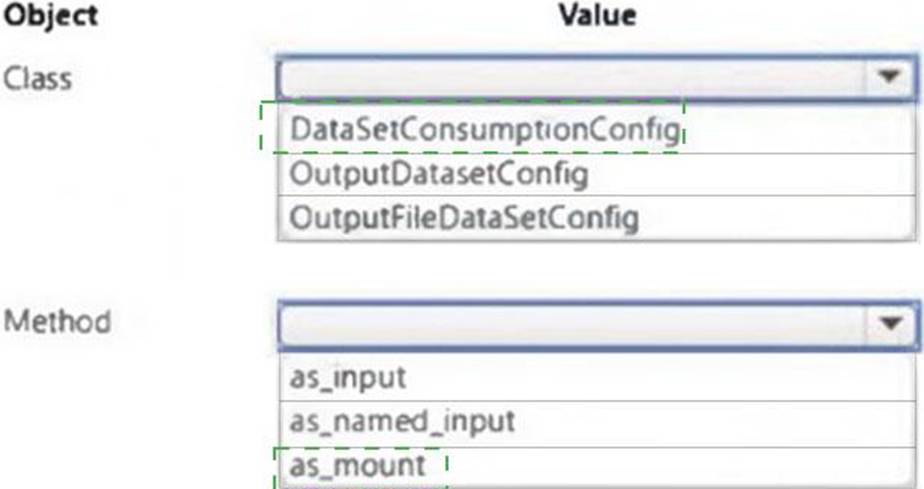
HOTSPOT
You plan to implement a two-step pipeline by using the Azure Machine Learning SDK for Python.
The pipeline will pass temporary data from the first step to the second step.
You need to identify the class and the corresponding method that should be used in the second step to access temporary data generated by the first step in the pipeline.
Which class and method should you identify? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point

HOTSPOT
You are using Azure Machine Learning to train machine learning models.
You need a compute target on which to remotely run the training script.
You run the following Python code:


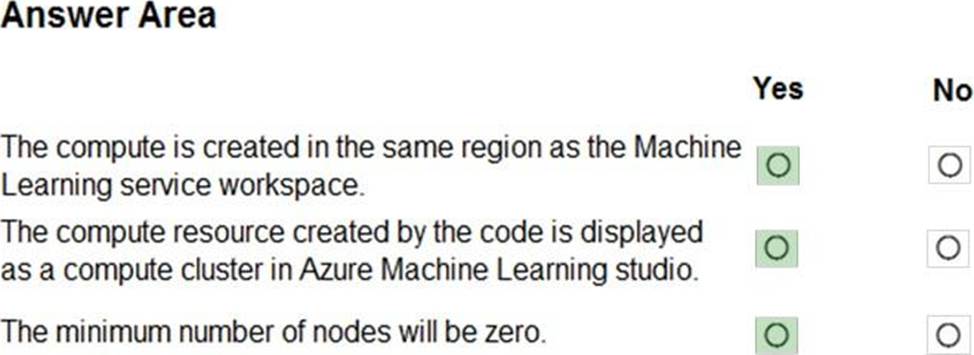
Explanation:
Box 1: Yes
The compute is created within your workspace region as a resource that can be shared with other users.
Box 2: Yes
It is displayed as a compute cluster.
View compute targets
HOTSPOT
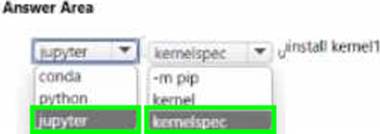
You manage an Azure Machine Learning workspace named workspace 1 with a compute instance named computet.
You must remove a kernel named kernel 1 from computet1. You connect to compute 1 by using noa terminal window from workspace 1.
You need to enter a command in the terminal window to remove kernel 1.
Which command should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection it worth one point.

HOTSPOT
You create an Azure Machine Learning workspace and a dataset. The dataset includes age values for a large group of diabetes patients. You use the dp.mean function from the SmartNoise library to calculate the mean of the age value. You store the value in a variable named age.mean.
You must output the value of the interval range of released mean values that will be returned 95 percent of the time.
You need to complete the code.
Which code values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

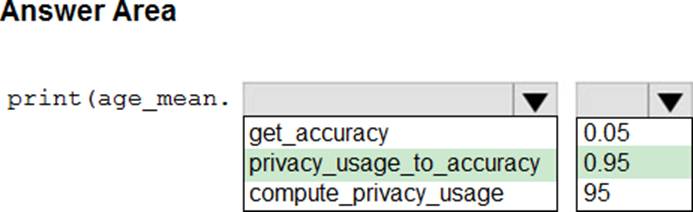
Explanation:
To complete the code to output the value of the interval range of released mean values that will be returned 95 percent of the time using the SmartNoise library, you would need to use the privacy_usage_to_accuracy method with a value of 0.95 for the interval percentage. The dp.mean function from the SmartNoise library can return this interval when the required methods and parameters are used correctly.
print(age_mean.privacy_usage_to_accuracy(0.95))
age_mean is the variable that holds the differentially private mean value calculated using the dp.mean function.
privacy_usage_to_accuracy(0.95) method is called on age_mean to get the interval range for 95% confidence.
Therefore, the selections should be:
privacy_usage_to_accuracy
DRAG DROP
You plan to explore demographic data for home ownership in various cities.
The data is in a CSV file with the following format:
age,city,income,home_owner
21, Chicago, 50000,0
35, Seattle, 120000,1
23, Seattle, 65000,0
45, Seattle, 130000,1
18, Chicago, 48000,0
You need to run an experiment in your Azure Machine Learning workspace to explore the data and log the results.
The experiment must log the following information:
✑ the number of observations in the dataset
✑ a box plot of income by home_owner
✑ a dictionary containing the city names and the average income for each city
You need to use the appropriate logging methods of the experiment’s run object to log the required information.
How should you complete the code? To answer, drag the appropriate code segments to the correct locations. Each code segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.

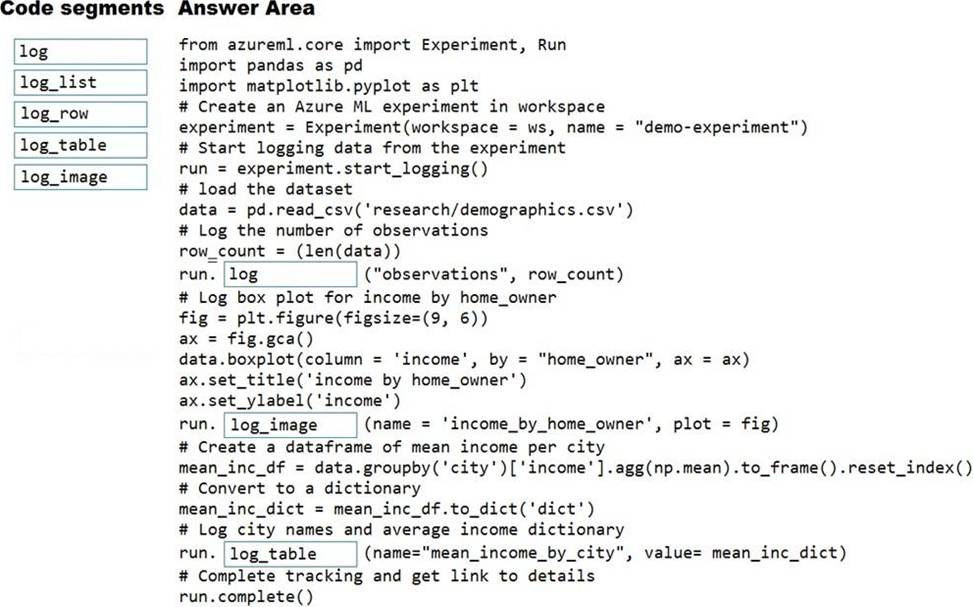
Explanation:
Box 1: log
The number of observations in the dataset.
run.log(name, value, description=”)
Scalar values: Log a numerical or string value to the run with the given name. Logging a metric to a run causes that metric to be stored in the run record in the experiment. You can log the same metric multiple times within a run, the result being considered a vector of that metric.
Example: run.log("accuracy", 0.95)
Box 2: log_image
A box plot of income by home_owner.
log_image Log an image to the run record. Use log_image to log a .PNG image file or a matplotlib plot to the run. These images will be visible and comparable in the run record.
Example: run.log_image("ROC", plot=plt)
Box 3: log_table
A dictionary containing the city names and the average income for each city.
log_table: Log a dictionary object to the run with the given name.
You deploy a real-time inference service for a trained model.
The deployed model supports a business-critical application, and it is important to be able to monitor the data submitted to the web service and the predictions the data generates.
You need to implement a monitoring solution for the deployed model using minimal administrative effort.
What should you do?
- A . View the explanations for the registered model in Azure ML studio.
- B . Enable Azure Application Insights for the service endpoint and view logged data in the Azure portal.
- C . Create an ML Flow tracking URI that references the endpoint, and view the data logged by ML Flow.
- D . View the log files generated by the experiment used to train the model.
B
Explanation:
Configure logging with Azure Machine Learning studio
You can also enable Azure Application Insights from Azure Machine Learning studio.
When you’re ready to deploy your model as a web service, use the following steps to enable Application Insights:
You plan to provision an Azure Machine Learning Basic edition workspace for a data science project.
You need to identify the tasks you will be able to perform in the workspace.
Which three tasks will you be able to perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . Create a Compute Instance and use it to run code in Jupyter notebooks.
- B . Create an Azure Kubernetes Service (AKS) inference cluster.
- C . Use the designer to train a model by dragging and dropping pre-defined modules.
- D . Create a tabular dataset that supports versioning.
- E . Use the Automated Machine Learning user interface to train a model.
ABD
Explanation:
Reference: https://azure.microsoft.com/en-us/pricing/details/machine-learning/