
Practice Free DP-100 Exam Online Questions
You create a binary classification model.
You need to evaluate the model performance.
Which two metrics can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . relative absolute error
- B . precision
- C . accuracy
- D . mean absolute error
- E . coefficient of determination
BC
Explanation:
The evaluation metrics available for binary classification models are: Accuracy, Precision, Recall, F1 Score, and AUC.
Note: A very natural question is: ‘Out of the individuals whom the model, how many were classified correctly (TP)?’
This question can be answered by looking at the Precision of the model, which is the proportion of positives that are classified correctly.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance
You create a binary classification model.
You need to evaluate the model performance.
Which two metrics can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . relative absolute error
- B . precision
- C . accuracy
- D . mean absolute error
- E . coefficient of determination
BC
Explanation:
The evaluation metrics available for binary classification models are: Accuracy, Precision, Recall, F1 Score, and AUC.
Note: A very natural question is: ‘Out of the individuals whom the model, how many were classified correctly (TP)?’
This question can be answered by looking at the Precision of the model, which is the proportion of positives that are classified correctly.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance
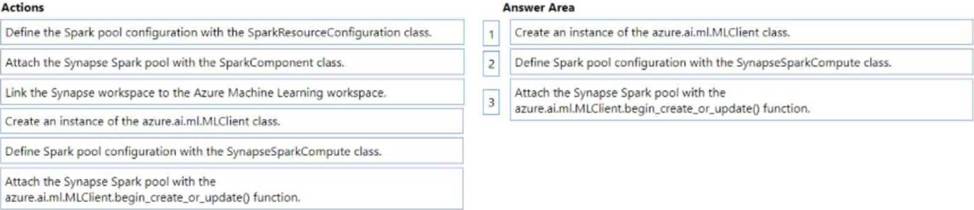
DRAG DROP
You create an Azure Machine Learning workspace and an Azure Synapse Analytics workspace with a Spark pool. The workspaces are contained within the same Azure subscription.
You must manage the Synapse Spark pool from the Azure Machine Learning workspace.
You need to attach the Synapse Spark pool in Azure Machine Learning by using the Python SDK v2.
Which three actions should you perform in sequence? To answer move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You create a Python script that runs a training experiment in Azure Machine Learning. The script uses the Azure Machine Learning SDK for Python.
You must add a statement that retrieves the names of the logs and outputs generated by the script.
You need to reference a Python class object from the SDK for the statement.
Which class object should you use?
- A . Run
- B . ScripcRunConfig
- C . Workspace
- D . Experiment
A
Explanation:
A run represents a single trial of an experiment. Runs are used to monitor the asynchronous execution of a trial, log metrics and store output of the trial, and to analyze results and access artifacts generated by the trial.
The run Class get_all_logs method downloads all logs for the run to a directory.
Reference: https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.run(class)
You develop and train a machine learning model to predict fraudulent transactions for a hotel booking website.
Traffic to the site varies considerably. The site experiences heavy traffic on Monday and Friday and much lower traffic on other days. Holidays are also high web traffic days. You need to deploy the model as an Azure Machine Learning real-time web service endpoint on compute that can dynamically scale up and down to support demand.
Which deployment compute option should you use?
- A . attached Azure Databricks cluster
- B . Azure Container Instance (ACI)
- C . Azure Kubernetes Service (AKS) inference cluster
- D . Azure Machine Learning Compute Instance
- E . attached virtual machine in a different region
E
Explanation:
Azure Machine Learning compute cluster is a managed-compute infrastructure that allows you to easily create a single or multi-node compute. The compute is created within your workspace region as a resource that can be shared with other users in your workspace. The compute scales up automatically when a job is submitted, and can be put in an Azure Virtual Network.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-attach-compute-sdk
HOTSPOT
You have a dataset that includes home sales data for a city.
The dataset includes the following columns.

Each row in the dataset corresponds to an individual home sales transaction.
You need to use automated machine learning to generate the best model for predicting the sales price based on the features of the house.
Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

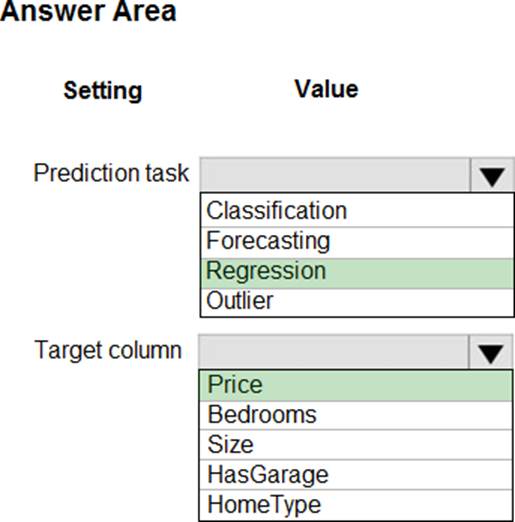
Explanation:
Box 1: Regression
Regression is a supervised machine learning technique used to predict numeric values.
Box 2: Price
Reference: https://docs.microsoft.com/en-us/learn/modules/create-regression-model-azure-machine-learning-designer
HOTSPOT
You are hired as a data scientist at a winery. The previous data scientist used Azure Machine Learning.
You need to review the models and explain how each model makes decisions.
Which explainer modules should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

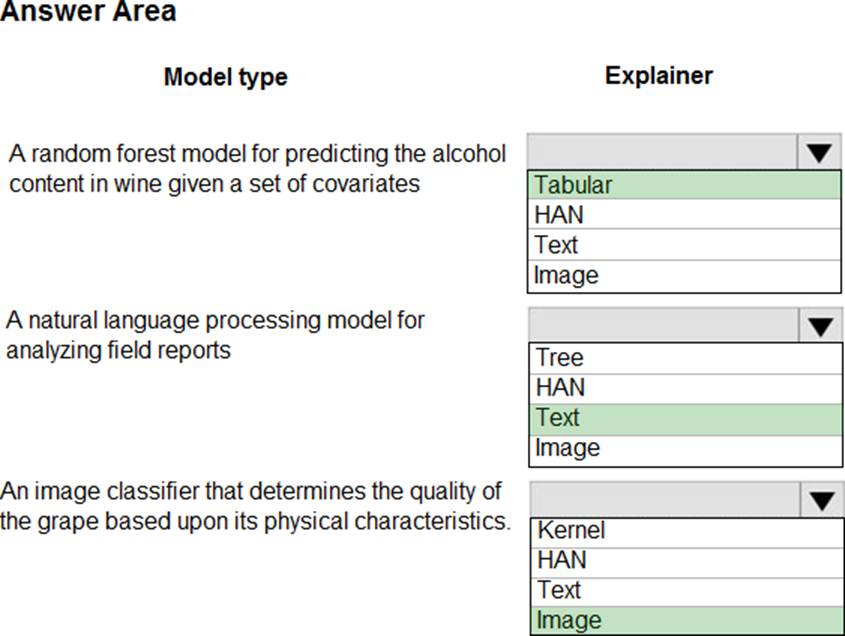
Explanation:
Meta explainers automatically select a suitable direct explainer and generate the best explanation info based on the given model and data sets. The meta explainers leverage all the libraries (SHAP, LIME, Mimic, etc.) that we have integrated or developed.
The following are the meta explainers available in the SDK:
Tabular Explainer: Used with tabular datasets.
Text Explainer: Used with text datasets.
Image Explainer: Used with image datasets.
Box 1: Tabular
Box 2: Text
Box 3: Image
Reference: https://medium.com/microsoftazure/automated-and-interpretable-machine-learning-d07975741298
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are creating a model to predict the price of a student’s artwork depending on the following variables: the student’s length of education, degree type, and art form.
You start by creating a linear regression model.
You need to evaluate the linear regression model.
Solution: Use the following metrics: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Relative Squared Error, and the Coefficient of Determination.
Does the solution meet the goal?
- A . Yes
- B . No
A
Explanation:
The following metrics are reported for evaluating regression models. When you compare models, they are ranked by the metric you select for evaluation.
Mean absolute error (MAE) measures how close the predictions are to the actual outcomes; thus, a lower score is better.
Root mean squared error (RMSE) creates a single value that summarizes the error in the model. By squaring the difference, the metric disregards the difference between over-prediction and under-prediction.
Relative absolute error (RAE) is the relative absolute difference between expected and actual values; relative because the mean difference is divided by the arithmetic mean.
Relative squared error (RSE) similarly normalizes the total squared error of the predicted values by dividing by the total squared error of the actual values.
Mean Zero One Error (MZOE) indicates whether the prediction was correct or not. In other words:
ZeroOneLoss(x,y) = 1 when x!=y; otherwise 0.
Coefficient of determination, often referred to as R2, represents the predictive power of the model as a value between 0 and 1. Zero means the model is random (explains nothing); 1 means there is a perfect fit. However, caution should be used in interpreting R2 values, as low values can be entirely normal and high values can be suspect.
AUC.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/evaluate-model
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
An IT department creates the following Azure resource groups and resources:

The IT department creates an Azure Kubernetes Service (AKS)-based inference compute target named aks-cluster in the Azure Machine Learning workspace. You have a Microsoft Surface Book computer with a GPU. Python 3.6 and Visual Studio Code are installed.
You need to run a script that trains a deep neural network (DNN) model and logs the loss and accuracy metrics.
Solution: Install the Azure ML SDK on the Surface Book. Run Python code to connect to the workspace. Run the training script as an experiment on the aks-cluster compute target.
Does the solution meet the goal?
- A . Yes
- B . No
B
Explanation:
Need to attach the mlvm virtual machine as a compute target in the Azure Machine Learning workspace.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/concept-compute-target
You have the following Azure subscriptions and Azure Machine Learning service workspaces:

You need to obtain a reference to the ml-project workspace.
Solution: Run the following Python code:
![]()
Does the solution meet the goal?
- A . Yes
- B . No