
Practice Free Databricks Certified Professional Data Engineer Exam Online Questions
An hourly batch job is configured to ingest data files from a cloud object storage container where each batch represent all records produced by the source system in a given hour. The batch job to process these records into the Lakehouse is sufficiently delayed to ensure no late-arriving data is missed.
The user_id field represents a unique key for the data, which has the following schema:
user_id BIGINT, username STRING, user_utc STRING, user_region STRING, last_login BIGINT, auto_pay BOOLEAN, last_updated BIGINT
New records are all ingested into a table named account_history which maintains a full record of all data in the same schema as the source. The next table in the system is named account_current and is implemented as a Type 1 table representing the most recent value for each unique user_id.
Assuming there are millions of user accounts and tens of thousands of records processed hourly, which implementation can be used to efficiently update the described account_current table as part of each hourly batch job?
- A . Use Auto Loader to subscribe to new files in the account history directory; configure a Structured Streaminq trigger once job to batch update newly detected files into the account current table.
- B . Overwrite the account current table with each batch using the results of a query against the account history table grouping by user id and filtering for the max value of last updated.
- C . Filter records in account history using the last updated field and the most recent hour processed, as well as the max last iogin by user id write a merge statement to update or insert the most recent
value for each user id. - D . Use Delta Lake version history to get the difference between the latest version of account history and one version prior, then write these records to account current.
- E . Filter records in account history using the last updated field and the most recent hour processed, making sure to deduplicate on username; write a merge statement to update or insert the most recent value for each username.
C
Explanation:
This is the correct answer because it efficiently updates the account current table with only the most recent value for each user id. The code filters records in account history using the last updated field and the most recent hour processed, which means it will only process the latest batch of data. It also filters by the max last login by user id, which means it will only keep the most recent record for each user id within that batch. Then, it writes a merge statement to update or insert the most recent value for each user id into account current, which means it will perform an upsert operation based on the user id column.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks Documentation, under “Upsert into a table using merge” section.
A Delta Lake table was created with the below query:
Realizing that the original query had a typographical error, the below code was executed:
ALTER TABLE prod.sales_by_stor RENAME TO prod.sales_by_store
Which result will occur after running the second command?
- A . The table reference in the metastore is updated and no data is changed.
- B . The table name change is recorded in the Delta transaction log.
- C . All related files and metadata are dropped and recreated in a single ACID transaction.
- D . The table reference in the metastore is updated and all data files are moved.
- E . A new Delta transaction log Is created for the renamed table.
A
Explanation:
The query uses the CREATE TABLE USING DELTA syntax to create a Delta Lake table from an existing Parquet file stored in DBFS. The query also uses the LOCATION keyword to specify the path to the Parquet file as /mnt/finance_eda_bucket/tx_sales.parquet. By using the LOCATION keyword, the query creates an external table, which is a table that is stored outside of the default warehouse directory and whose metadata is not managed by Databricks. An external table can be created from an existing directory in a cloud storage system, such as DBFS or S3, that contains data files in a supported format, such as Parquet or CSV.
The result that will occur after running the second command is that the table reference in the metastore is updated and no data is changed. The metastore is a service that stores metadata about tables, such as their schema, location, properties, and partitions. The metastore allows users to access tables using SQL commands or Spark APIs without knowing their physical location or format. When renaming an external table using the ALTER TABLE RENAME TO command, only the table reference in the metastore is updated with the new name; no data files or directories are moved or changed in the storage system. The table will still point to the same location and use the same format as before. However, if renaming a managed table, which is a table whose metadata and data are both managed by Databricks, both the table reference in the metastore and the data files in the default warehouse directory are moved and renamed accordingly.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks Documentation, under “ALTER TABLE RENAME TO” section; Databricks Documentation, under “Metastore” section; Databricks Documentation, under “Managed and external tables” section.
Which distribution does Databricks support for installing custom Python code packages?
- A . sbt
- B . CRAN
- C . CRAM
- D . nom
- E . Wheels
- F . jars
The following table consists of items found in user carts within an e-commerce website.

The following MERGE statement is used to update this table using an updates view, with schema evaluation enabled on this table.
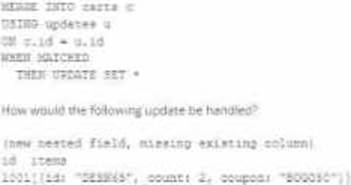
How would the following update be handled?
- A . The update is moved to separate ”restored” column because it is missing a column expected in the target schema.
- B . The new restored field is added to the target schema, and dynamically read as NULL for existing unmatched records.
- C . The update throws an error because changes to existing columns in the target schema are not supported.
- D . The new nested field is added to the target schema, and files underlying existing records are updated to include NULL values for the new field.
D
Explanation:
With schema evolution enabled in Databricks Delta tables, when a new field is added to a record through a MERGE operation, Databricks automatically modifies the table schema to include the new field. In existing records where this new field is not present, Databricks will insert NULL values for that field. This ensures that the schema remains consistent across all records in the table, with the new field being present in every record, even if it is NULL for records that did not originally include it.
Reference: Databricks documentation on schema evolution in Delta Lake:
https://docs.databricks.com/delta/delta-batch.html#schema-evolution
A Delta Lake table was created with the below query:
Consider the following query:
DROP TABLE prod.sales_by_store –
If this statement is executed by a workspace admin, which result will occur?
- A . Nothing will occur until a COMMIT command is executed.
- B . The table will be removed from the catalog but the data will remain in storage.
- C . The table will be removed from the catalog and the data will be deleted.
- D . An error will occur because Delta Lake prevents the deletion of production data.
- E . Data will be marked as deleted but still recoverable with Time Travel.
C
Explanation:
When a table is dropped in Delta Lake, the table is removed from the catalog and the data is deleted.
This is because Delta Lake is a transactional storage layer that provides ACID guarantees. When a
table is dropped, the transaction log is updated to reflect the deletion of the table and the data is
deleted from the underlying storage.
Reference: https://docs.databricks.com/delta/quick-start.html#drop-a-table
https://docs.databricks.com/delta/delta-batch.html#drop-table
A junior data engineer has manually configured a series of jobs using the Databricks Jobs UI. Upon reviewing their work, the engineer realizes that they are listed as the "Owner" for each job. They attempt to transfer "Owner" privileges to the "DevOps" group, but cannot successfully accomplish this task.
Which statement explains what is preventing this privilege transfer?
- A . Databricks jobs must have exactly one owner; "Owner" privileges cannot be assigned to a group.
- B . The creator of a Databricks job will always have "Owner" privileges; this configuration cannot be changed.
- C . Other than the default "admins" group, only individual users can be granted privileges on jobs.
- D . A user can only transfer job ownership to a group if they are also a member of that group.
- E . Only workspace administrators can grant "Owner" privileges to a group.
E
Explanation:
The reason why the junior data engineer cannot transfer “Owner” privileges to the “DevOps” group is that Databricks jobs must have exactly one owner, and the owner must be an individual user, not a group. A job cannot have more than one owner, and a job cannot have a group as an owner. The owner of a job is the user who created the job, or the user who was assigned the ownership by another user. The owner of a job has the highest level of permission on the job, and can grant or revoke permissions to other users or groups. However, the owner cannot transfer the ownership to a group, only to another user. Therefore, the junior data engineer’s attempt to transfer “Owner” privileges to the “DevOps” group is not possible.
Reference: Jobs access control: https://docs.databricks.com/security/access-control/table-acls/index.html
Job permissions: https://docs.databricks.com/security/access-control/table-acls/privileges.html#job-permissions
What statement is true regarding the retention of job run history?
- A . It is retained until you export or delete job run logs
- B . It is retained for 30 days, during which time you can deliver job run logs to DBFS or S3
- C . t is retained for 60 days, during which you can export notebook run results to HTML
- D . It is retained for 60 days, after which logs are archived
- E . It is retained for 90 days or until the run-id is re-used through custom run configuration
The downstream consumers of a Delta Lake table have been complaining about data quality issues impacting performance in their applications. Specifically, they have complained that invalid latitude and longitude values in the activity_details table have been breaking their ability to use other geolocation processes.
A junior engineer has written the following code to add CHECK constraints to the Delta Lake table:

A senior engineer has confirmed the above logic is correct and the valid ranges for latitude and longitude are provided, but the code fails when executed.
Which statement explains the cause of this failure?
- A . Because another team uses this table to support a frequently running application, two-phase locking is preventing the operation from committing.
- B . The activity details table already exists; CHECK constraints can only be added during initial table creation.
- C . The activity details table already contains records that violate the constraints; all existing data must pass CHECK constraints in order to add them to an existing table.
- D . The activity details table already contains records; CHECK constraints can only be added prior to inserting values into a table.
- E . The current table schema does not contain the field valid coordinates; schema evolution will need to be enabled before altering the table to add a constraint.
C
Explanation:
The failure is that the code to add CHECK constraints to the Delta Lake table fails when executed. The code uses ALTER TABLE ADD CONSTRAINT commands to add two CHECK constraints to a table named activity_details. The first constraint checks if the latitude value is between -90 and 90, and the second constraint checks if the longitude value is between -180 and 180. The cause of this failure is that the activity_details table already contains records that violate these constraints, meaning that they have invalid latitude or longitude values outside of these ranges. When adding CHECK constraints to an existing table, Delta Lake verifies that all existing data satisfies the constraints before adding them to the table. If any record violates the constraints, Delta Lake throws an exception and aborts the operation.
Verified Reference: [Databricks Certified Data Engineer
Professional], under “Delta Lake” section; Databricks Documentation, under “Add a CHECK constraint
to an existing table” section.
https://docs.databricks.com/en/sql/language-manual/sql-ref-syntax-ddl-alter-table.html#add-
constraint
When evaluating the Ganglia Metrics for a given cluster with 3 executor nodes, which indicator would signal proper utilization of the VM’s resources?
- A . The five Minute Load Average remains consistent/flat
- B . Bytes Received never exceeds 80 million bytes per second
- C . Network I/O never spikes
- D . Total Disk Space remains constant
- E . CPU Utilization is around 75%
E
Explanation:
In the context of cluster performance and resource utilization, a CPU utilization rate of around 75% is generally considered a good indicator of efficient resource usage. This level of CPU utilization suggests that the cluster is being effectively used without being overburdened or underutilized.
A consistent 75% CPU utilization indicates that the cluster’s processing power is being effectively employed while leaving some headroom to handle spikes in workload or additional tasks without maxing out the CPU, which could lead to performance degradation.
A five Minute Load Average that remains consistent/flat (Option A) might indicate underutilization or a bottleneck elsewhere.
Monitoring network I/O (Options B and C) is important, but these metrics alone don’t provide a complete picture of resource utilization efficiency.
Total Disk Space (Option D) remaining constant is not necessarily an indicator of proper resource utilization, as it’s more related to storage rather than computational efficiency.
Reference: Ganglia Monitoring System: Ganglia Documentation
Databricks Documentation on Monitoring: Databricks Cluster Monitoring
Which statement describes Delta Lake Auto Compaction?
- A . An asynchronous job runs after the write completes to detect if files could be further compacted;
if yes, an optimize job is executed toward a default of 1 GB. - B . Before a Jobs cluster terminates, optimize is executed on all tables modified during the most recent job.
- C . Optimized writes use logical partitions instead of directory partitions; because partition boundaries are only represented in metadata, fewer small files are written.
- D . Data is queued in a messaging bus instead of committing data directly to memory; all data is committed from the messaging bus in one batch once the job is complete.
- E . An asynchronous job runs after the write completes to detect if files could be further compacted; if yes, an optimize job is executed toward a default of 128 MB.
E
Explanation:
This is the correct answer because it describes the behavior of Delta Lake Auto Compaction, which is a feature that automatically optimizes the layout of Delta Lake tables by coalescing small files into larger ones. Auto Compaction runs as an asynchronous job after a write to a table has succeeded and checks if files within a partition can be further compacted. If yes, it runs an optimize job with a default target file size of 128 MB. Auto Compaction only compacts files that have not been compacted previously.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks Documentation, under “Auto Compaction for Delta Lake on Databricks” section.
"Auto compaction occurs after a write to a table has succeeded and runs synchronously on the cluster that has performed the write. Auto compaction only compacts files that haven’t been compacted previously."
https://learn.microsoft.com/en-us/azure/databricks/delta/tune-file-size