
Practice Free A00-408 Exam Online Questions
Given the exhibit below taken from the Topics node, which statements are true? (Choose 2)
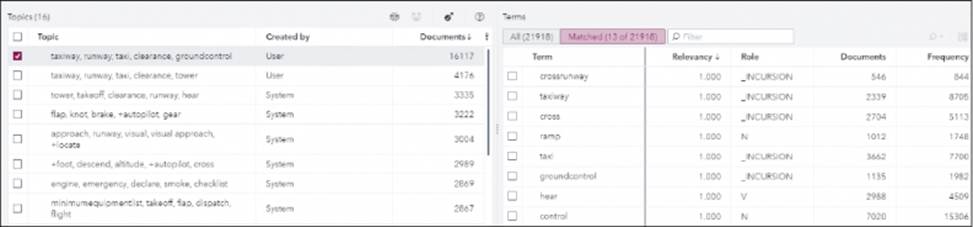
- A . All terms have a Relevancy of 1 because the selected topic is a user created topic.
- B . The selected topic appears in 13 documents.
- C . There are 21,918 kept terms that will be used in the analysis.
- D . The selected topic has been promoted to a Category.
Which AddLayer statement specifies the input layer to load an RGB image with dimensions of 256 x 256?
- A . AddLayer / model=’ConVNN’ name=’data’ layer={type=’input’ nchannels=3 dim=256};
- B . AddLayer / model=’ConVNN’ name=’data’ layer={type=’input’ nchannels=3 width=256 height=256};
- C . AddLayer / model=’ConVNN’ name=’data’ layer={type=’input’ nchannels=1 dim=256};
- D . AddLayer / model=’ConVNN’ name=’data’ layer={type=’input’ nchannels=1 width=256 height=256};
How many feature maps are output by the convolutional layer specified in the following code?
deepLearn.addLayer / layer={type=”CONVO”
nFilters=10 width=3 height=3 stride=1}
modelTable={name=”simple”}
name=”conv”
srcLayers={“data”};
- A . 10
- B . 90
- C . 17
- D . 30
Which of the following are capabilities of the image action set? (Choose 2)
- A . It can display images once they’ve been uploaded into a CAS Table.
- B . It can display all CAS Tables that contain images that are in memory.
- C . It can mutate images via rotations, flips, color jitters, and more.
- D . It can train deep learning models using CAS Tables that contain images.
Which statement is TRUE regarding encoding?
- A . Latin encoding is an extension of ASCII encoding with specific extensions.
- B . Asian languages (i.e. Japanese) are typically encoded in ASCII.
- C . UTF-8 is a subset of ASCII encoding.
- D . A UTF-8 character is 4 bytes long.
Which statement regarding convolutional layers best explains why these models help classify images in a variety of orientations?
- A . The filters have a width and a height.
- B . They are equivariant to translation.
- C . A network can have multiple convolutional layers.
- D . They capture edges.
Given the code specifying the two initial layers of a convolutional network:
deepLearn.addLayer / layer={type=”INPUT”
nchannels=1 width=10 height=10}
modelTable={name=”simple”}
name=”data”;
deepLearn.addLayer / layer={type=”CONVO”
nFilters=1 width=5 height=5 stride=1}
modelTable={name=”simple”}
name=”conv1”
srcLayers={“data”};
Which of the following statements describes the output tensor (image) of conv1?
- A . The output tensor will be larger in width and height than the input data tensor.
- B . The output tensor dimensions cannot be determined from the information above.
- C . The output tensor will be the same width and height as the input data tensor.
- D . The output tensor will be smaller in width and height than the input data tensor
Which of the following best describes a use for padding?
- A . Padding can be used to adjust the dimensions of a filter.
- B . Padding can help extract more information by adding more parameter estimates.
- C . Padding can help extract more information from the edges of images.
- D . Padding can help extract objects that tend to be in exact locations.
Given the category rule:
– (SENT,(OR,"mortgage","refinance",(NOTIN,"home","home
– equity")),"[InterestRateValue]")
Which document would NOT be selected based on the text strings in the answer options?
- A . I was able to refinance my home loan at a 4% interest rate last month.
- B . Currently 2.8%, the refinance interest rate was lower than the home equity line of credit rate.
- C . The refinance was lower than the original mortgage, which had an 8 percent rate.
- D . The current refinance home mortgage rate is 5%.
Which of the following is an advantage of using a rectified linear transformation (ReLU) activation function in a convolutional network?
- A . The output of the ReLU activation function is bounded above and thus ReLU never diverges
- B . The gradient of the ReLU activation function is always 0 or 1 and is thus computationally easy to calculate
- C . The ReLU activation function has no saturation region and thus training never stalls
- D . The ReLU activation function allows parallelization of the training process thus speeding training