
Practice Free Databricks Certified Professional Data Engineer Exam Online Questions
The data engineering team has configured a job to process customer requests to be forgotten (have their data deleted). All user data that needs to be deleted is stored in Delta Lake tables using default table settings.
The team has decided to process all deletions from the previous week as a batch job at 1am each Sunday. The total duration of this job is less than one hour. Every Monday at 3am, a batch job executes a series of VACUUM commands on all Delta Lake tables throughout the organization.
The compliance officer has recently learned about Delta Lake’s time travel functionality. They are concerned that this might allow continued access to deleted data.
Assuming all delete logic is correctly implemented, which statement correctly addresses this concern?
- A . Because the vacuum command permanently deletes all files containing deleted records, deleted records may be accessible with time travel for around 24 hours.
- B . Because the default data retention threshold is 24 hours, data files containing deleted records will be retained until the vacuum job is run the following day.
- C . Because Delta Lake time travel provides full access to the entire history of a table, deleted records can always be recreated by users with full admin privileges.
- D . Because Delta Lake’s delete statements have ACID guarantees, deleted records will be permanently purged from all storage systems as soon as a delete job completes.
- E . Because the default data retention threshold is 7 days, data files containing deleted records will be retained until the vacuum job is run 8 days later.
E
Explanation:
https://learn.microsoft.com/en-us/azure/databricks/delta/vacuum
The marketing team is looking to share data in an aggregate table with the sales organization, but the field names used by the teams do not match, and a number of marketing specific fields have not been approval for the sales org.
Which of the following solutions addresses the situation while emphasizing simplicity?
- A . Create a view on the marketing table selecting only these fields approved for the sales team alias the names of any fields that should be standardized to the sales naming conventions.
- B . Use a CTAS statement to create a derivative table from the marketing table configure a production jon to propagation changes.
- C . Add a parallel table write to the current production pipeline, updating a new sales table that varies as required from marketing table.
- D . Create a new table with the required schema and use Delta Lake’s DEEP CLONE functionality to sync up changes committed to one table to the corresponding table.
A
Explanation:
Creating a view is a straightforward solution that can address the need for field name standardization and selective field sharing between departments. A view allows for presenting a transformed version of the underlying data without duplicating it. In this scenario, the view would only include the approved fields for the sales team and rename any fields as per their naming conventions.
Reference: Databricks documentation on using SQL views in Delta Lake:
https://docs.databricks.com/delta/quick-start.html#sql-views
In order to facilitate near real-time workloads, a data engineer is creating a helper function to leverage the schema detection and evolution functionality of Databricks Auto Loader. The desired function will automatically detect the schema of the source directly, incrementally process JSON files as they arrive in a source directory, and automatically evolve the schema of the table when new fields are detected.
The function is displayed below with a blank:
Which response correctly fills in the blank to meet the specified requirements?
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B
Explanation:
Option B correctly fills in the blank to meet the specified requirements. Option B uses the “cloudFiles.schemaLocation” option, which is required for the schema detection and evolution functionality of Databricks Auto Loader. Additionally, option B uses the “mergeSchema” option, which is required for the schema evolution functionality of Databricks Auto Loader. Finally, option B uses the “writeStream” method, which is required for the incremental processing of JSON files as they arrive in a source directory. The other options are incorrect because they either omit the required options, use the wrong method, or use the wrong format.
Reference: Configure schema inference and evolution in Auto Loader:
https://docs.databricks.com/en/ingestion/auto-loader/schema.html
Write streaming data: https://docs.databricks.com/spark/latest/structured-streaming/writing-streaming-data.html
The data science team has created and logged a production model using MLflow. The following code correctly imports and applies the production model to output the predictions as a new DataFrame named preds with the schema "customer_id LONG, predictions DOUBLE, date DATE".
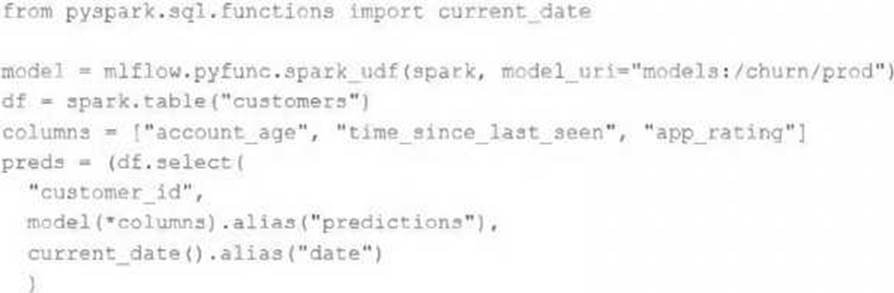
The data science team would like predictions saved to a Delta Lake table with the ability to compare all predictions across time. Churn predictions will be made at most once per day.
Which code block accomplishes this task while minimizing potential compute costs?
A) preds.write.mode("append").saveAsTable("churn_preds")
B) preds.write.format("delta").save("/preds/churn_preds")
C)

D)

E)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
Where in the Spark UI can one diagnose a performance problem induced by not leveraging predicate push-down?
- A . In the Executor’s log file, by gripping for "predicate push-down"
- B . In the Stage’s Detail screen, in the Completed Stages table, by noting the size of data read from the Input column
- C . In the Storage Detail screen, by noting which RDDs are not stored on disk
- D . In the Delta Lake transaction log. by noting the column statistics
- E . In the Query Detail screen, by interpreting the Physical Plan
E
Explanation:
This is the correct answer because it is where in the Spark UI one can diagnose a performance problem induced by not leveraging predicate push-down. Predicate push-down is an optimization technique that allows filtering data at the source before loading it into memory or processing it further. This can improve performance and reduce I/O costs by avoiding reading unnecessary data. To leverage predicate push-down, one should use supported data sources and formats, such as Delta Lake, Parquet, or JDBC, and use filter expressions that can be pushed down to the source. To diagnose a performance problem induced by not leveraging predicate push-down, one can use the Spark UI to access the Query Detail screen, which shows information about a SQL query executed on a Spark cluster. The Query Detail screen includes the Physical Plan, which is the actual plan executed by Spark to perform the query. The Physical Plan shows the physical operators used by Spark, such as Scan, Filter, Project, or Aggregate, and their input and output statistics, such as rows and bytes. By interpreting the Physical Plan, one can see if the filter expressions are pushed down to the source or not, and how much data is read or processed by each operator.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Spark Core” section; Databricks Documentation, under “Predicate pushdown” section; Databricks Documentation, under “Query detail page” section.
The data engineering team maintains the following code:
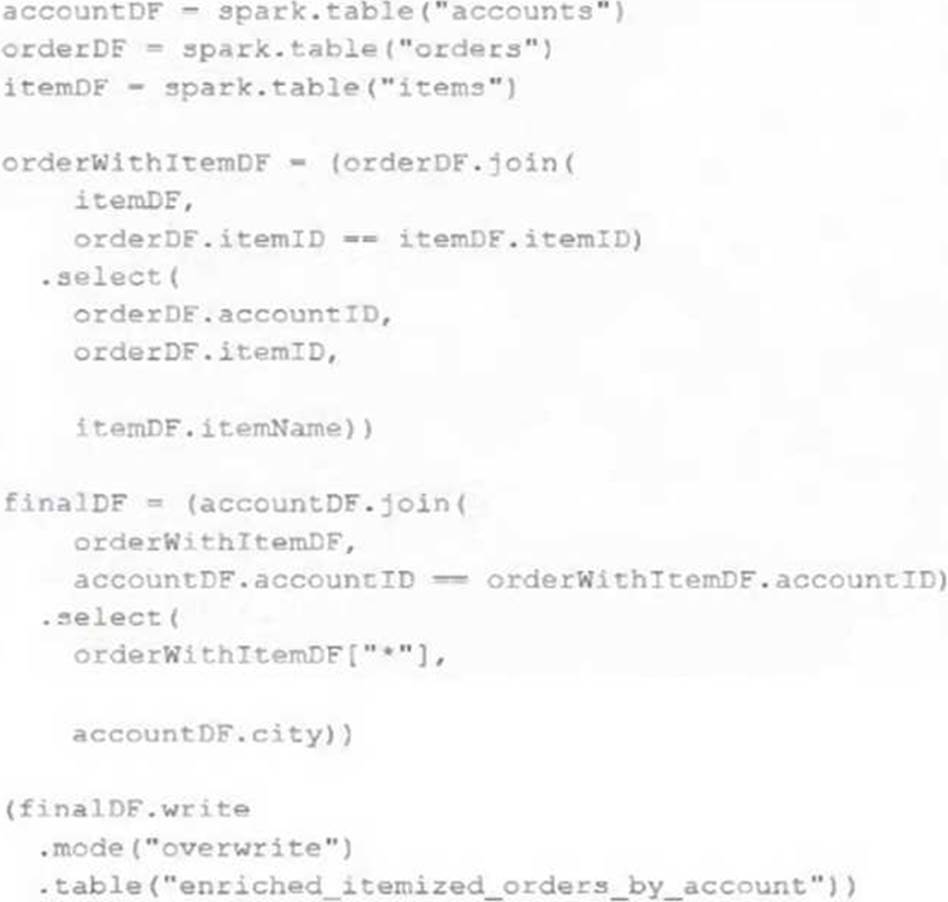
Assuming that this code produces logically correct results and the data in the source tables has been de-duplicated and validated, which statement describes what will occur when this code is executed?
- A . A batch job will update the enriched_itemized_orders_by_account table, replacing only those rows that have different values than the current version of the table, using accountID as the primary key.
- B . The enriched_itemized_orders_by_account table will be overwritten using the current valid version of data in each of the three tables referenced in the join logic.
- C . An incremental job will leverage information in the state store to identify unjoined rows in the source tables and write these rows to the enriched_iteinized_orders_by_account table.
- D . An incremental job will detect if new rows have been written to any of the source tables; if new rows are detected, all results will be recalculated and used to overwrite the enriched_itemized_orders_by_account table.
- E . No computation will occur until enriched_itemized_orders_by_account is queried; upon query materialization, results will be calculated using the current valid version of data in each of the three tables referenced in the join logic.
B
Explanation:
This is the correct answer because it describes what will occur when this code is executed. The code
uses three Delta Lake tables as input sources: accounts, orders, and order_items. These tables are
joined together using SQL queries to create a view called new_enriched_itemized_orders_by_account, which contains information about each order item and its associated account details. Then, the code uses write.format(“delta”).mode(“overwrite”) to overwrite a target table called enriched_itemized_orders_by_account using the data from the view.
This means that every time this code is executed, it will replace all existing data in the target table with new data based on the current valid version of data in each of the three input tables.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks
Documentation, under “Write to Delta tables” section.
A table named user_ltv is being used to create a view that will be used by data analysis on various teams. Users in the workspace are configured into groups, which are used for setting up data access using ACLs.
The user_ltv table has the following schema:

An analyze who is not a member of the auditing group executing the following query:
![]()
Which result will be returned by this query?
- A . All columns will be displayed normally for those records that have an age greater than 18; records not meeting this condition will be omitted.
- B . All columns will be displayed normally for those records that have an age greater than 17; records not meeting this condition will be omitted.
- C . All age values less than 18 will be returned as null values all other columns will be returned with the values in user_ltv.
- D . All records from all columns will be displayed with the values in user_ltv.
A
Explanation:
Given the CASE statement in the view definition, the result set for a user not in the auditing group would be constrained by the ELSE condition, which filters out records based on age. Therefore, the view will return all columns normally for records with an age greater than 18, as users who are not in the auditing group will not satisfy the is_member(‘auditing’) condition. Records not meeting the age > 18 condition will not be displayed.